Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
PaddleOCR_migraphx
Commits
b4b09312
Commit
b4b09312
authored
Oct 16, 2023
by
liucong
Browse files
修改paddleocr工程格式
parent
66a8f1a9
Changes
6
Hide whitespace changes
Inline
Side-by-side
Showing
6 changed files
with
110 additions
and
43 deletions
+110
-43
Doc/Images/SVTR-arc.png
Doc/Images/SVTR-arc.png
+0
-0
Doc/Images/dbnet-arc.png
Doc/Images/dbnet-arc.png
+0
-0
Doc/Images/vlpr.jpg
Doc/Images/vlpr.jpg
+0
-0
Doc/Tutorial_Cpp.md
Doc/Tutorial_Cpp.md
+5
-1
Doc/Tutorial_Python.md
Doc/Tutorial_Python.md
+26
-4
README.md
README.md
+79
-38
No files found.
Doc/Images/SVTR-arc.png
0 → 100644
View file @
b4b09312
303 KB
Doc/Images/dbnet-arc.png
0 → 100644
View file @
b4b09312
230 KB
Doc/Images/vlpr.jpg
0 → 100644
View file @
b4b09312
85.1 KB
Doc/Tutorial_Cpp.md
View file @
b4b09312
...
...
@@ -122,7 +122,7 @@ ErrorCode DB::Infer(const cv::Mat &img, std::vector<cv::Mat> &imgList)
...
```
## SVTR预处理
##
#
SVTR预处理
SVTR模型的输入图像是DB模型检测输出裁剪的车牌区域,将裁剪图像输入到识别模型前,需要做如下预处理:
...
...
@@ -196,6 +196,10 @@ ErrorCode DB::Infer(const cv::Mat &img, std::vector<cv::Mat> &imgList)
// 推理
std::vector<migraphx::argument> inferenceResults = net.eval(inputData);
// 如果想要指定输出节点,可以给eval()函数中提供outputNames参数来实现
//std::vector<std::string> outputNames = {"sigmoid_0.tmp_0"};
//std::vector<migraphx::argument> inferenceResults = net.eval(inputData, outputNames);
// 获取推理结果
migraphx::argument result = inferenceResults[0];
...
...
Doc/Tutorial_Python.md
View file @
b4b09312
...
...
@@ -69,9 +69,20 @@ class det_rec_functions(object):
# 解析检测模型
detInput = {"x":[1,3,2496,2496]}
self.modelDet = migraphx.parse_onnx(self.det_file, map_input_dims=detInput)
# 获取模型输入/输出节点信息
print("det_inputs:")
inputs_det = self.modelDet.get_inputs()
for key,value in inputs_det.items():
print("{}:{}".format(key,value))
print("det_outputs:")
outputs_det = self.modelDet.get_outputs()
for key,value in outputs_det.items():
print("{}:{}".format(key,value))
self.inputName = self.modelDet.get_parameter_names()[0]
self.inputShape = self.modelDet.get_parameter_shapes()[self.inputName].lens()
self.inputShape = inputs_det[self.inputName].lens()
print("DB inputName:{0} \nDB inputShape:{1}".format(self.inputName, self.inputShape))
# 模型编译
...
...
@@ -81,9 +92,20 @@ class det_rec_functions(object):
# 解析识别模型
recInput = {"x":[1,3,48,320]}
self.modelRec = migraphx.parse_onnx(self.rec_file, map_input_dims=recInput)
self.inputName = self.modelRec.get_parameter_names()[0]
self.inputShape = self.modelRec.get_parameter_shapes()[self.inputName].lens()
# 获取模型输入/输出节点信息
print("rec_inputs:")
inputs_rec = self.modelRec.get_inputs()
for key,value in inputs_rec.items():
print("{}:{}".format(key,value))
print("rec_outputs:")
outputs_rec = self.modelRec.get_outputs()
for key,value in outputs_rec.items():
print("{}:{}".format(key,value))
self.inputName = self.modelRec.get_parameter_names()[0]
self.inputShape = inputs_rec[self.inputName].lens()
print("SVTR inputName:{0} \nSVTR inputShape:{1}".format(self.inputName, self.inputShape))
# 模型编译
...
...
