
v1.0.1
Showing
{kind=link}
115 KB
{kind=link}
183 KB
{kind=link}
997 KB
{kind=link}
230 KB
{kind=link}
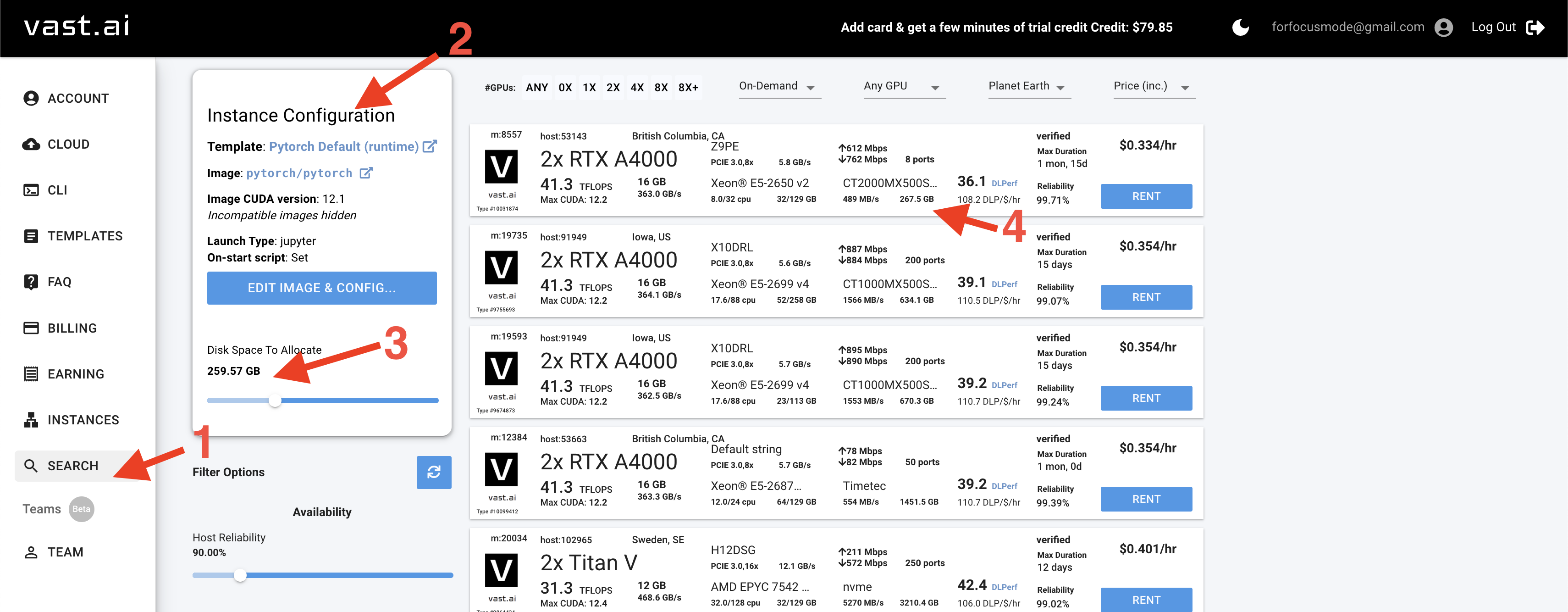
