
Initial commit
Showing
Dockerfile
0 → 100644
README.md
0 → 100644
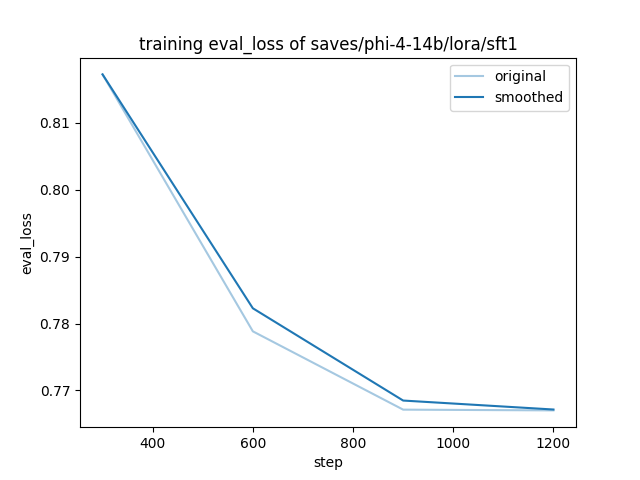
assets/result.png
0 → 100644
{kind=link}

133 KB
{kind=link}
32.8 KB
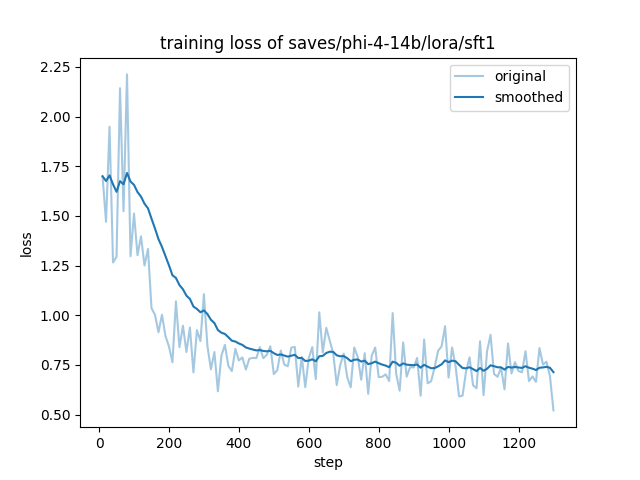
assets/training_loss.png
0 → 100644
{kind=link}
47.6 KB
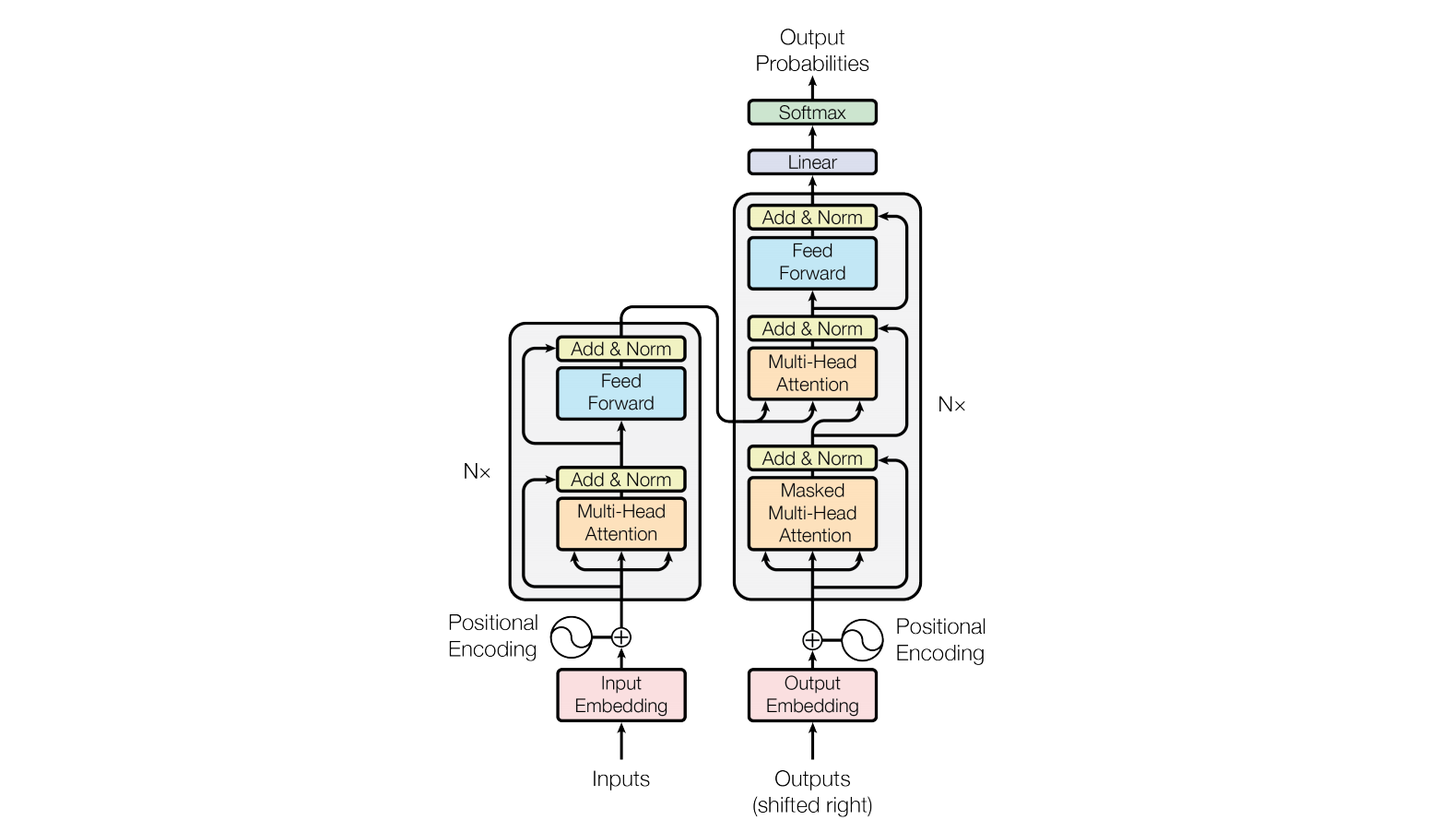
assets/transfomer.png
0 → 100644
{kind=link}
162 KB
icon.png
0 → 100644
{kind=link}
53.8 KB
inference/phi_multi_infer.py
0 → 100644
model.properties
0 → 100644
phi-4_lora_sft.yaml
0 → 100644