Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
ResNet50_tensorflow
Commits
f673f7a8
Unverified
Commit
f673f7a8
authored
Jan 29, 2020
by
Hongkun Yu
Committed by
GitHub
Jan 29, 2020
Browse files
remove research/resnet (#8093)
parent
3e12ad2b
Changes
7
Hide whitespace changes
Inline
Side-by-side
Showing
7 changed files
with
0 additions
and
778 deletions
+0
-778
research/resnet/BUILD
research/resnet/BUILD
+0
-40
research/resnet/README.md
research/resnet/README.md
+0
-109
research/resnet/cifar_input.py
research/resnet/cifar_input.py
+0
-115
research/resnet/g3doc/cifar_resnet.gif
research/resnet/g3doc/cifar_resnet.gif
+0
-0
research/resnet/g3doc/cifar_resnet_legends.gif
research/resnet/g3doc/cifar_resnet_legends.gif
+0
-0
research/resnet/resnet_main.py
research/resnet/resnet_main.py
+0
-212
research/resnet/resnet_model.py
research/resnet/resnet_model.py
+0
-302
No files found.
research/resnet/BUILD
deleted
100644 → 0
View file @
3e12ad2b
package
(
default_visibility
=
[
":internal"
])
licenses
([
"notice"
])
# Apache 2.0
exports_files
([
"LICENSE"
])
package_group
(
name
=
"internal"
,
packages
=
[
"//resnet/..."
,
],
)
filegroup
(
name
=
"py_srcs"
,
data
=
glob
([
"**/*.py"
,
]),
)
py_library
(
name
=
"resnet_model"
,
srcs
=
[
"resnet_model.py"
],
)
py_binary
(
name
=
"resnet_main"
,
srcs
=
[
"resnet_main.py"
,
],
deps
=
[
":cifar_input"
,
":resnet_model"
,
],
)
py_library
(
name
=
"cifar_input"
,
srcs
=
[
"cifar_input.py"
],
)
research/resnet/README.md
deleted
100644 → 0
View file @
3e12ad2b
<font
size=
4
><b>
Reproduced ResNet on CIFAR-10 and CIFAR-100 dataset.
</b></font>
# Deprecated
This code is not actively maintained. Please use the
[
offical ResNet
](
https://github.com/tensorflow/models/tree/master/official/vision/image_classification
)
implementation
instead.
Xin Pan
<b>
Dataset:
</b>
https://www.cs.toronto.edu/~kriz/cifar.html
<b>
Related papers:
</b>
Identity Mappings in Deep Residual Networks
https://arxiv.org/pdf/1603.05027v2.pdf
Deep Residual Learning for Image Recognition
https://arxiv.org/pdf/1512.03385v1.pdf
Wide Residual Networks
https://arxiv.org/pdf/1605.07146v1.pdf
<b>
Settings:
</b>
*
Random split 50k training set into 45k/5k train/eval split.
*
Pad to 36x36 and random crop. Horizontal flip. Per-image whitening.
*
Momentum optimizer 0.9.
*
Learning rate schedule: 0.1 (40k), 0.01 (60k), 0.001 (>60k).
*
L2 weight decay: 0.002.
*
Batch size: 128. (28-10 wide and 1001 layer bottleneck use 64)
<b>
Results:
</b>


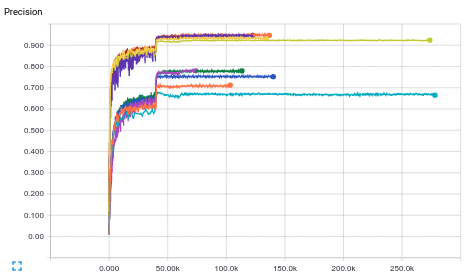
CIFAR-10 Model|Best Precision|Steps
--------------|--------------|------
32 layer|92.5%|~80k
110 layer|93.6%|~80k
164 layer bottleneck|94.5%|~80k
1001 layer bottleneck|94.9%|~80k
28-10 wide|95%|~90k
CIFAR-100 Model|Best Precision|Steps
---------------|--------------|-----
32 layer|68.1%|~45k
110 layer|71.3%|~60k
164 layer bottleneck|75.7%|~50k
1001 layer bottleneck|78.2%|~70k
28-10 wide|78.3%|~70k
<b>
Prerequisite:
</b>
1.
Install TensorFlow, Bazel.
2.
Download CIFAR-10/CIFAR-100 dataset.
