"vscode:/vscode.git/clone" did not exist on "b936bcc72eae0a618173dc9b5676fb193739d055"

Initial commit
Showing
.gitignore
0 → 100644
2308.12966v3.pdf
0 → 100644
File added
Contributors.md
0 → 100644
FAQ_zh.md
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_CN.md
0 → 100644
This diff is collapsed.
TUTORIAL_zh.md
0 → 100644
assets/apple.jpeg
0 → 100644
{kind=link}

2.35 MB
assets/apple_r.jpeg
0 → 100644
{kind=link}

465 KB
assets/car_num.png
0 → 100644
{kind=link}

12.2 KB
assets/demo_highfive.jpg
0 → 100644
{kind=link}

233 KB
{kind=link}
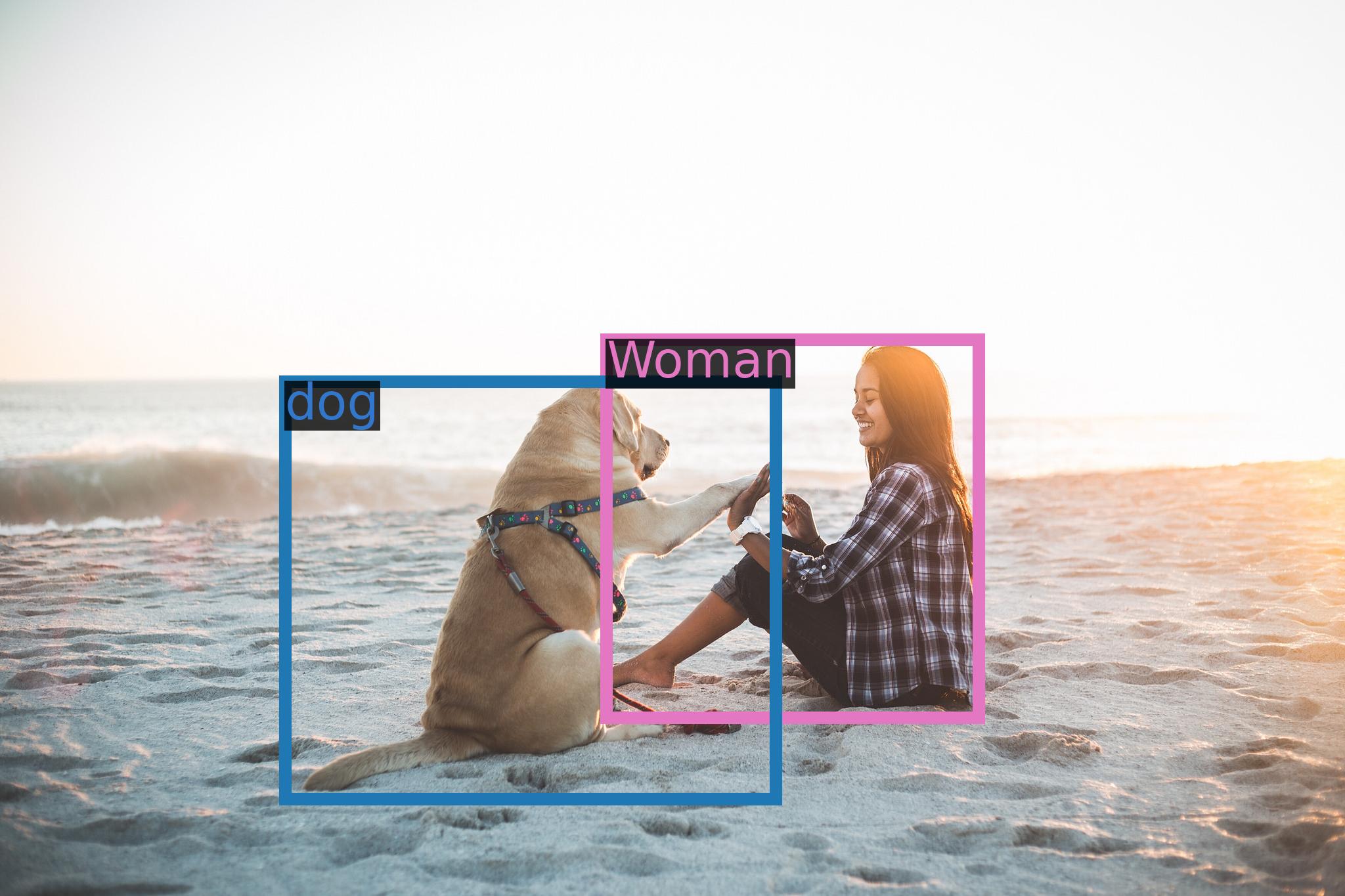
242 KB
assets/demo_vl.gif