663 KB
{kind=link}
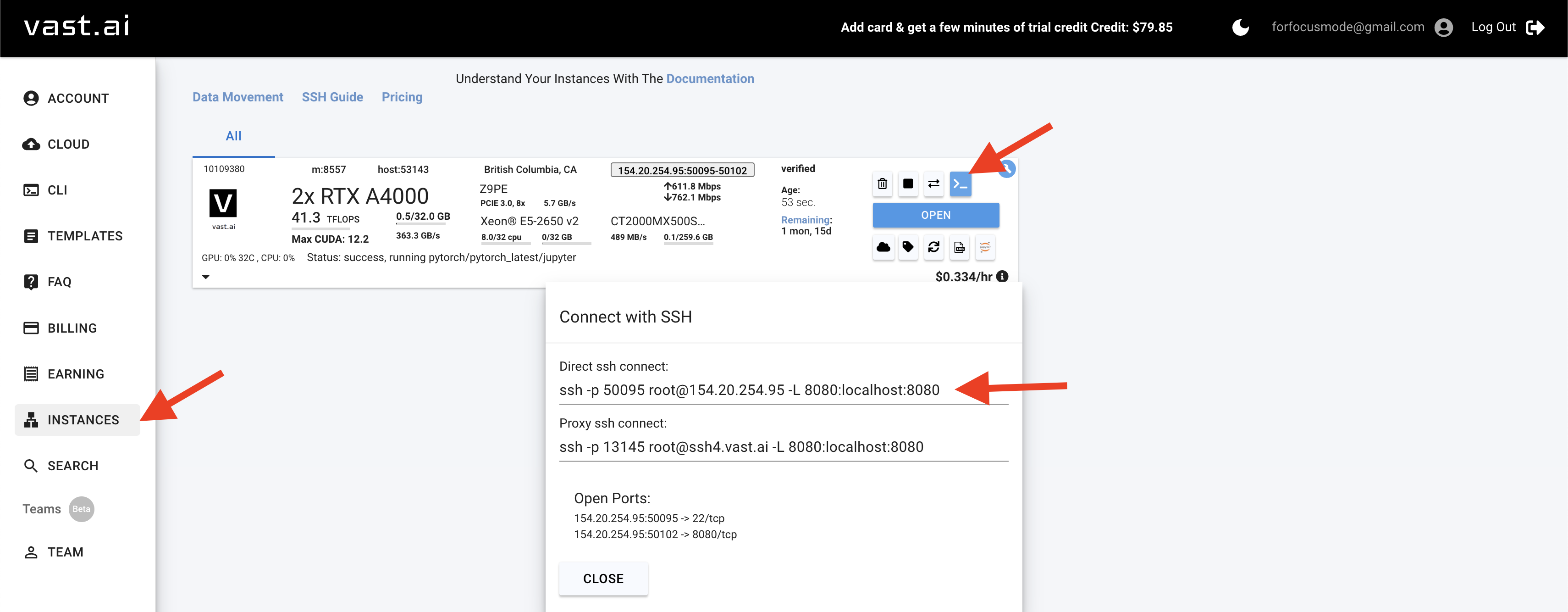
379 KB
{kind=link}
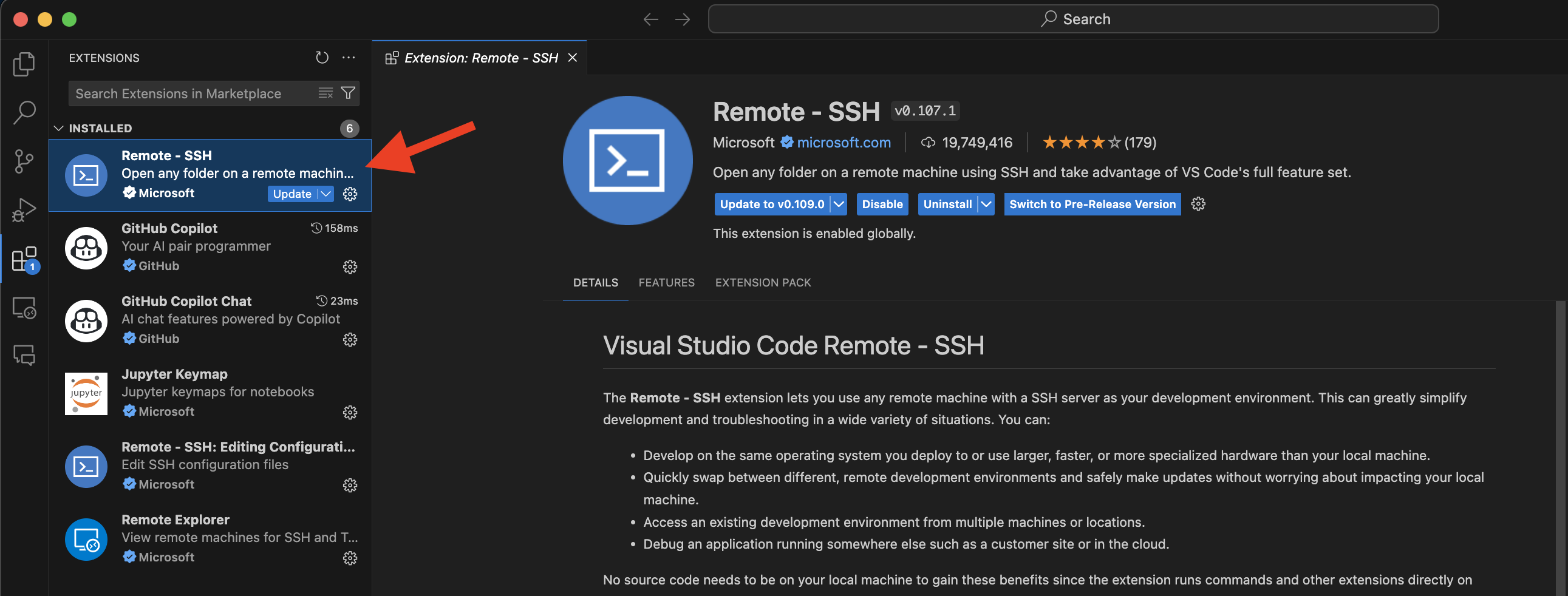