```
shell
curl
-o
cifar-10-binary.tar.gz https://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz
curl
-o
cifar-100-binary.tar.gz https://www.cs.toronto.edu/~kriz/cifar-100-binary.tar.gz
```
<b>
How to run:
</b>
```
shell
# cd to the models repository and run with bash. Expected command output shown.
# The directory should contain an empty WORKSPACE file, the resnet code, and the cifar10 dataset.
# Note: The user can split 5k from train set for eval set.
$
ls
-R
.:
cifar10 resnet WORKSPACE
./cifar10:
data_batch_1.bin data_batch_2.bin data_batch_3.bin data_batch_4.bin
data_batch_5.bin test_batch.bin
./resnet:
BUILD cifar_input.py g3doc README.md resnet_main.py resnet_model.py
# Build everything for GPU.
$
bazel build
-c
opt
--config
=
cuda resnet/...
# Train the model.
$
bazel-bin/resnet/resnet_main
--train_data_path
=
cifar10/data_batch
*
\
--log_root
=
/tmp/resnet_model
\
--train_dir
=
/tmp/resnet_model/train
\
--dataset
=
'cifar10'
\
--num_gpus
=
1
# While the model is training, you can also check on its progress using tensorboard:
$
tensorboard
--logdir
=
/tmp/resnet_model
# Evaluate the model.
# Avoid running on the same GPU as the training job at the same time,
# otherwise, you might run out of memory.
$
bazel-bin/resnet/resnet_main
--eval_data_path
=
cifar10/test_batch.bin
\
--log_root
=
/tmp/resnet_model
\
--eval_dir
=
/tmp/resnet_model/test
\
--mode
=
eval
\
--dataset
=
'cifar10'
\
--num_gpus
=
0
```
research/resnet/cifar_input.py
deleted
100644 → 0
View file @
3e12ad2b
# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""CIFAR dataset input module.
"""
import
tensorflow
as
tf
def
build_input
(
dataset
,
data_path
,
batch_size
,
mode
):
"""Build CIFAR image and labels.
Args:
dataset: Either 'cifar10' or 'cifar100'.
data_path: Filename for data.
batch_size: Input batch size.
mode: Either 'train' or 'eval'.
Returns:
images: Batches of images. [batch_size, image_size, image_size, 3]
labels: Batches of labels. [batch_size, num_classes]
Raises:
ValueError: when the specified dataset is not supported.
"""
image_size
=
32
if
dataset
==
'cifar10'
:
label_bytes
=
1
label_offset
=
0
num_classes
=
10
elif
dataset
==
'cifar100'
:
label_bytes
=
1
label_offset
=
1
num_classes
=
100
else
:
raise
ValueError
(
'Not supported dataset %s'
,
dataset
)
depth
=
3
image_bytes
=
image_size
*
image_size
*
depth
record_bytes
=
label_bytes
+
label_offset
+
image_bytes
data_files
=
tf
.
gfile
.
Glob
(
data_path
)
file_queue
=
tf
.
train
.
string_input_producer
(
data_files
,
shuffle
=
True
)
# Read examples from files in the filename queue.
reader
=
tf
.
FixedLengthRecordReader
(
record_bytes
=
record_bytes
)
_
,
value
=
reader
.
read
(
file_queue
)
# Convert these examples to dense labels and processed images.
record
=
tf
.
reshape
(
tf
.
decode_raw
(
value
,
tf
.
uint8
),
[
record_bytes
])
label
=
tf
.
cast
(
tf
.
slice
(
record
,
[
label_offset
],
[
label_bytes
]),
tf
.
int32
)
# Convert from string to [depth * height * width] to [depth, height, width].
depth_major
=
tf
.
reshape
(
tf
.
slice
(
record
,
[
label_offset
+
label_bytes
],
[
image_bytes
]),
[
depth
,
image_size
,
image_size
])
# Convert from [depth, height, width] to [height, width, depth].
image
=
tf
.
cast
(
tf
.
transpose
(
depth_major
,
[
1
,
2
,
0
]),
tf
.
float32
)
if
mode
==
'train'
:
image
=
tf
.
image
.
resize_image_with_crop_or_pad
(
image
,
image_size
+
4
,
image_size
+
4
)
image
=
tf
.
random_crop
(
image
,
[
image_size
,
image_size
,
3
])
image
=
tf
.
image
.
random_flip_left_right
(
image
)
# Brightness/saturation/constrast provides small gains .2%~.5% on cifar.
# image = tf.image.random_brightness(image, max_delta=63. / 255.)
# image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
# image = tf.image.random_contrast(image, lower=0.2, upper=1.8)
image
=
tf
.
image
.
per_image_standardization
(
image
)
example_queue
=
tf
.
