
omnisql
Showing
.gitignore
0 → 100644
Dockerfile
0 → 100644
README.md
0 → 100644
assets/framework.png
0 → 100644
{kind=link}
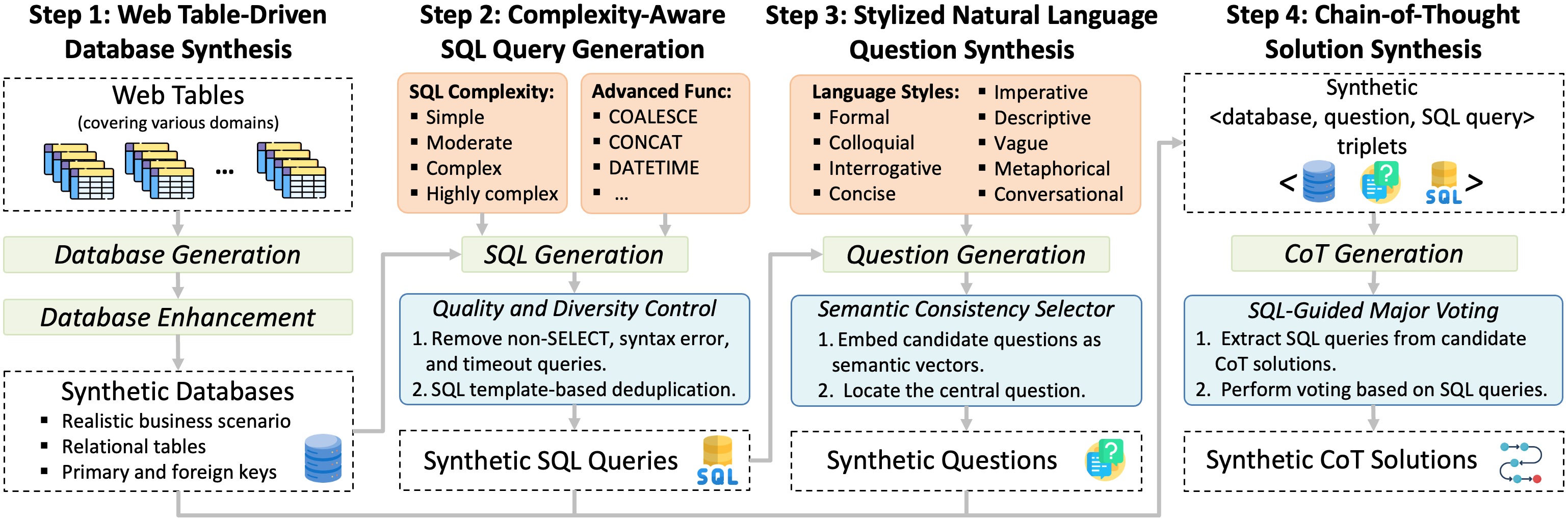
447 KB
assets/main_results.png
0 → 100644
{kind=link}
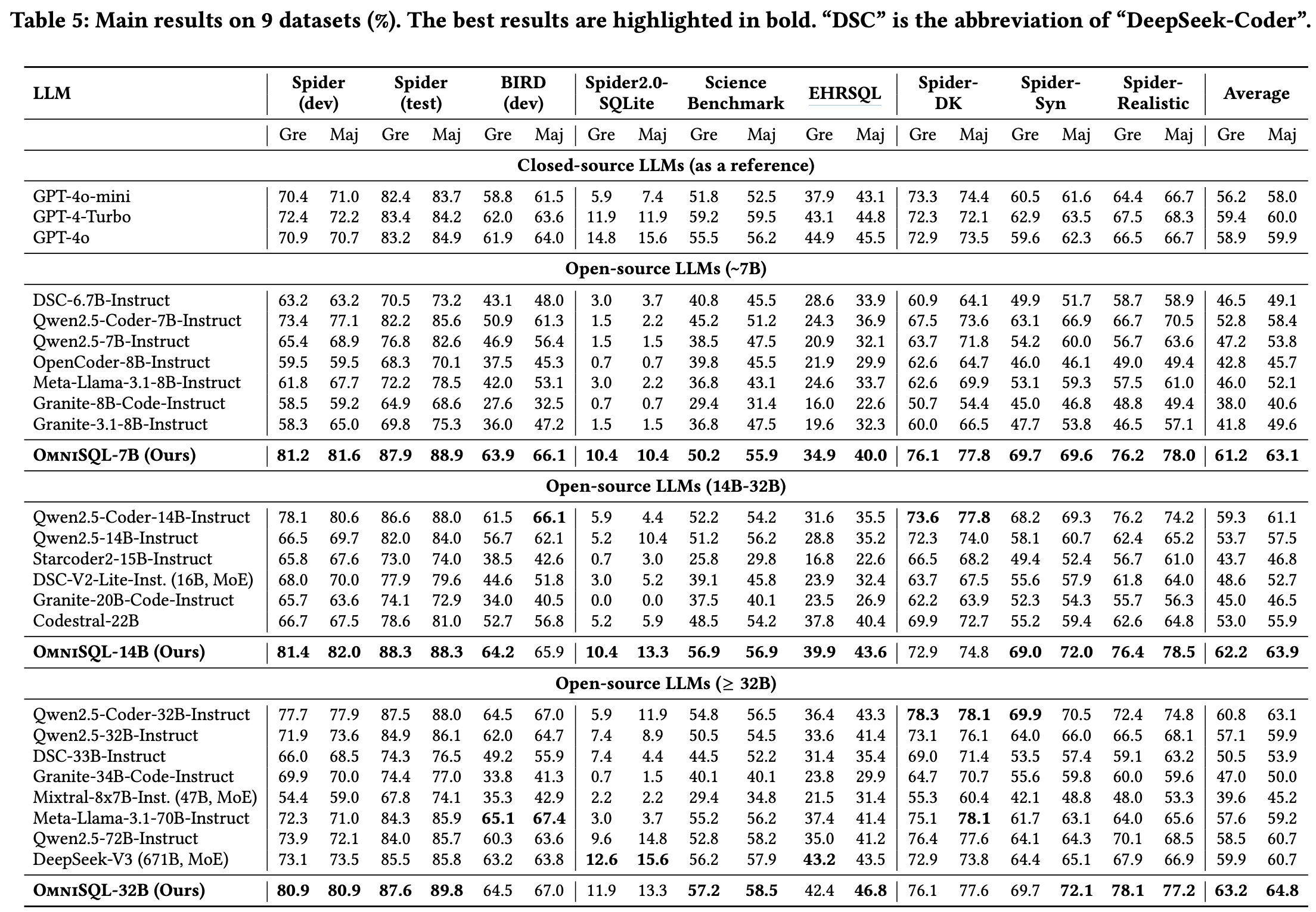
590 KB
data_synthesis/README.md
0 → 100644