354 KB
{kind=link}
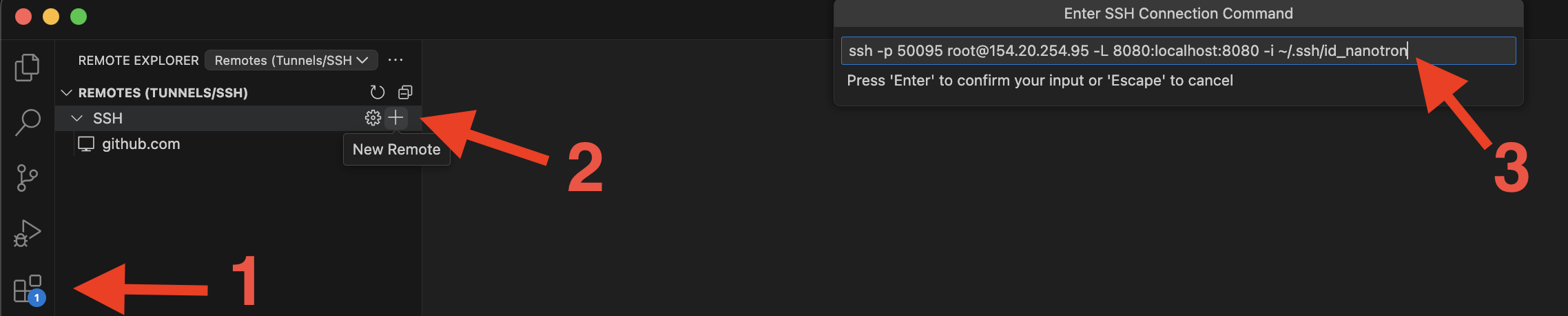
97.1 KB
{kind=link}
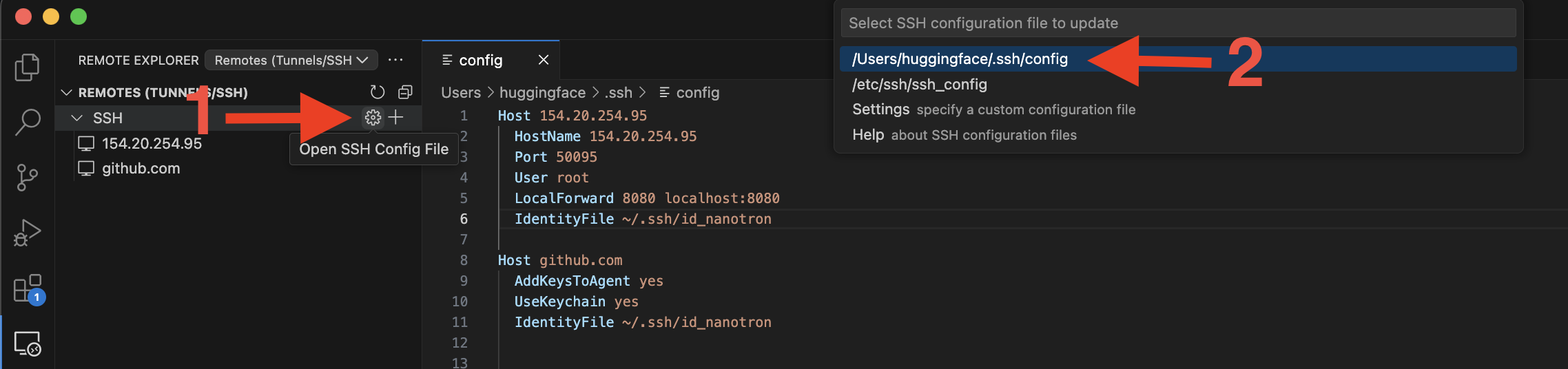
163 KB
