
First commit.
Showing
.gitignore
0 → 100644
CODE_OF_CONDUCT.md
0 → 100644
LICENSE
0 → 100644
MANIFEST.in
0 → 100644
README.md
0 → 100644
VERSION
0 → 100644
assets/realesrgan_logo.png
0 → 100644
{kind=link}
83.4 KB
{kind=link}
80.7 KB
{kind=link}
81.1 KB
{kind=link}
81.2 KB
{kind=link}
81.4 KB
assets/teaser-text.png
0 → 100644
{kind=link}

546 KB
assets/teaser.jpg
0 → 100644
{kind=link}

396 KB
cog.yaml
0 → 100644
cog_predict.py
0 → 100644
doc/00017_gray.jpg
0 → 100644
{kind=link}

68.3 KB
doc/00017_gray_out.jpg
0 → 100644
{kind=link}

476 KB
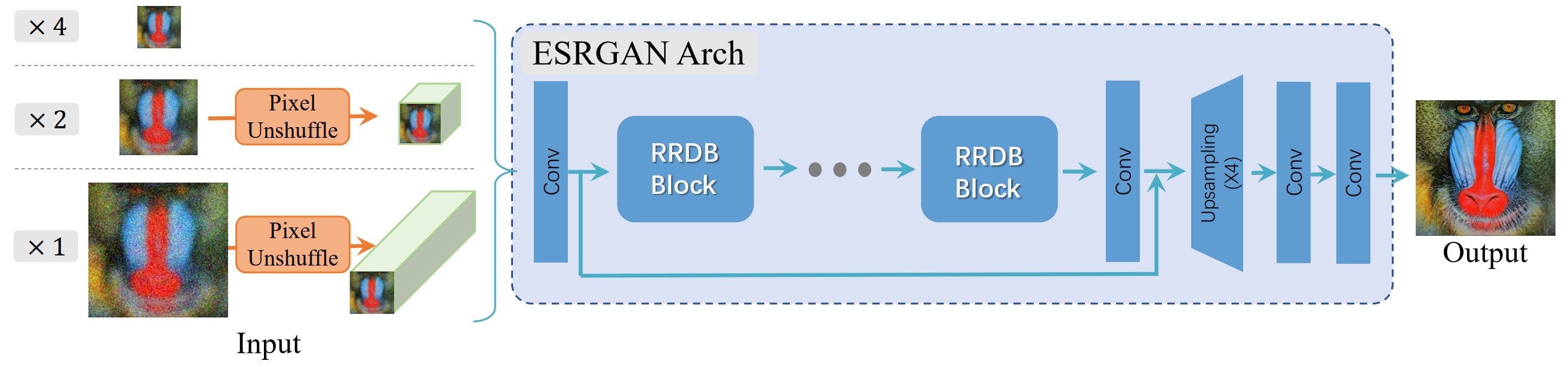
doc/ESRGAN.png
0 → 100644
{kind=link}
480 KB
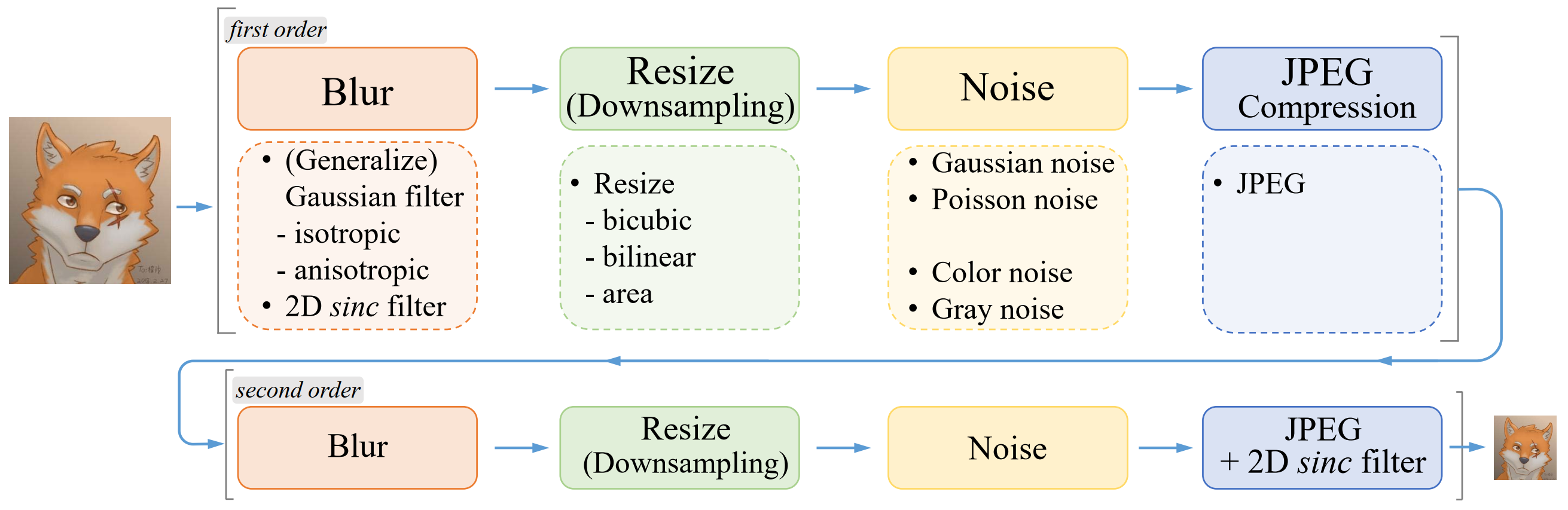
doc/High-order的pipeline.png
0 → 100644
{kind=link}
371 KB
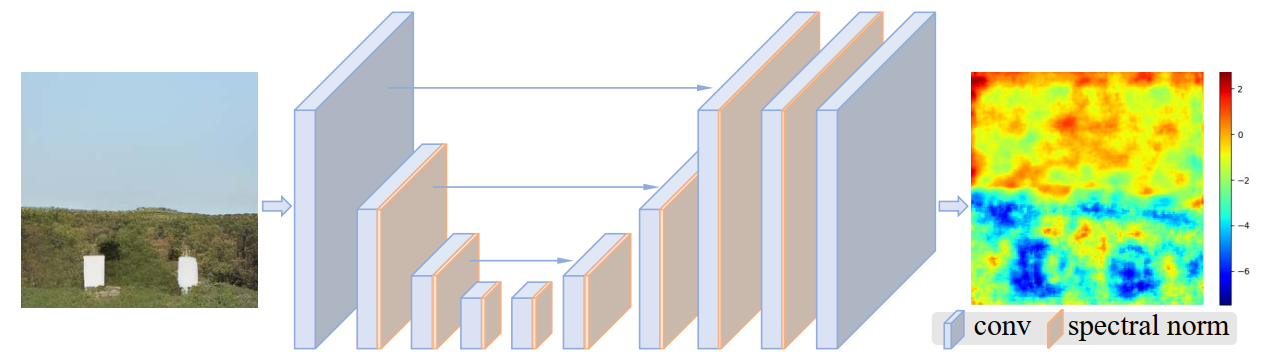
doc/UNet.png
0 → 100644
{kind=link}
187 KB