
Merge branch 'master' into patch-6
Showing
official/mnist/dataset.py
0 → 100644
official/mnist/example3.png
0 → 100644
{kind=link}
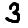
368 Bytes
official/mnist/example5.png
0 → 100644
{kind=link}
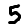
367 Bytes
official/mnist/examples.npy
0 → 100644
File added
official/mnist/mnist_tpu.py
0 → 100644
research/astronet/README.md
0 → 100644
{kind=link}

135 KB
{kind=link}

118 KB