RandomShuffleQueue
(
capacity
=
16
*
batch_size
,
min_after_dequeue
=
8
*
batch_size
,
dtypes
=
[
tf
.
float32
,
tf
.
int32
],
shapes
=
[[
image_size
,
image_size
,
depth
],
[
1
]])
num_threads
=
16
else
:
image
=
tf
.
image
.
resize_image_with_crop_or_pad
(
image
,
image_size
,
image_size
)
image
=
tf
.
image
.
per_image_standardization
(
image
)
example_queue
=
tf
.
FIFOQueue
(
3
*
batch_size
,
dtypes
=
[
tf
.
float32
,
tf
.
int32
],
shapes
=
[[
image_size
,
image_size
,
depth
],
[
1
]])
num_threads
=
1
example_enqueue_op
=
example_queue
.
enqueue
([
image
,
label
])
tf
.
train
.
add_queue_runner
(
tf
.
train
.
queue_runner
.
QueueRunner
(
example_queue
,
[
example_enqueue_op
]
*
num_threads
))
# Read 'batch' labels + images from the example queue.
images
,
labels
=
example_queue
.
dequeue_many
(
batch_size
)
labels
=
tf
.
reshape
(
labels
,
[
batch_size
,
1
])
indices
=
tf
.
reshape
(
tf
.
range
(
0
,
batch_size
,
1
),
[
batch_size
,
1
])
labels
=
tf
.
sparse_to_dense
(
tf
.
concat
(
values
=
[
indices
,
labels
],
axis
=
1
),
[
batch_size
,
num_classes
],
1.0
,
0.0
)
assert
len
(
images
.
get_shape
())
==
4
assert
images
.
get_shape
()[
0
]
==
batch_size
assert
images
.
get_shape
()[
-
1
]
==
3
assert
len
(
labels
.
get_shape
())
==
2
assert
labels
.
get_shape
()[
0
]
==
batch_size
assert
labels
.
get_shape
()[
1
]
==
num_classes
# Display the training images in the visualizer.
tf
.
summary
.
image
(
'images'
,
images
)
return
images
,
labels
research/resnet/g3doc/cifar_resnet.gif
deleted
100644 → 0
View file @
3e12ad2b
14.2 KB
research/resnet/g3doc/cifar_resnet_legends.gif
deleted
100644 → 0
View file @
3e12ad2b
4.49 KB
research/resnet/resnet_main.py
deleted
100644 → 0
View file @
3e12ad2b
# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""ResNet Train/Eval module.
"""
import
time
import
six
import
sys
import
cifar_input
import
numpy
as
np
import
resnet_model
import
tensorflow
as
tf
FLAGS
=
tf
.
app
.
flags
.
FLAGS
tf
.
app
.
flags
.
DEFINE_string
(
'dataset'
,
'cifar10'
,
'cifar10 or cifar100.'
)
tf
.
app
.
flags
.
DEFINE_string
(
'mode'
,
'train'
,
'train or eval.'
)
tf
.
app
.
flags
.
DEFINE_string
(
'train_data_path'
,
''
,
'Filepattern for training data.'
)
tf
.
app
.
flags
.
DEFINE_string
(
'eval_data_path'
,
''
,
'Filepattern for eval data'
)
tf
.
app
.
flags
.
DEFINE_integer
(
'image_size'
,
32
,
'Image side length.'
)
tf
.
app
.
flags
.
DEFINE_string
(
'train_dir'
,
''
,
'Directory to keep training outputs.'
)
tf
.
app
.
flags
.
DEFINE_string
(
'eval_dir'
,
''
,
'Directory to keep eval outputs.'
)
tf
.
app
.
flags
.
DEFINE_integer
(
'eval_batch_count'
,
50
,
'Number of batches to eval.'
)
tf
.
app
.
flags
.
DEFINE_bool
(
'eval_once'
,
False
,
'Whether evaluate the model only once.'
)
tf
.
app
.
flags
.
DEFINE_string
(
'log_root'
,
''
,
'Directory to keep the checkpoints. Should be a '
'parent directory of FLAGS.train_dir/eval_dir.'
)
tf
.
app
.
flags
.
DEFINE_integer
(
'num_gpus'
,
0
,
'Number of gpus used for training. (0 or 1)'
)
def
train
(
hps
):
"""Training loop."""
images
,
labels
=
cifar_input
.
build_input
(
FLAGS
.
dataset
,
FLAGS
.
train_data_path
,
hps
.
batch_size
,
FLAGS
.
mode
)
model
=
resnet_model
.
