
particlenet
Showing
.gitignore
0 → 100644
Dockerfile
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_official.md
0 → 100644
icon.png
0 → 100644
{kind=link}
79 KB
model.properties
0 → 100644
mxnet/particle_net.py
0 → 100644
readme_imgs/arch.png
0 → 100644
{kind=link}
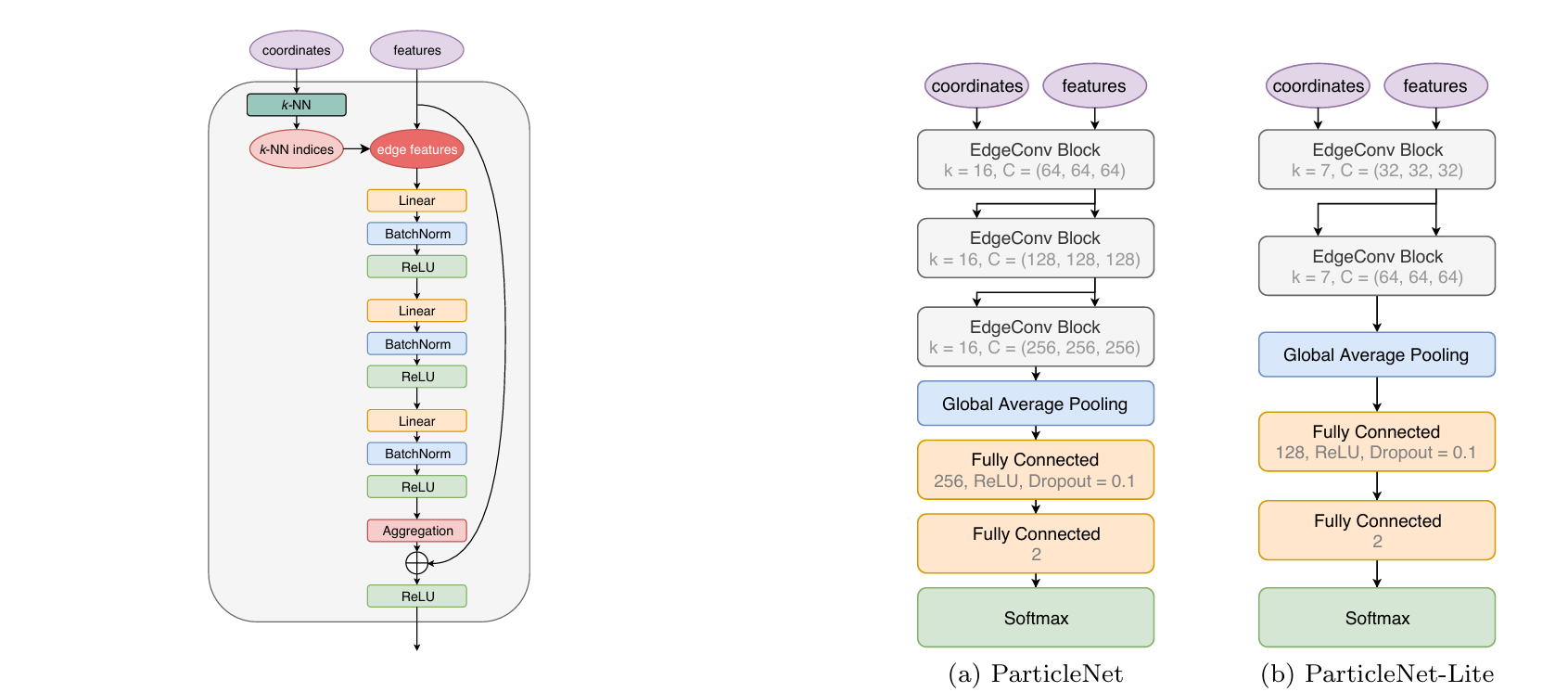
133 KB
tf-keras/keras_train.ipynb
0 → 100644
tf-keras/requirements.txt
0 → 100644
tf-keras/tf_keras_model.py
0 → 100644