
resnet50
Showing
File added
File added
File added
File added
File added
File added
File added
models/accuracy.py
0 → 100644
models/data.py
0 → 100644
models/optimizer.py
0 → 100644
models/pytorch_resnet50.py
0 → 100644
models/resnet50.py
0 → 100644
requirements.txt
0 → 100644
train.py
0 → 100644
utils/Figure_1.png
0 → 100644
{kind=link}
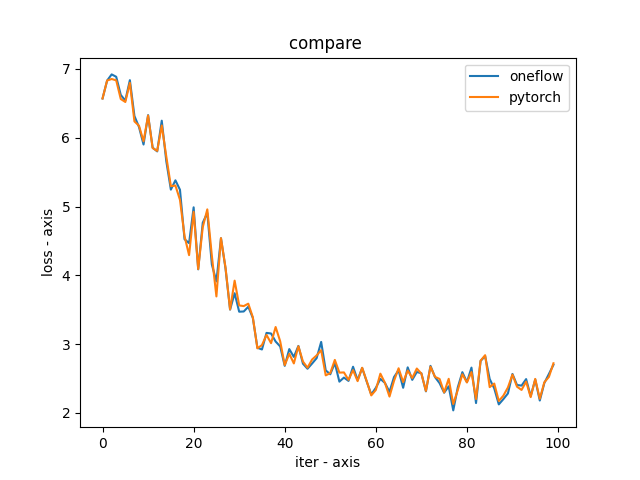
35.4 KB
utils/__init__.py
0 → 100644
File added
File added
File added
File added