README.md
View file @
b4b09312
# PaddleOCR车牌识别
##
模型介绍
##
论文
车牌识别(Vehicle License Plate Recognition,VLPR) 是计算机视频图像识别技术在车辆牌照识别中的一种应用。车牌识别技术要求能够将运动中的汽车牌照从复杂背景中提取并识别出来,在高速公路车辆管理,停车场管理和城市交通中得到广泛应用。PaddleOCR车牌识别包括本文检测和文本识别两部分内容,其中使用DBnet作为文本检测模型,SVTR作为文本识别模型。车牌识别过程:输入->图像预处理->文字检测->文本识别->输出。
PaddleOCR通过det、rec、cls三个模型分别实现字符检测、字符识别和字符方向分类的应用
det模型主要用DB算法,参考论文如下:
https://arxiv.org/pdf/1911.08947.pdf
rec模型主要用SVTR算法,参考论文如下:
https://arxiv.org/pdf/2205.00159.pdf
## 模型结构
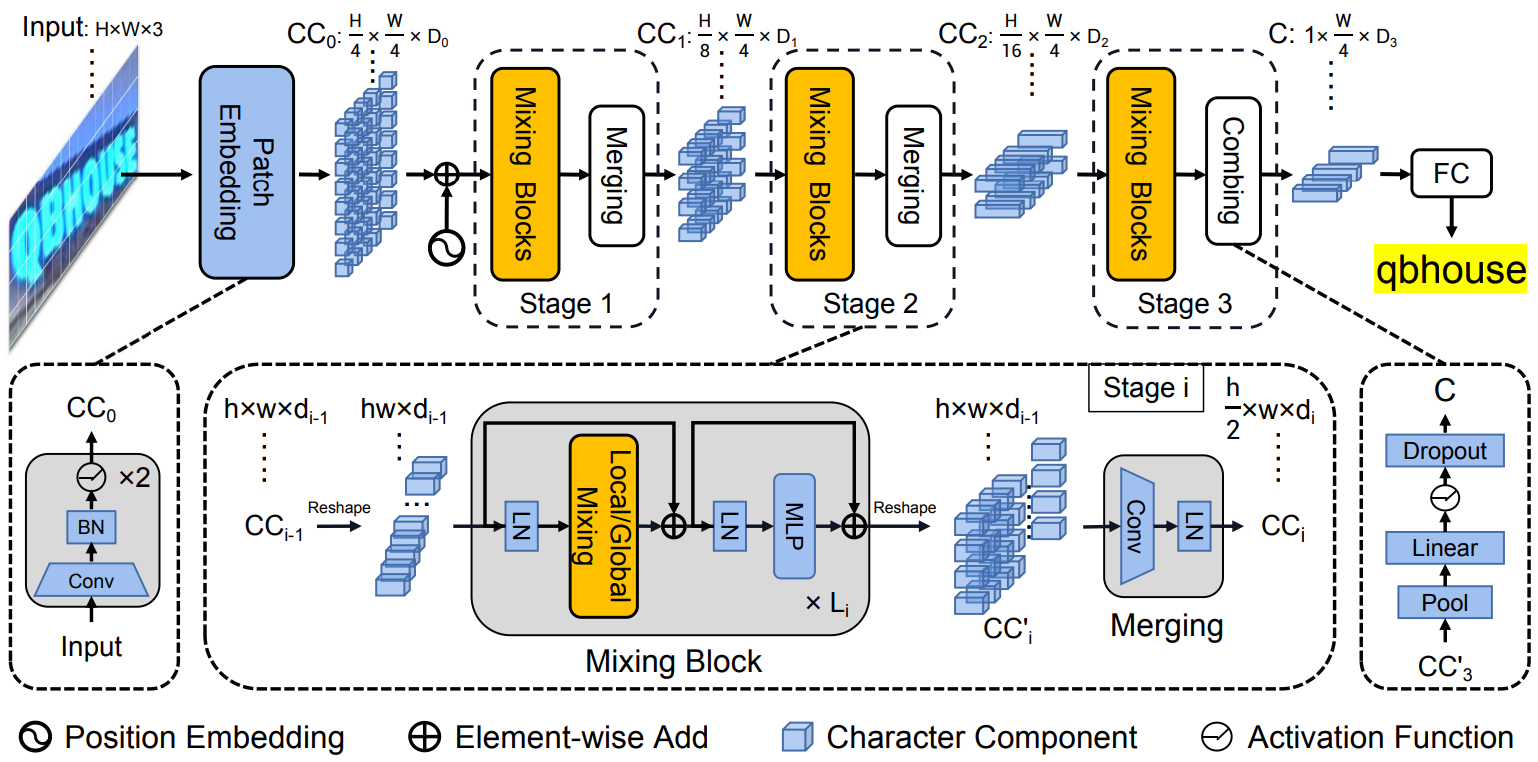
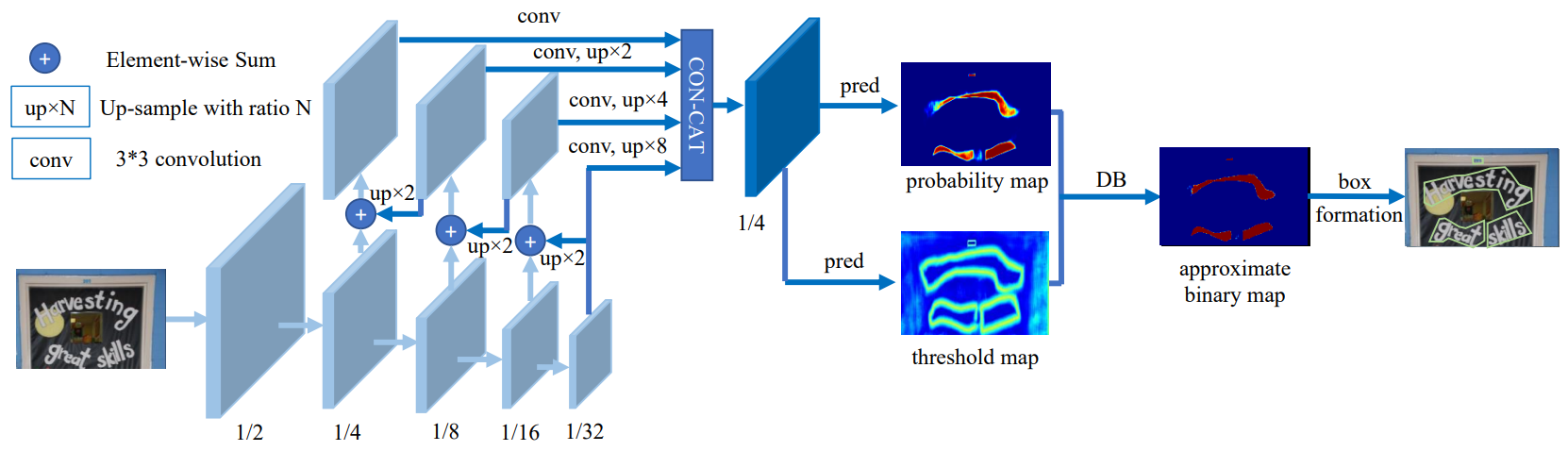
DBnet是一种基于分割的文本检测方法,相比传统分割方法需要设定固定阈值,该模型将二值化操作插入到分割网络中进行联合优化,通过网络学习可以自适应的预测图像中每一个像素点的阈值,能够在像素水平很好的检测自然场景下不同形状的文字。SVTR是一种端到端的文本识别模型,通过单个视觉模型就可以一站式解决特征提取和文本转录两个任务,同时也保证了更快的推理速度。百度PaddleOCR开源项目提供了车牌识别的预训练模型,本示例使用PaddleOCR提供的蓝绿黄牌识别模型进行推理。
det:
## Python版本推理
<img
src=
"./Doc/Images/dbnet-arc.png"
style=
"zoom:100%;"
align=
middle
>
下面介绍如何运行Python代码示例,Python示例的详细说明见Doc目录下的Tutorial_Python.md。
rec:
### 下载镜像
<img
src=
"./Doc/Images/SVTR-arc.png"
style=
"zoom:100%;"
align=
middle
>
在光源可拉取推理的docker镜像,PaddleOCR工程推荐的镜像如下:
## 算法原理
```
python
docker
pull
sugonhub
/
migraphx
:
3.2
.
1
-
centos7
.