ResNet
(
hps
,
images
,
labels
,
FLAGS
.
mode
)
model
.
build_graph
()
param_stats
=
tf
.
contrib
.
tfprof
.
model_analyzer
.
print_model_analysis
(
tf
.
get_default_graph
(),
tfprof_options
=
tf
.
contrib
.
tfprof
.
model_analyzer
.
TRAINABLE_VARS_PARAMS_STAT_OPTIONS
)
sys
.
stdout
.
write
(
'total_params: %d
\n
'
%
param_stats
.
total_parameters
)
tf
.
contrib
.
tfprof
.
model_analyzer
.
print_model_analysis
(
tf
.
get_default_graph
(),
tfprof_options
=
tf
.
contrib
.
tfprof
.
model_analyzer
.
FLOAT_OPS_OPTIONS
)
truth
=
tf
.
argmax
(
model
.
labels
,
axis
=
1
)
predictions
=
tf
.
argmax
(
model
.
predictions
,
axis
=
1
)
precision
=
tf
.
reduce_mean
(
tf
.
to_float
(
tf
.
equal
(
predictions
,
truth
)))
summary_hook
=
tf
.
train
.
SummarySaverHook
(
save_steps
=
100
,
output_dir
=
FLAGS
.
train_dir
,
summary_op
=
tf
.
summary
.
merge
([
model
.
summaries
,
tf
.
summary
.
scalar
(
'Precision'
,
precision
)]))
logging_hook
=
tf
.
train
.
LoggingTensorHook
(
tensors
=
{
'step'
:
model
.
global_step
,
'loss'
:
model
.
cost
,
'precision'
:
precision
},
every_n_iter
=
100
)
class
_LearningRateSetterHook
(
tf
.
train
.
SessionRunHook
):
"""Sets learning_rate based on global step."""
def
begin
(
self
):
self
.
_lrn_rate
=
0.1
def
before_run
(
self
,
run_context
):
return
tf
.
train
.
SessionRunArgs
(
model
.
global_step
,
# Asks for global step value.
feed_dict
=
{
model
.
lrn_rate
:
self
.
_lrn_rate
})
# Sets learning rate
def
after_run
(
self
,
run_context
,
run_values
):
train_step
=
run_values
.
results
if
train_step
<
40000
:
self
.
_lrn_rate
=
0.1
elif
train_step
<
60000
:
self
.
_lrn_rate
=
0.01
elif
train_step
<
80000
:
self
.
_lrn_rate
=
0.001
else
:
self
.
_lrn_rate
=
0.0001
with
tf
.
train
.
MonitoredTrainingSession
(
checkpoint_dir
=
FLAGS
.
log_root
,
hooks
=
[
logging_hook
,
_LearningRateSetterHook
()],
chief_only_hooks
=
[
summary_hook
],
# Since we provide a SummarySaverHook, we need to disable default
# SummarySaverHook. To do that we set save_summaries_steps to 0.
save_summaries_steps
=
0
,
config
=
tf
.
ConfigProto
(
allow_soft_placement
=
True
))
as
mon_sess
:
while
not
mon_sess
.
should_stop
():
mon_sess
.
run
(
model
.
train_op
)
def
evaluate
(
hps
):
"""Eval loop."""
images
,
labels
=
cifar_input
.
build_input
(
FLAGS
.
dataset
,
FLAGS
.
eval_data_path
,
hps
.
batch_size
,
FLAGS
.
mode
)
model
=
resnet_model
.
ResNet
(
hps
,
images
,
labels
,
FLAGS
.
mode
)
model
.
build_graph
()
saver
=
tf
.
train
.
Saver
()
summary_writer
=
tf
.
summary
.
FileWriter
(
FLAGS
.
eval_dir
)
sess
=
tf
.
Session
(
config
=
tf
.
ConfigProto
(
allow_soft_placement
=
True
))
tf
.
train
.
start_queue_runners
(
sess
)
best_precision
=
0.0
while
True
:
try
:
ckpt_state
=
tf
.
train
.
get_checkpoint_state
(
FLAGS
.
log_root
)
except
tf
.
errors
.
