
Merge pull request #5862 from cshallue/master
Move tensorflow_models/research/astronet to google-research/exoplanet-ml
Showing
{kind=link}
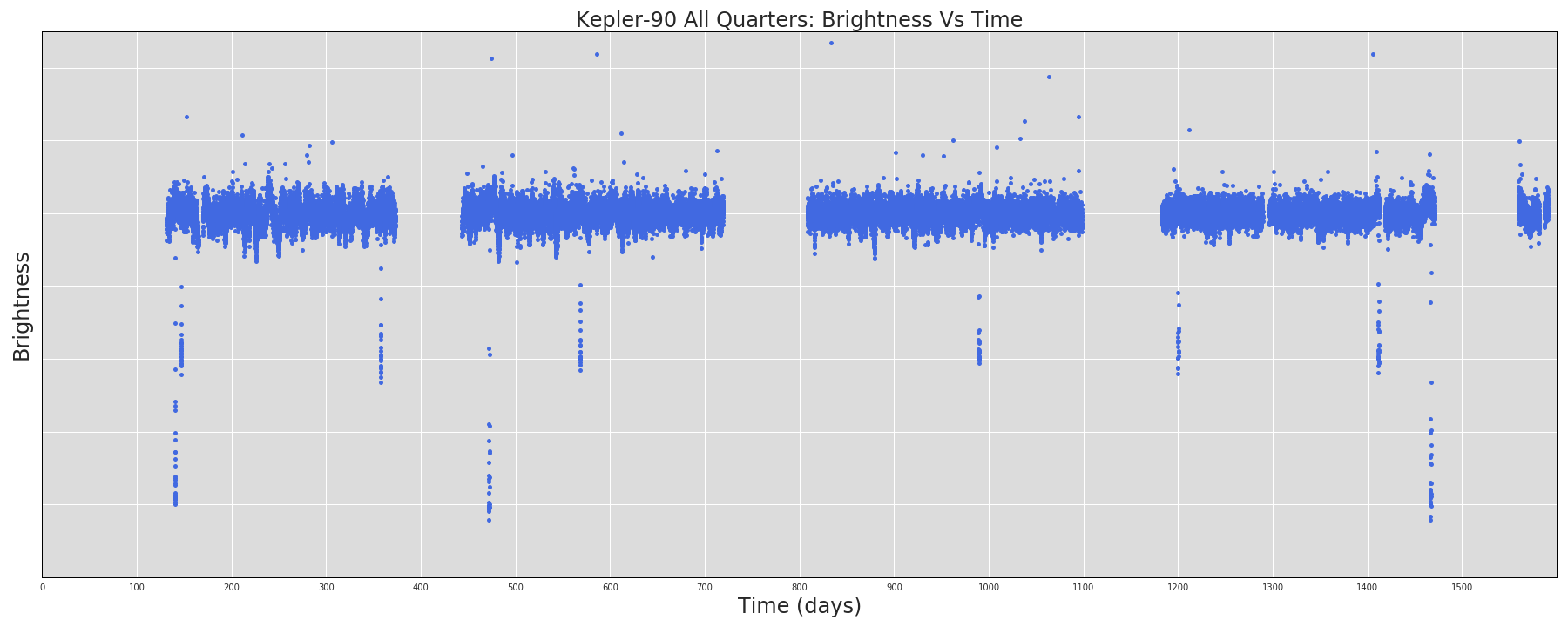
65.8 KB
{kind=link}

52.2 KB
{kind=link}

50.5 KB
{kind=link}

73.1 KB
{kind=link}

30.7 KB
{kind=link}

66.1 KB
{kind=link}

124 KB
{kind=link}

156 KB
{kind=link}

98.3 KB
{kind=link}

6.52 MB
Move tensorflow_models/research/astronet to google-research/exoplanet-ml
65.8 KB
52.2 KB
50.5 KB
73.1 KB
30.7 KB
66.1 KB
124 KB
156 KB
98.3 KB
6.52 MB