
更新
Showing
imgs/city_short.gif
deleted
100644 → 0
{kind=link}
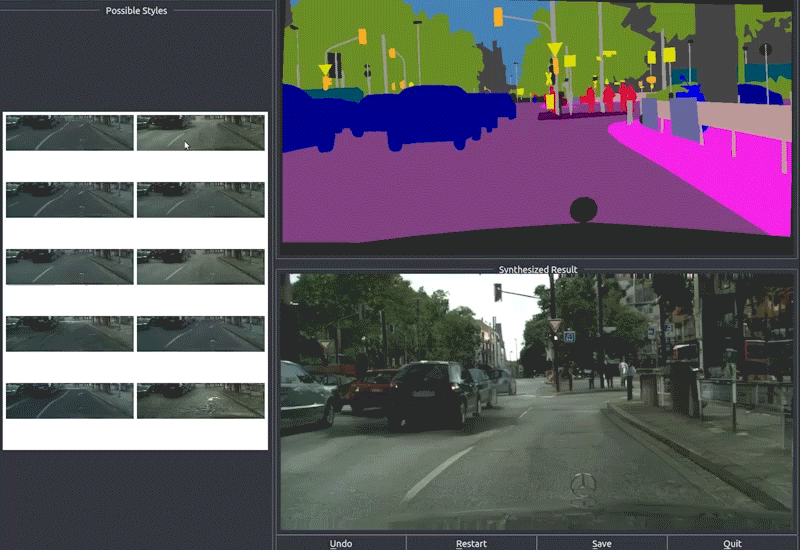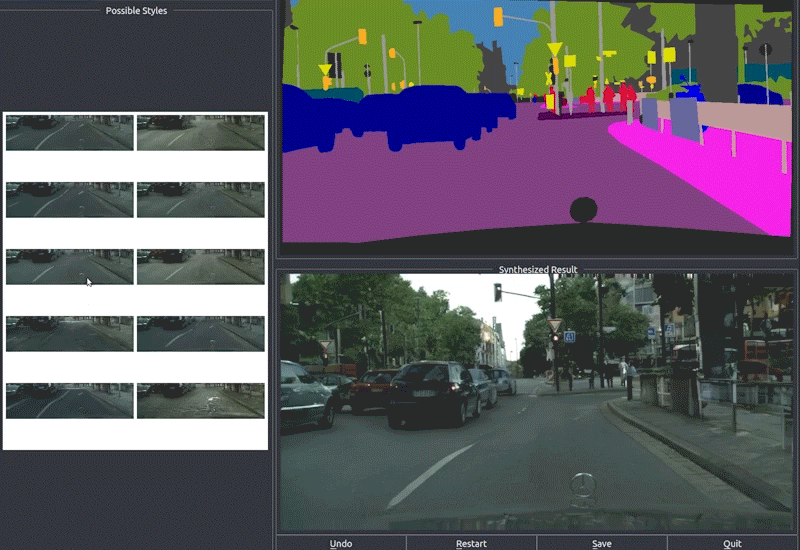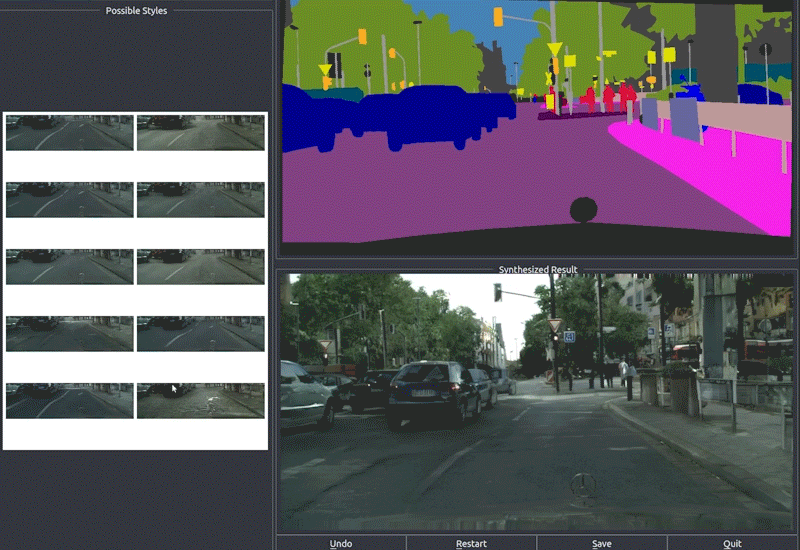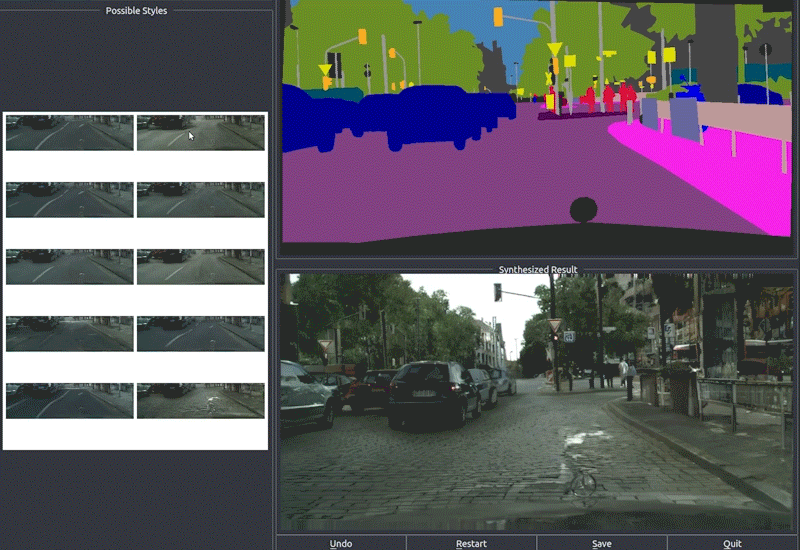
5.59 MB
{kind=link}

208 KB
{kind=link}

178 KB
{kind=link}

193 KB
{kind=link}

173 KB
imgs/face1_1.jpg
deleted
100644 → 0
{kind=link}

134 KB
imgs/face1_2.jpg
deleted
100644 → 0
{kind=link}

135 KB
imgs/face1_3.jpg
deleted
100644 → 0
{kind=link}

125 KB
imgs/face2_1.jpg
deleted
100644 → 0
{kind=link}

129 KB
imgs/face2_2.jpg
deleted
100644 → 0
{kind=link}

118 KB
imgs/face2_3.jpg
deleted
100644 → 0
{kind=link}

164 KB
imgs/face_short.gif
deleted
100644 → 0
{kind=link}
1.43 MB
imgs/teaser_720.gif
deleted
100644 → 0
{kind=link}

7.99 MB
{kind=link}

8.84 MB
{kind=link}

465 KB
imgs/teaser_ours.jpg
deleted
100644 → 0
{kind=link}

657 KB
{kind=link}
This image diff could not be displayed because it is too large. You can view the blob instead.
pix2pixHD_README.md
deleted
100644 → 0