OutOfRangeError
as
e
:
tf
.
logging
.
error
(
'Cannot restore checkpoint: %s'
,
e
)
continue
if
not
(
ckpt_state
and
ckpt_state
.
model_checkpoint_path
):
tf
.
logging
.
info
(
'No model to eval yet at %s'
,
FLAGS
.
log_root
)
continue
tf
.
logging
.
info
(
'Loading checkpoint %s'
,
ckpt_state
.
model_checkpoint_path
)
saver
.
restore
(
sess
,
ckpt_state
.
model_checkpoint_path
)
total_prediction
,
correct_prediction
=
0
,
0
for
_
in
six
.
moves
.
range
(
FLAGS
.
eval_batch_count
):
(
summaries
,
loss
,
predictions
,
truth
,
train_step
)
=
sess
.
run
(
[
model
.
summaries
,
model
.
cost
,
model
.
predictions
,
model
.
labels
,
model
.
global_step
])
truth
=
np
.
argmax
(
truth
,
axis
=
1
)
predictions
=
np
.
argmax
(
predictions
,
axis
=
1
)
correct_prediction
+=
np
.
sum
(
truth
==
predictions
)
total_prediction
+=
predictions
.
shape
[
0
]
precision
=
1.0
*
correct_prediction
/
total_prediction
best_precision
=
max
(
precision
,
best_precision
)
precision_summ
=
tf
.
Summary
()
precision_summ
.
value
.
add
(
tag
=
'Precision'
,
simple_value
=
precision
)
summary_writer
.
add_summary
(
precision_summ
,
train_step
)
best_precision_summ
=
tf
.
Summary
()
best_precision_summ
.
value
.
add
(
tag
=
'Best Precision'
,
simple_value
=
best_precision
)
summary_writer
.
add_summary
(
best_precision_summ
,
train_step
)
summary_writer
.
add_summary
(
summaries
,
train_step
)
tf
.
logging
.
info
(
'loss: %.3f, precision: %.3f, best precision: %.3f'
%
(
loss
,
precision
,
best_precision
))
summary_writer
.
flush
()
if
FLAGS
.
eval_once
:
break
time
.
sleep
(
60
)
def
main
(
_
):
if
FLAGS
.
num_gpus
==
0
:
dev
=
'/cpu:0'
elif
FLAGS
.
num_gpus
==
1
:
dev
=
'/gpu:0'
else
:
raise
ValueError
(
'Only support 0 or 1 gpu.'
)
if
FLAGS
.
mode
==
'train'
:
batch_size
=
128
elif
FLAGS
.
mode
==
'eval'
:
batch_size
=
100
if
FLAGS
.
dataset
==
'cifar10'
:
num_classes
=
10
elif
FLAGS
.
dataset
==
'cifar100'
:
num_classes
=
100
hps
=
resnet_model
.
HParams
(
batch_size
=
batch_size
,
num_classes
=
num_classes
,
min_lrn_rate
=
0.0001
,
lrn_rate
=
0.1
,
num_residual_units
=
5
,
use_bottleneck
=
False
,
weight_decay_rate
=
0.0002
,
relu_leakiness
=
0.1
,
optimizer
=
'mom'
)
with
tf
.
device
(
dev
):
if
FLAGS
.
mode
==
'train'
:
train
(
hps
)
elif
FLAGS
.
mode
==
'eval'
:
evaluate
(
hps
)
if
__name__
==
'__main__'
:
tf
.
logging
.
set_verbosity
(
tf
.
logging
.
INFO
)
tf
.
app
.
run
()
research/resnet/resnet_model.py
deleted
100644 → 0
View file @
3e12ad2b
# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""ResNet model.
Related papers:
https://arxiv.org/pdf/1603.05027v2.pdf
https://arxiv.org/pdf/1512.03385v1.pdf
https://arxiv.org/pdf/1605.07146v1.pdf
"""
from
collections
import
namedtuple
import
numpy
as
np
import
tensorflow
as
tf
import
six
from
tensorflow.python.training
import
moving_averages
HParams
=
namedtuple
(
'HParams'
,
'batch_size, num_classes, min_lrn_rate, lrn_rate, '
'num_residual_units, use_bottleneck, weight_decay_rate, '
'relu_leakiness, optimizer'
)
tf
.
logging
.
warning
(
"models/research/resnet is deprecated. "
"Please use models/official/resnet instead."
)
class
ResNet
(
object
):
"""ResNet model."""
def
__init__
(
self
,
hps
,
images
,
labels
,
mode
):
"""ResNet constructor.
Args:
hps: Hyperparameters.
images: Batches of images. [batch_size, image_size, image_size, 3]
labels: Batches of labels. [batch_size, num_classes]
mode: One of 'train' and 'eval'.
"""
self
.
hps
=
hps
self
.
_images
=
images
self
.
labels
=
labels
self
.
mode
=
mode
self
.
_extra_train_ops
=
[]
def
build_graph
(
self
):
"""Build a whole graph for the model."""
self
.
global_step
=
tf
.
train
.
get_or_create_global_step
()
self
.
_build_model
()
if
self
.
mode
==
'train'
:
self
.
