
ootdiffusion
Showing
.gitignore
0 → 100644
Dockerfile
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_official.md
0 → 100644
demo/ff.jpg
0 → 100644
{kind=link}

12.2 KB
demo/image.png
0 → 100644
{kind=link}

148 KB
demo/mc.jpg
0 → 100644
{kind=link}

103 KB
demo/qz.jpg
0 → 100644
{kind=link}

19.9 KB
images/demo.png
0 → 100644
{kind=link}

4.05 MB
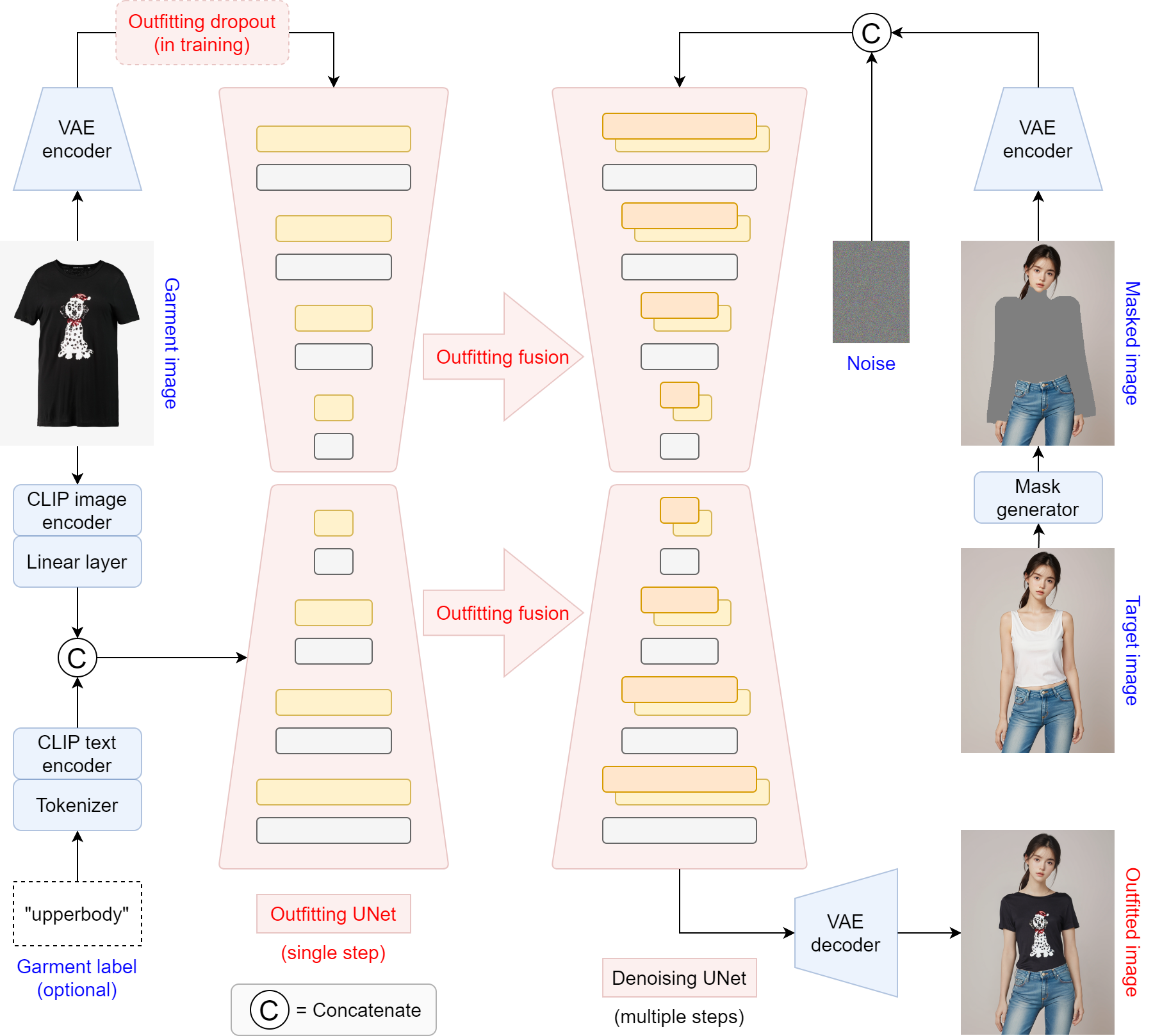
images/workflow.png
0 → 100644
{kind=link}
731 KB
model.properties
0 → 100644
ootd/__init__.py
0 → 100644
ootd/inference_ootd.py
0 → 100644
ootd/inference_ootd_dc.py
0 → 100644
ootd/inference_ootd_hd.py
0 → 100644
This diff is collapsed.