
add preprocessing
Showing
preprocessing/RAFT/LICENSE
0 → 100644
preprocessing/RAFT/RAFT.png
0 → 100644
{kind=link}
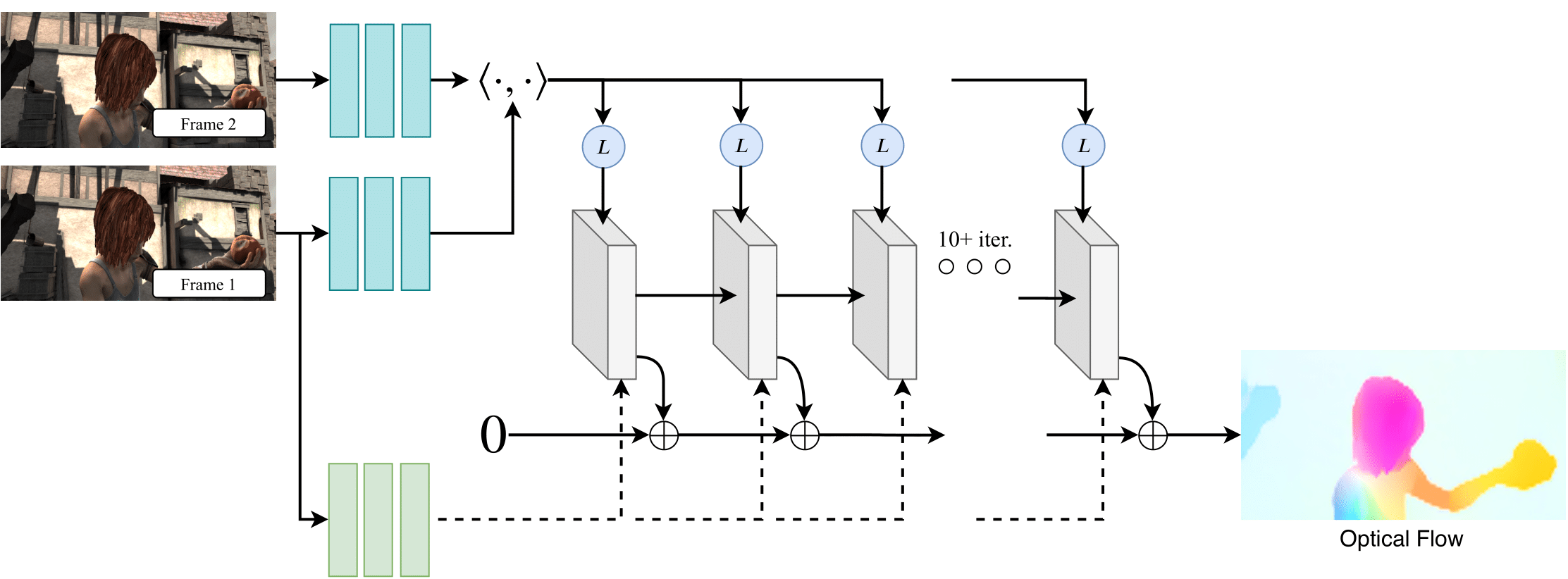
199 KB
preprocessing/RAFT/README.md
0 → 100644
File added
This diff is collapsed.
File added
File added
File added
File added