
particle
Showing
.gitignore
0 → 100644
Dockerfile
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_official.md
0 → 100644
data/QuarkGluon/qg_kin.yaml
0 → 100644
dataloader.py
0 → 100755
env.sh
0 → 100644
figures/arch.png
0 → 100644
{kind=link}
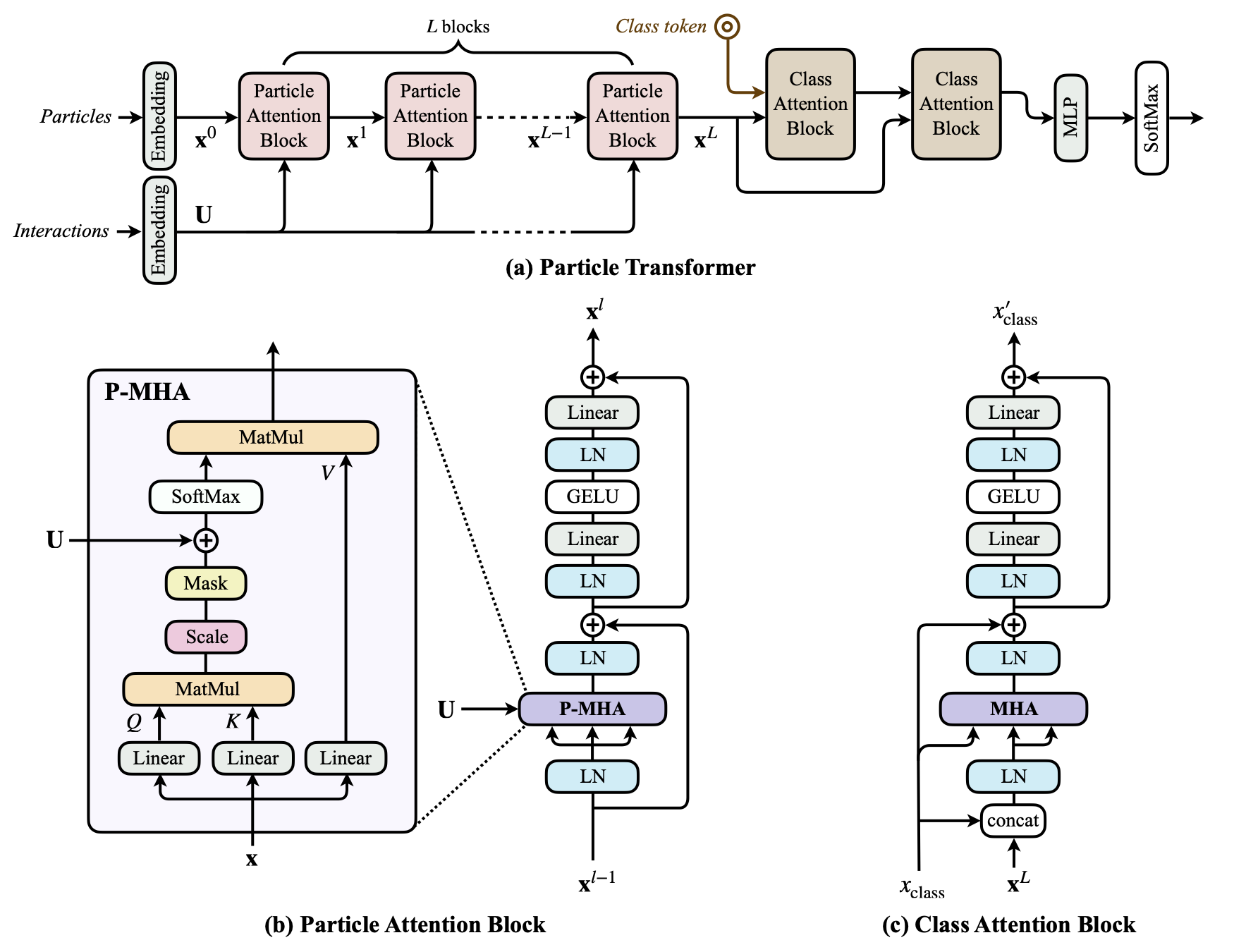
271 KB
figures/dataset.png
0 → 100644
{kind=link}
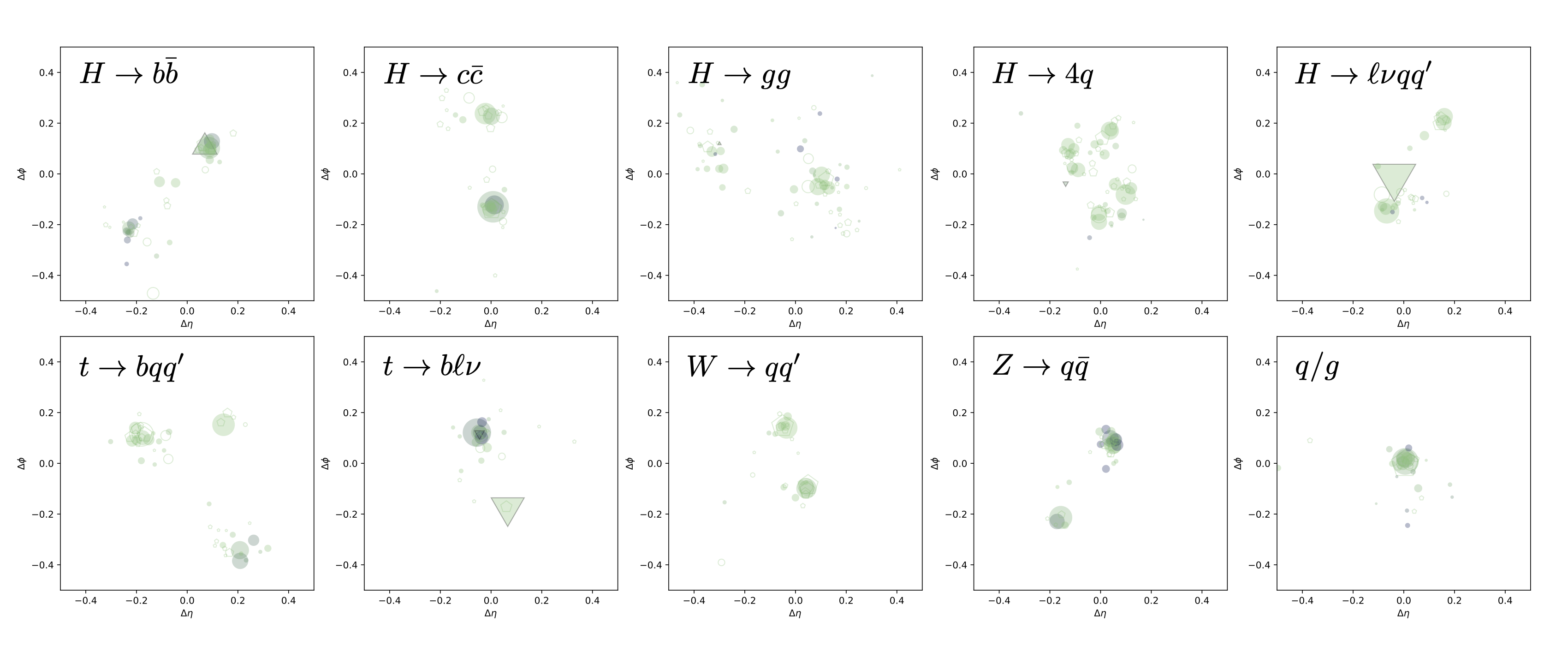
366 KB
figures/jet-tagging.png
0 → 100644
{kind=link}

359 KB
get_datasets.py
0 → 100755
icon.png
0 → 100644
{kind=link}
79 KB
model.properties
0 → 100644