
Add qwen3-asr
Showing
README.md
0 → 100644
README_origin.md
0 → 100644
This diff is collapsed.
doc/asr_en.wav
0 → 100644
File added
doc/overview.jpg
0 → 100644
{kind=link}
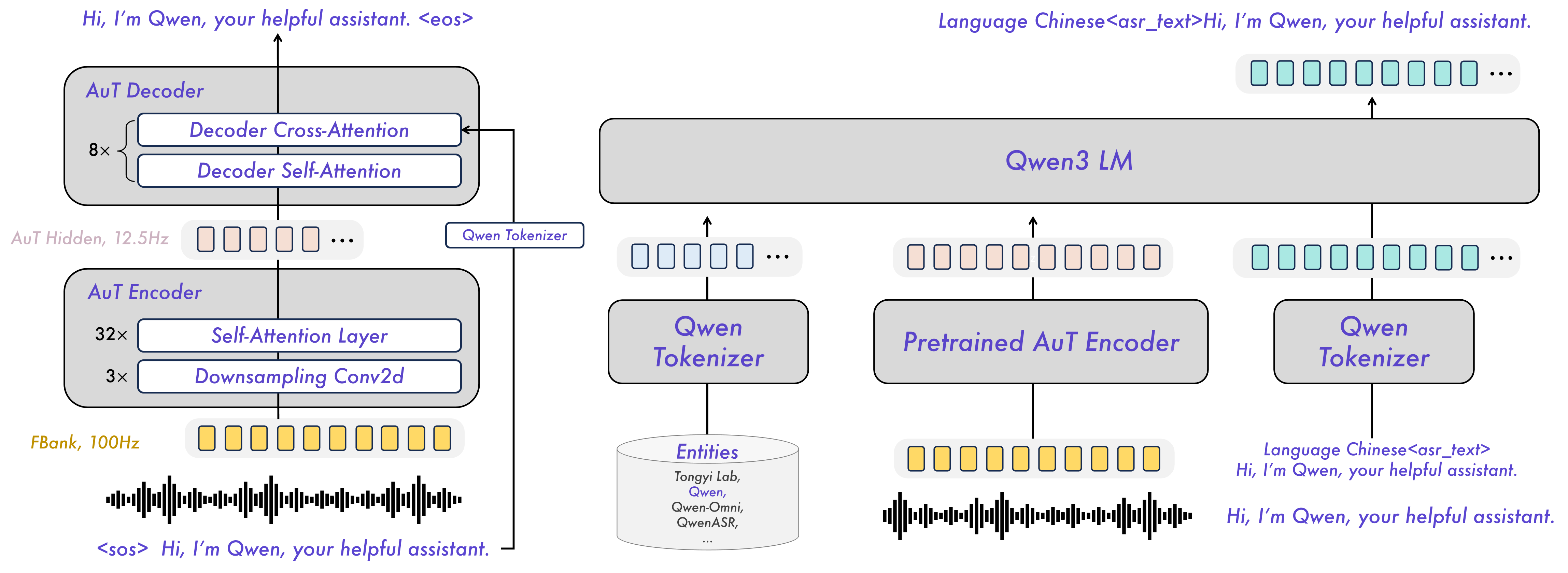
304 KB
doc/vllm_result.png
0 → 100644
{kind=link}

9.51 KB
icon.png
0 → 100644
{kind=link}
68.4 KB
inference.py
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| transformers==4.57.6 | ||
| nagisa==0.2.11 | ||
| soynlp==0.0.493 | ||
| accelerate==1.12.0 | ||
| qwen-omni-utils | ||
| librosa | ||
| soundfile | ||
| sox | ||
| gradio | ||
| flask | ||
| pytz | ||
| pycountry | ||
| \ No newline at end of file |
vllm.zip
0 → 100644
File added