0 → 100644
{kind=link}
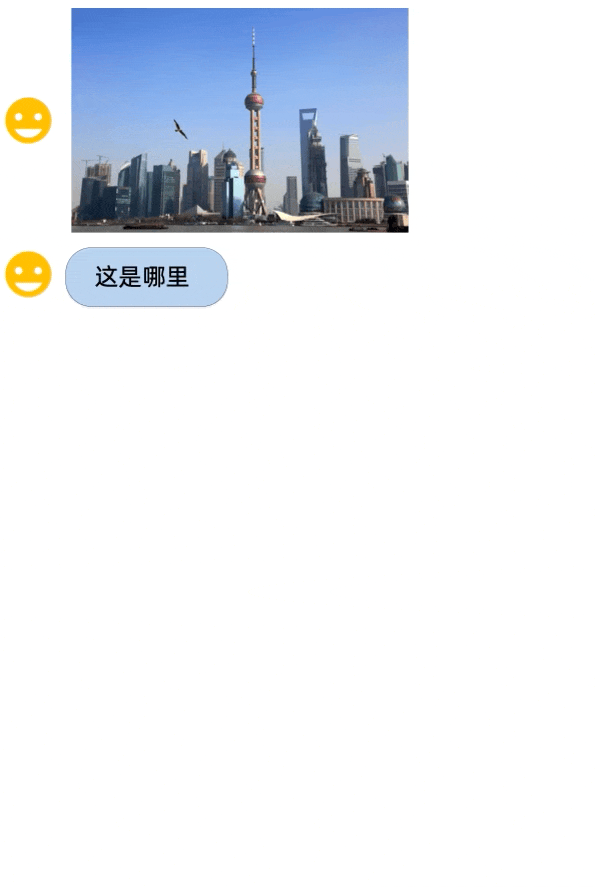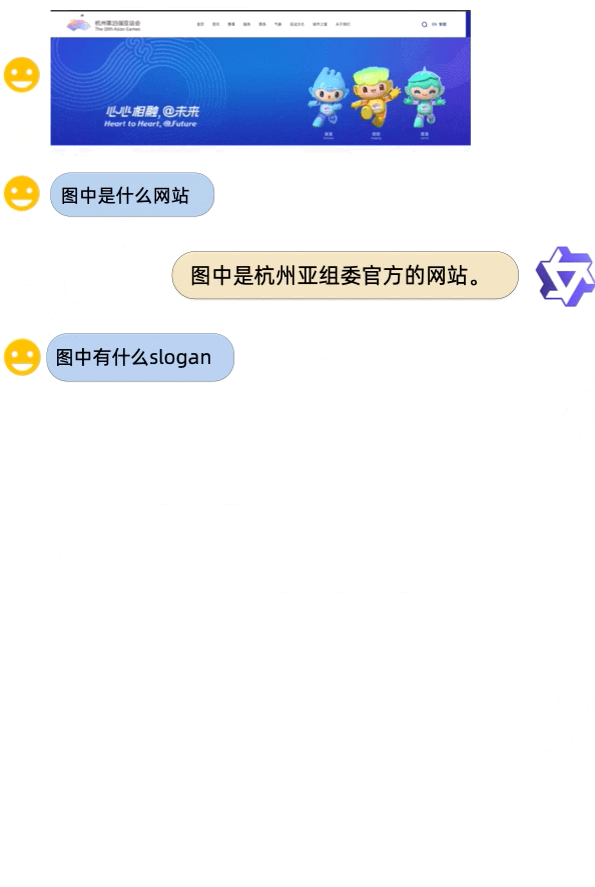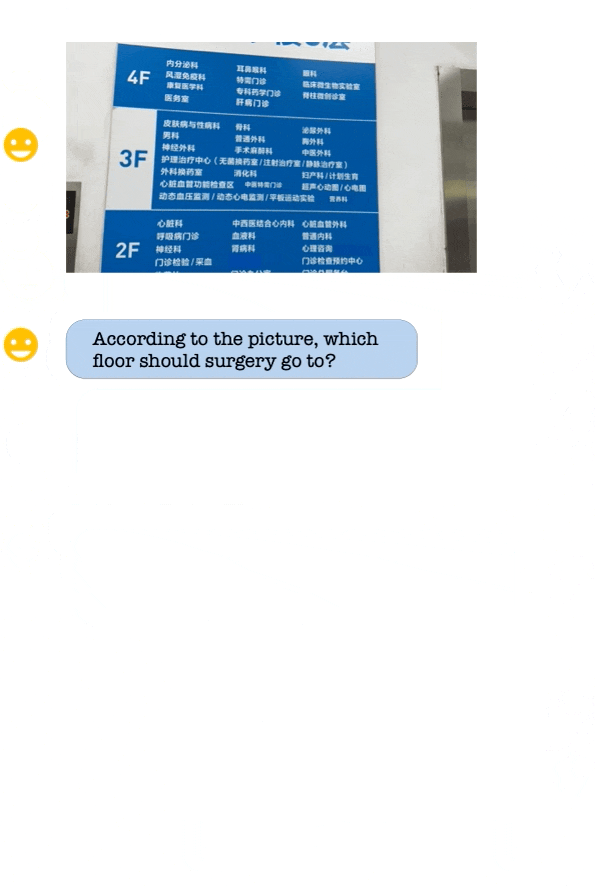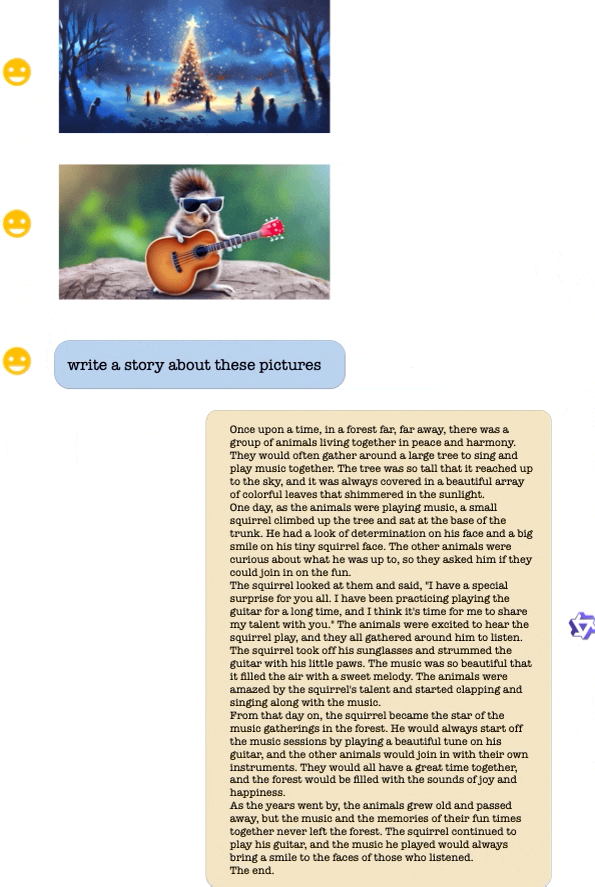
2.07 MB
assets/logo.jpg
0 → 100644
{kind=link}
61.9 KB
assets/mm_tutorial/2.jpg
0 → 100644
{kind=link}
242 KB
{kind=link}

8.8 MB