"web/vscode:/vscode.git/clone" did not exist on "7c5fa7f4a2046c1f4bb77ed5e480918ffb8a10aa"

resnet50-qat
parents
Showing
.gitignore
0 → 100644
README.md
0 → 100644
evaluate.py
0 → 100755
main.py
0 → 100644
model.properties
0 → 100644
models.py
0 → 100644
readme_imgs/image-1.png
0 → 100644
{kind=link}
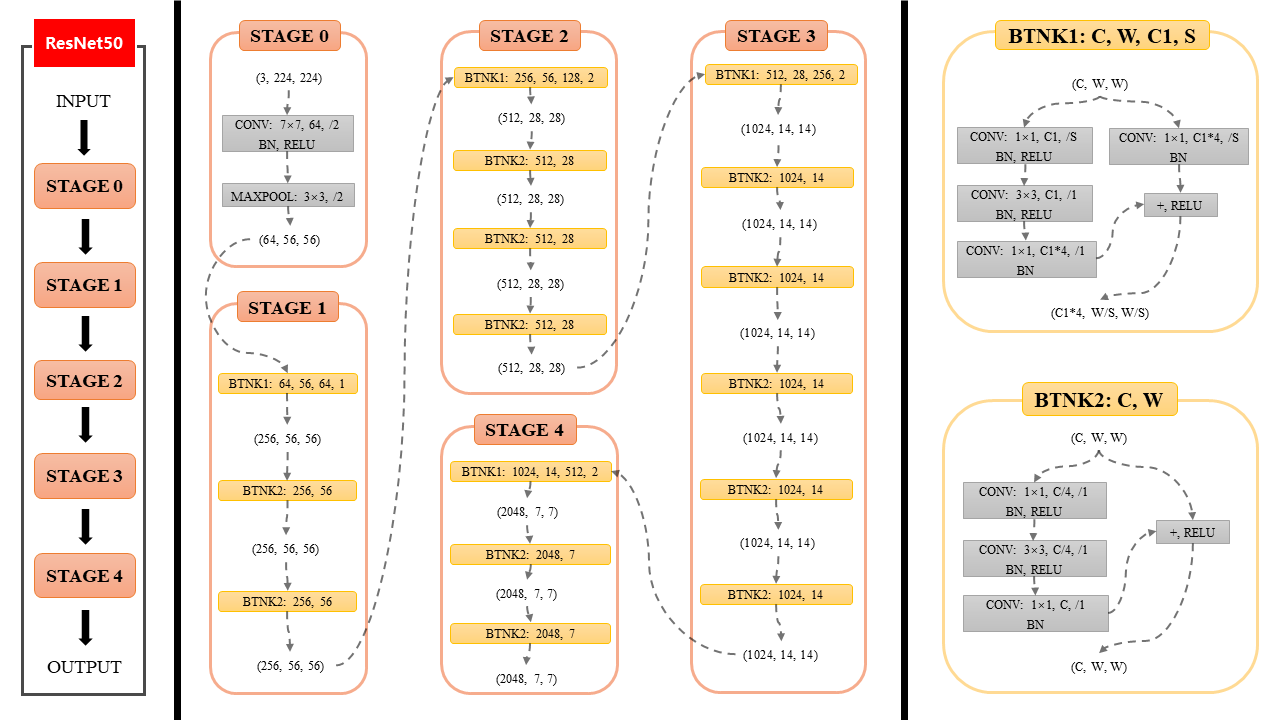
133 KB
readme_imgs/image-2.png
0 → 100644
{kind=link}
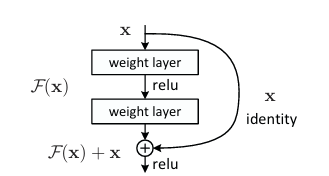
11.2 KB
readme_imgs/image-3.png
0 → 100644
{kind=link}

551 KB
utils/__init__.py
0 → 100644
utils/data.py
0 → 100644
utils/qat.py
0 → 100644
utils/trt.py
0 → 100644