_build_train_op
()
self
.
summaries
=
tf
.
summary
.
merge_all
()
def
_stride_arr
(
self
,
stride
):
"""Map a stride scalar to the stride array for tf.nn.conv2d."""
return
[
1
,
stride
,
stride
,
1
]
def
_build_model
(
self
):
"""Build the core model within the graph."""
with
tf
.
variable_scope
(
'init'
):
x
=
self
.
_images
x
=
self
.
_conv
(
'init_conv'
,
x
,
3
,
3
,
16
,
self
.
_stride_arr
(
1
))
strides
=
[
1
,
2
,
2
]
activate_before_residual
=
[
True
,
False
,
False
]
if
self
.
hps
.
use_bottleneck
:
res_func
=
self
.
_bottleneck_residual
filters
=
[
16
,
64
,
128
,
256
]
else
:
res_func
=
self
.
_residual
filters
=
[
16
,
16
,
32
,
64
]
# Uncomment the following codes to use w28-10 wide residual network.
# It is more memory efficient than very deep residual network and has
# comparably good performance.
# https://arxiv.org/pdf/1605.07146v1.pdf
# filters = [16, 160, 320, 640]
# Update hps.num_residual_units to 4
with
tf
.
variable_scope
(
'unit_1_0'
):
x
=
res_func
(
x
,
filters
[
0
],
filters
[
1
],
self
.
_stride_arr
(
strides
[
0
]),
activate_before_residual
[
0
])
for
i
in
six
.
moves
.
range
(
1
,
self
.
hps
.
num_residual_units
):
with
tf
.
variable_scope
(
'unit_1_%d'
%
i
):
x
=
res_func
(
x
,
filters
[
1
],
filters
[
1
],
self
.
_stride_arr
(
1
),
False
)
with
tf
.
variable_scope
(
'unit_2_0'
):
x
=
res_func
(
x
,
filters
[
1
],
filters
[
2
],
self
.
_stride_arr
(
strides
[
1
]),
activate_before_residual
[
1
])
for
i
in
six
.
moves
.
range
(
1
,
self
.
hps
.
num_residual_units
):
with
tf
.
variable_scope
(
'unit_2_%d'
%
i
):
x
=
res_func
(
x
,
filters
[
2
],
filters
[
2
],
self
.
_stride_arr
(
1
),
False
)
with
tf
.
variable_scope
(
'unit_3_0'
):
x
=
res_func
(
x
,
filters
[
2
],
filters
[
3
],
self
.
_stride_arr
(
strides
[
2
]),
activate_before_residual
[
2
])
for
i
in
six
.
moves
.
range
(
1
,
self
.
hps
.
num_residual_units
):
with
tf
.
variable_scope
(
'unit_3_%d'
%
i
):
x
=
res_func
(
x
,
filters
[
3
],
filters
[
3
],
self
.
_stride_arr
(
1
),
False
)
with
tf
.
variable_scope
(
'unit_last'
):
x
=
self
.
_batch_norm
(
'final_bn'
,
x
)
x
=
self
.
_relu
(
x
,
self
.
hps
.
relu_leakiness
)
x
=
self
.
_global_avg_pool
(
x
)
with
tf
.
variable_scope
(
'logit'
):
logits
=
self
.
_fully_connected
(
x
,
self
.
hps
.
num_classes
)
self
.
predictions
=
tf
.
nn
.
softmax
(
logits
)
with
tf
.
variable_scope
(
'costs'
):
xent
=
tf
.
nn
.
softmax_cross_entropy_with_logits
(
logits
=
logits
,
labels
=
self
.
labels
)
self
.
cost
=
tf
.
reduce_mean
(
xent
,
name
=
'xent'
)
self
.
cost
+=
self
.
_decay
()
tf
.
summary
.
scalar
(
'cost'
,
self
.
cost
)
def
_build_train_op
(
self
):
"""Build training specific ops for the graph."""
self
.
lrn_rate
=
tf
.
constant
(
self
.
hps
.
lrn_rate
,
tf
.
float32
)
tf
.
summary
.
scalar
(
'learning_rate'
,
self
.
lrn_rate
)
trainable_variables
=
tf
.
trainable_variables
()
grads
=
tf
.
gradients
(
self
.
cost
,
trainable_variables
)
if
self
.
hps
.
optimizer
==
'sgd'
:
optimizer
=
tf
.
train
.
GradientDescentOptimizer
(
self
.
lrn_rate
)
elif
self
.
hps
.
optimizer
==
'mom'
:
optimizer
=
tf
.
train
.
