
Add results and Update README
Showing
Contributors.md
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
doc/PaddleOCR-VL.pdf
0 → 100644
File added
doc/method.png
0 → 100644
{kind=link}
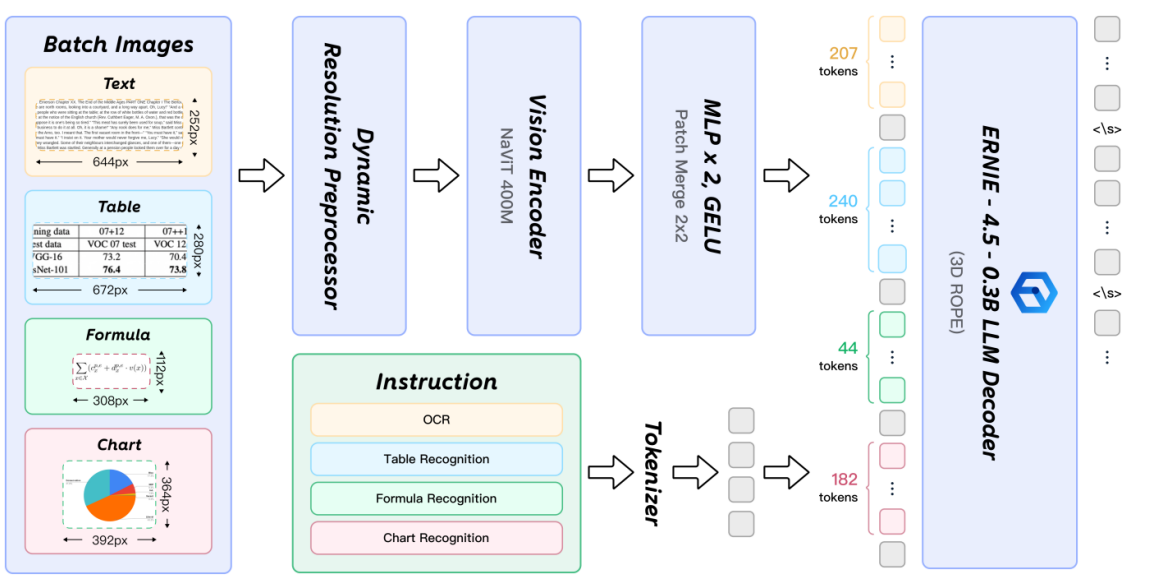
176 KB
doc/model.png
0 → 100644
{kind=link}
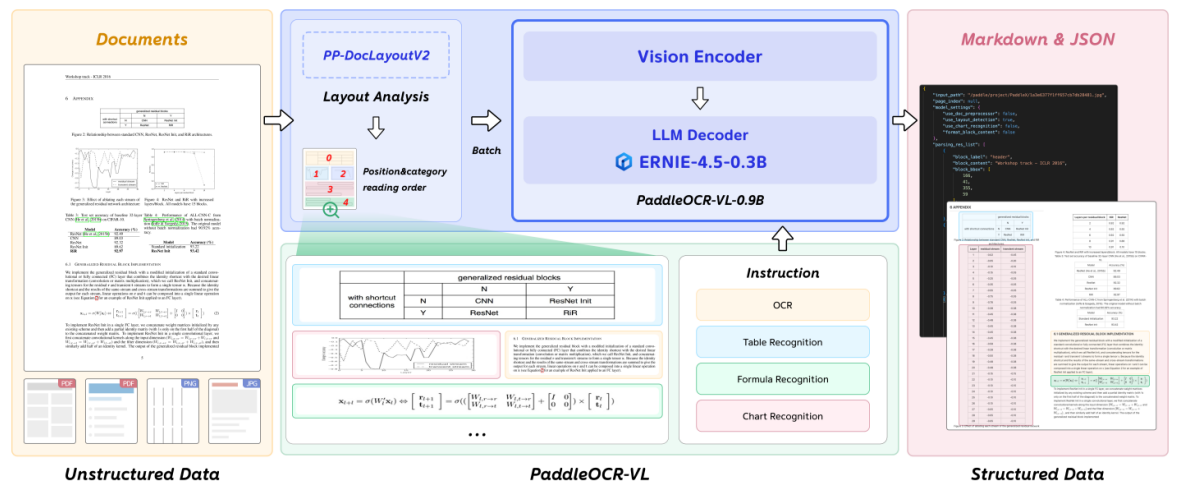
203 KB
doc/paddleocr_vl_demo.png
0 → 100644
{kind=link}

2.22 MB
doc/result-dcu.png
0 → 100644
{kind=link}
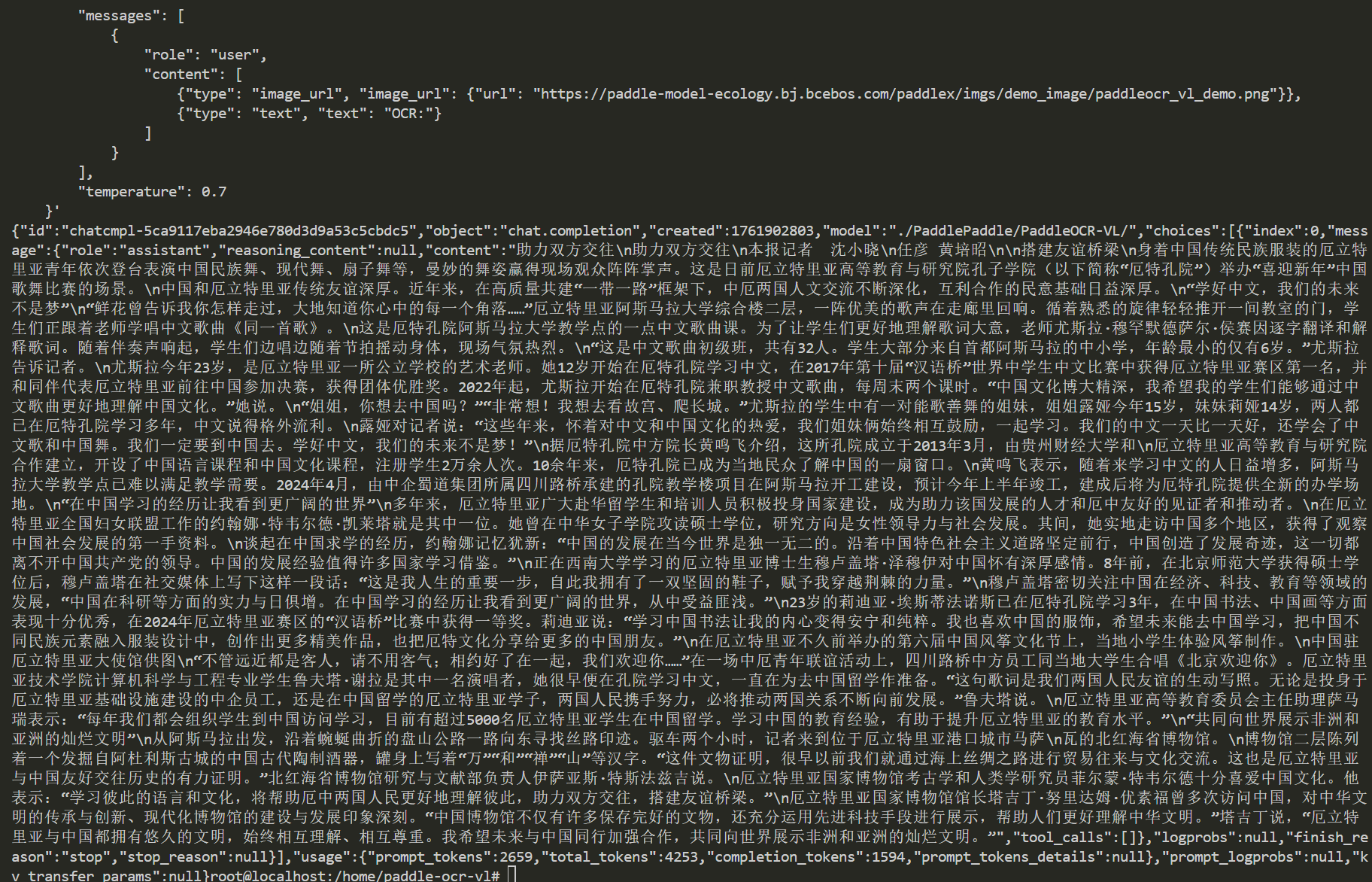
647 KB
doc/钢笔中文手写_000050_crop_9.jpg
0 → 100644
{kind=link}

20.6 KB
docker/Dockerfile
0 → 100644
icon.png
0 → 100644
{kind=link}
61 KB
model.properties
0 → 100644
paddleocr-vl-image.py
0 → 100644
paddleocr-vl-pdf.py
0 → 100644
requirements.txt
0 → 100644
| shapely | ||
| scikit-image | ||
| pyclipper | ||
| lmdb | ||
| tqdm | ||
| numpy | ||
| rapidfuzz | ||
| opencv-python | ||
| opencv-contrib-python | ||
| cython | ||
| Pillow | ||
| pyyaml | ||
| requests | ||
| albumentations | ||
| # to be compatible with albumentations | ||
| albucore | ||
| packaging |