6
-
dtk
-
23.04
.
1
-
py38
```
百度PaddleOCR开源项目提供了车牌识别的预训练模型,本示例使用PaddleOCR提供的蓝绿黄牌识别模型进行推理。其中,DBnet是一种基于分割的文本检测方法,相比传统分割方法需要设定固定阈值,该模型将二值化操作插入到分割网络中进行联合优化,通过网络学习可以自适应的预测图像中每一个像素点的阈值,能够在像素水平很好的检测自然场景下不同形状的文字。SVTR是一种端到端的文本识别模型,通过单个视觉模型就可以一站式解决特征提取和文本转录两个任务,同时也保证了更快的推理速度。
### 设置Python环境变量
## 环境配置
### Docker
拉取镜像:
```
export PYTHONPATH=/opt/dtk/lib:$PYTHONPATH
docker pull sugonhub/migraphx:3.2.1-centos7.6-dtk-23.04.1-py38
```
### 安装依赖
创建并启动容器:
```
# 进入python示例目录
cd <path_to_paddleocr_migraphx>/Python
docker run --shm-size 16g --network=host --name=paddleocr_migraphx --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v $PWD/paddleocr_migraphx:/home/paddleocr_migraphx -it <Your Image ID> /bin/bash
#
安装依赖
pip install -r requirements.txt
#
激活dtk
source /opt/dtk/env.sh
```
##
# 运行示例
##
数据集
依赖安装成功之后,可在当前目录执行如下指令运行程序推理:
根据输入的样本图像,进行车牌识别。
```
# 运行示例程序
python PaddleOCR_infer_migraphx.py
```
## 推理
### Python版本推理
下面介绍如何运行Python代码示例,Python示例的详细说明见Doc目录下的Tutorial_Python.md。
PaddleOCR车牌识别结果为:
#### 设置环境变量
```
皖AD19906
export PYTHONPATH=/opt/dtk/lib:$PYTHONPATH
```
##
C++版本推理
##
##
运行示例
下面介绍如何运行C++代码示例,C++示例的详细说明见Doc目录下的Tutorial_Cpp.md。
### 下载镜像
```
# 进入python示例目录
cd <path_to_paddleocr_migraphx>/Python
在光源中下载MIGraphX镜像:
# 安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
docker pull sugonhub/migraphx:3.2.1-centos7.6-dtk-23.04.1-py38
# 运行示例
python PaddleOCR_infer_migraphx.py
```
### C++版本推理
### 构建工程
下面介绍如何运行C++代码示例,C++示例的详细说明见Doc目录下的Tutorial_Cpp.md。
#### 构建工程
```
rbuild build -d depend
```
### 设置环境变量
###
#
设置环境变量
将依赖库依赖加入环境变量LD_LIBRARY_PATH,在~/.bashrc中添加如下语句:
...
...
@@ -84,7 +99,7 @@ export LD_LIBRARY_PATH=<path_to_paddleocr_migraphx>/depend/lib64/:$LD_LIBRARY_PA
source ~/.bashrc
```
### 运行示例
###
#
运行示例
成功编译PaddleOCR车牌识别工程后,执行如下命令运行该示例:
...
...
@@ -99,16 +114,42 @@ cd ./build/
./PaddleOCR_VLPR
```
PaddleOCR车牌识别结果为:
## result
#### Python版本
输入样本图像,进行车牌识别:
<img
src=
"./Doc/Images/vlpr.jpg"
style=
"zoom:100%;"
align=
middle
>
```
皖AD19906
```
#### C++版本
输入样本图像,进行车牌识别:
<img
src=
"./Doc/Images/vlpr.jpg"
style=
"zoom:100%;"
align=
middle
>
```
皖AD19906
```
## 应用场景
### 算法类别
`ocr`
### 热点应用行业
`工业制造`
、
`金融`
、
`交通`
、
`教育`
、
`医疗`
## 源码仓库及问题反馈
https://developer.hpccube.com/codes/modelzoo/paddleocr_migraphx
https://developer.hpccube.com/codes/modelzoo/paddleocr_migraphx
## 参考
https://github.com/PaddlePaddle/PaddleOCR
https://github.com/PaddlePaddle/PaddleOCR
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}
{kind=link}