{kind=link}
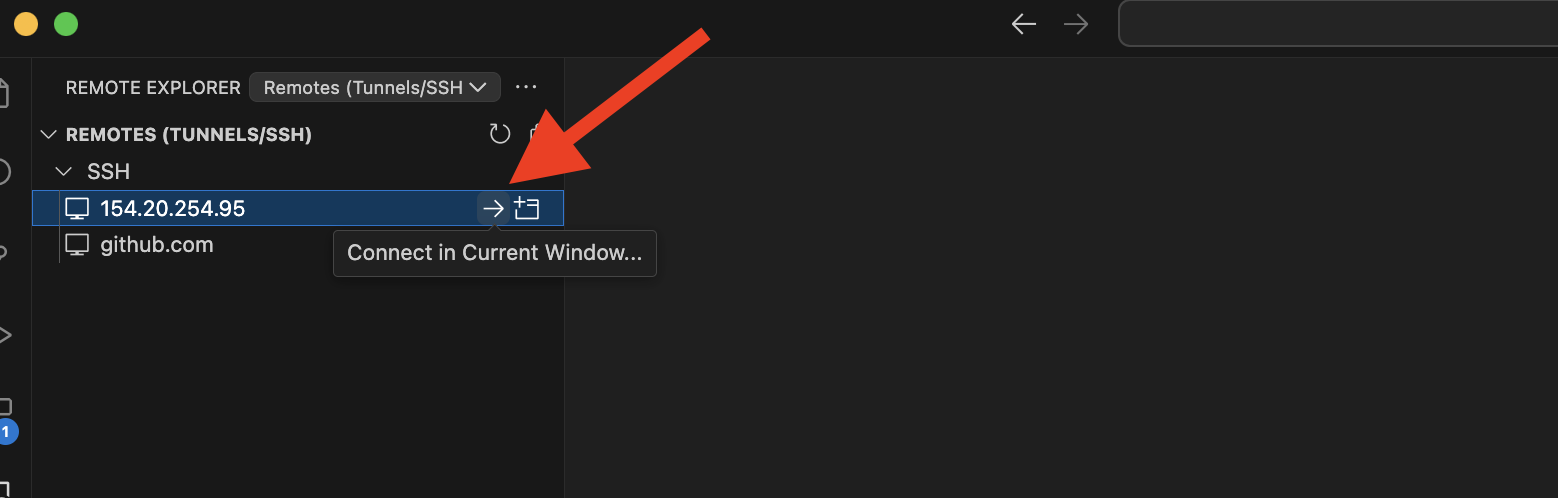
56.6 KB
{kind=link}

78.1 KB
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.