MomentumOptimizer
(
self
.
lrn_rate
,
0.9
)
apply_op
=
optimizer
.
apply_gradients
(
zip
(
grads
,
trainable_variables
),
global_step
=
self
.
global_step
,
name
=
'train_step'
)
train_ops
=
[
apply_op
]
+
self
.
_extra_train_ops
self
.
train_op
=
tf
.
group
(
*
train_ops
)
# TODO(xpan): Consider batch_norm in contrib/layers/python/layers/layers.py
def
_batch_norm
(
self
,
name
,
x
):
"""Batch normalization."""
with
tf
.
variable_scope
(
name
):
params_shape
=
[
x
.
get_shape
()[
-
1
]]
beta
=
tf
.
get_variable
(
'beta'
,
params_shape
,
tf
.
float32
,
initializer
=
tf
.
constant_initializer
(
0.0
,
tf
.
float32
))
gamma
=
tf
.
get_variable
(
'gamma'
,
params_shape
,
tf
.
float32
,
initializer
=
tf
.
constant_initializer
(
1.0
,
tf
.
float32
))
if
self
.
mode
==
'train'
:
mean
,
variance
=
tf
.
nn
.
moments
(
x
,
[
0
,
1
,
2
],
name
=
'moments'
)
moving_mean
=
tf
.
get_variable
(
'moving_mean'
,
params_shape
,
tf
.
float32
,
initializer
=
tf
.
constant_initializer
(
0.0
,
tf
.
float32
),
trainable
=
False
)
moving_variance
=
tf
.
get_variable
(
'moving_variance'
,
params_shape
,
tf
.
float32
,
initializer
=
tf
.
constant_initializer
(
1.0
,
tf
.
float32
),
trainable
=
False
)
self
.
_extra_train_ops
.
append
(
moving_averages
.
assign_moving_average
(
moving_mean
,
mean
,
0.9
))
self
.
_extra_train_ops
.
append
(
moving_averages
.
assign_moving_average
(
moving_variance
,
variance
,
0.9
))
else
:
mean
=
tf
.
get_variable
(
'moving_mean'
,
params_shape
,
tf
.
float32
,
initializer
=
tf
.
constant_initializer
(
0.0
,
tf
.
float32
),
trainable
=
False
)
variance
=
tf
.
get_variable
(
'moving_variance'
,
params_shape
,
tf
.
float32
,
initializer
=
tf
.
constant_initializer
(
1.0
,
tf
.
float32
),
trainable
=
False
)
tf
.
summary
.
histogram
(
mean
.
op
.
name
,
mean
)
tf
.
summary
.
histogram
(
variance
.
op
.
name
,
variance
)
# epsilon used to be 1e-5. Maybe 0.001 solves NaN problem in deeper net.
y
=
tf
.
nn
.
batch_normalization
(
x
,
mean
,
variance
,
beta
,
gamma
,
0.001
)
y
.
set_shape
(
x
.
get_shape
())
return
y
def
_residual
(
self
,
x
,
in_filter
,
out_filter
,
stride
,
activate_before_residual
=
False
):
"""Residual unit with 2 sub layers."""
if
activate_before_residual
:
with
tf
.
variable_scope
(
'shared_activation'
):
x
=
self
.
_batch_norm
(
'init_bn'
,
x
)
x
=
self
.
_relu
(
x
,
self
.
hps
.
relu_leakiness
)
orig_x
=
x
else
:
with
tf
.
variable_scope
(
'residual_only_activation'
):
orig_x
=
x
x
=
self
.
_batch_norm
(
'init_bn'
,
x
)
x
=
self
.
_relu
(
x
,
self
.
hps
.
relu_leakiness
)
with
tf
.
variable_scope
(
'sub1'
):
x
=
self
.
_conv
(
'conv1'
,
x
,
3
,
in_filter
,
out_filter
,
stride
)
with
tf
.
variable_scope
(
'sub2'
):
x
=
self
.
_batch_norm
(
'bn2'
,
x
)
x
=
self
.
_relu
(
x
,
self
.
hps
.
relu_leakiness
)
x
=
self
.
