
paddleOcr v5
parents
Showing
3rdParty/InstallRBuild.sh
0 → 100755
File added
3rdParty/pax_global_header
0 → 100755
File added
File added
File added
File added
File added
File added
File added
CMakeLists.txt
0 → 100755
Doc/Images/CRNN.png
0 → 100644
{kind=link}
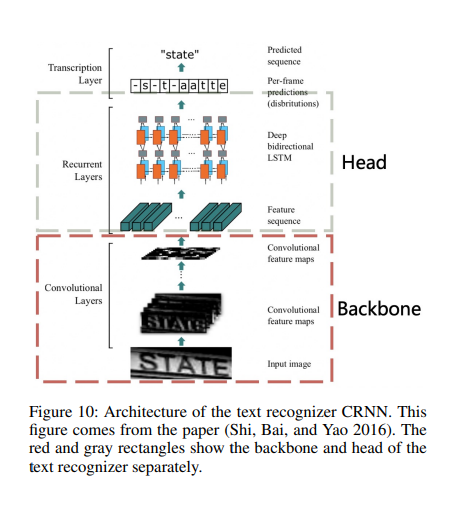
112 KB
Doc/Images/DBNet.png
0 → 100644
{kind=link}
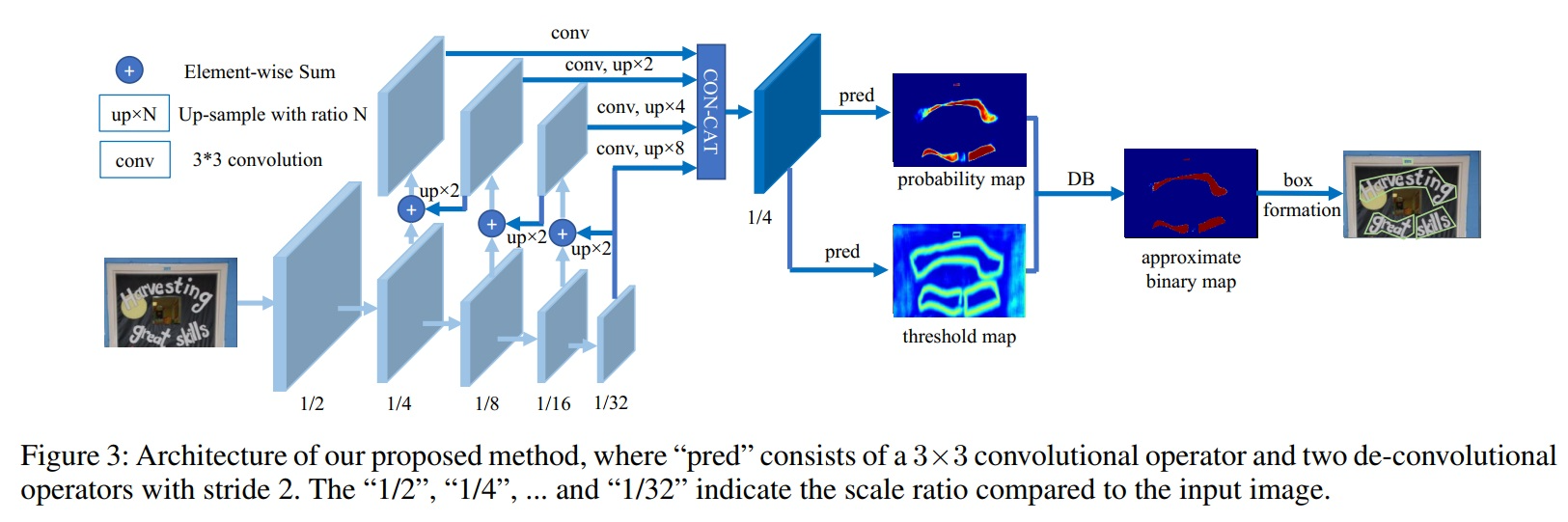
597 KB
Doc/Images/pipeline.png
0 → 100644
{kind=link}
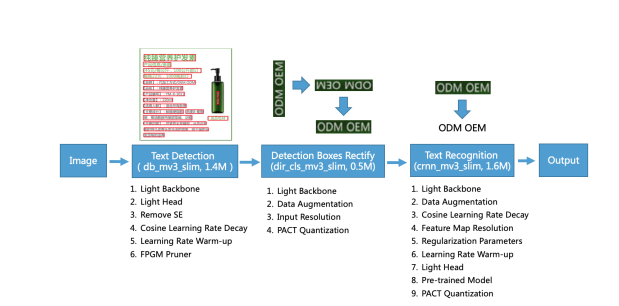
64.8 KB
Doc/Tutorial_Cpp.md
0 → 100755
Doc/Tutorial_Python.md
0 → 100755
Python/inference.py
0 → 100755
This diff is collapsed.
Python/requirements.txt
0 → 100755
Python/res.jpg
0 → 100755
{kind=link}
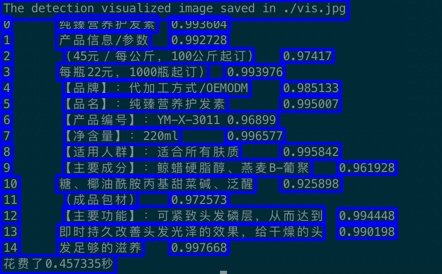
55.3 KB