_conv
(
'conv2'
,
x
,
3
,
out_filter
,
out_filter
,
[
1
,
1
,
1
,
1
])
with
tf
.
variable_scope
(
'sub_add'
):
if
in_filter
!=
out_filter
:
orig_x
=
tf
.
nn
.
avg_pool
(
orig_x
,
stride
,
stride
,
'VALID'
)
orig_x
=
tf
.
pad
(
orig_x
,
[[
0
,
0
],
[
0
,
0
],
[
0
,
0
],
[(
out_filter
-
in_filter
)
//
2
,
(
out_filter
-
in_filter
)
//
2
]])
x
+=
orig_x
tf
.
logging
.
debug
(
'image after unit %s'
,
x
.
get_shape
())
return
x
def
_bottleneck_residual
(
self
,
x
,
in_filter
,
out_filter
,
stride
,
activate_before_residual
=
False
):
"""Bottleneck residual unit with 3 sub layers."""
if
activate_before_residual
:
with
tf
.
variable_scope
(
'common_bn_relu'
):
x
=
self
.
_batch_norm
(
'init_bn'
,
x
)
x
=
self
.
_relu
(
x
,
self
.
hps
.
relu_leakiness
)
orig_x
=
x
else
:
with
tf
.
variable_scope
(
'residual_bn_relu'
):
orig_x
=
x
x
=
self
.
_batch_norm
(
'init_bn'
,
x
)
x
=
self
.
_relu
(
x
,
self
.
hps
.
relu_leakiness
)
with
tf
.
variable_scope
(
'sub1'
):
x
=
self
.
_conv
(
'conv1'
,
x
,
1
,
in_filter
,
out_filter
/
4
,
stride
)
with
tf
.
variable_scope
(
'sub2'
):
x
=
self
.
_batch_norm
(
'bn2'
,
x
)
x
=
self
.
_relu
(
x
,
self
.
hps
.
relu_leakiness
)
x
=
self
.
_conv
(
'conv2'
,
x
,
3
,
out_filter
/
4
,
out_filter
/
4
,
[
1
,
1
,
1
,
1
])
with
tf
.
variable_scope
(
'sub3'
):
x
=
self
.
_batch_norm
(
'bn3'
,
x
)
x
=
self
.
_relu
(
x
,
self
.
hps
.
relu_leakiness
)
x
=
self
.
_conv
(
'conv3'
,
x
,
1
,
out_filter
/
4
,
out_filter
,
[
1
,
1
,
1
,
1
])
with
tf
.
variable_scope
(
'sub_add'
):
if
in_filter
!=
out_filter
:
orig_x
=
self
.
_conv
(
'project'
,
orig_x
,
1
,
in_filter
,
out_filter
,
stride
)
x
+=
orig_x
tf
.
logging
.
info
(
'image after unit %s'
,
x
.
get_shape
())
return
x
def
_decay
(
self
):
"""L2 weight decay loss."""
costs
=
[]
for
var
in
tf
.
trainable_variables
():
if
var
.
op
.
name
.
find
(
r
'DW'
)
>
0
:
costs
.
append
(
tf
.
nn
.
l2_loss
(
var
))
# tf.summary.histogram(var.op.name, var)
return
tf
.
multiply
(
self
.
hps
.
weight_decay_rate
,
tf
.
add_n
(
costs
))
def
_conv
(
self
,
name
,
x
,
filter_size
,
in_filters
,
out_filters
,
strides
):
"""Convolution."""
with
tf
.
variable_scope
(
name
):
n
=
filter_size
*
filter_size
*
out_filters
kernel
=
tf
.
get_variable
(
'DW'
,
[
filter_size
,
filter_size
,
in_filters
,
out_filters
],
tf
.
float32
,
initializer
=
tf
.
random_normal_initializer
(
stddev
=
np
.
sqrt
(
2.0
/
n
)))
return
tf
.
nn
.
conv2d
(
x
,
kernel
,
strides
,
padding
=
'SAME'
)
def
_relu
(
self
,
x
,
leakiness
=
0.0
):
"""Relu, with optional leaky support."""
return
tf
.
where
(
tf
.
less
(
x
,
0.0
),
leakiness
*
x
,
x
,
name
=
'leaky_relu'
)
def
_fully_connected
(
self
,
x
,
out_dim
):
"""FullyConnected layer for final output."""
x
=
tf
.
reshape
(
x
,
[
self
.
hps
.
batch_size
,
-
1
])
w
=
tf
.
get_variable
(
'DW'
,
[
x
.
get_shape
()[
1
],
out_dim
],
initializer
=
tf
.
uniform_unit_scaling_initializer
(
factor
=
1.0
))
b
=
tf
.
get_variable
(
'biases'
,
[
out_dim
],
initializer
=
tf
.
constant_initializer
())
return
tf
.
nn
.
xw_plus_b
(
x
,
w
,
b
)
def
_global_avg_pool
(
self
,
x
):
assert
x
.
get_shape
().
ndims
==
4
return
tf
.
reduce_mean
(
x
,
[
1
,
2
])
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}