
Initial commit
Showing
DocLocal4K/.gitattributes
0 → 100644
DocLocal4K/README.md
0 → 100644
DocLocal4K/mini_imges.jsonl
0 → 100644
This diff is collapsed.
This diff is collapsed.
README.md
0 → 100644
README_mPLUG.md
0 → 100644
File added
app.py
0 → 100644
{kind=link}
assets/doc_instruct.png
0 → 100644
{kind=link}

1.82 MB
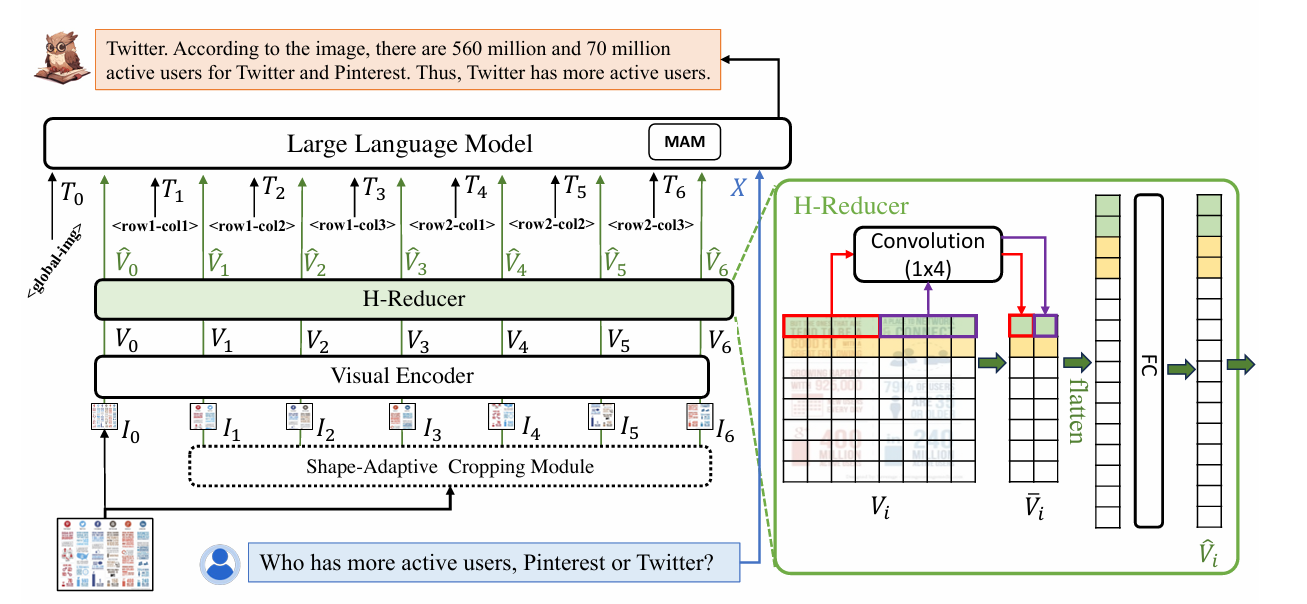
assets/model_strcuture.png
0 → 100644
{kind=link}
177 KB
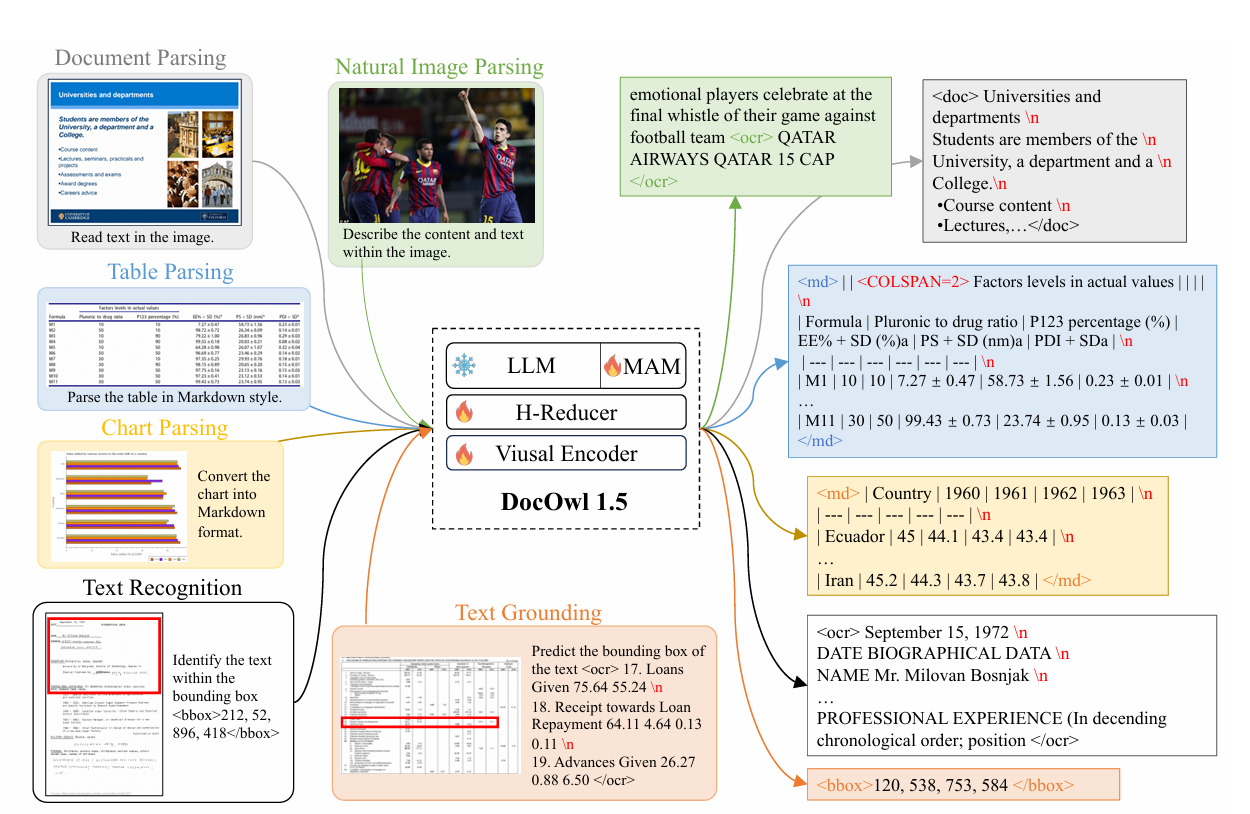
assets/model_theory.png
0 → 100644
{kind=link}
381 KB
assets/modelscope.png
0 → 100644
{kind=link}

10.7 KB
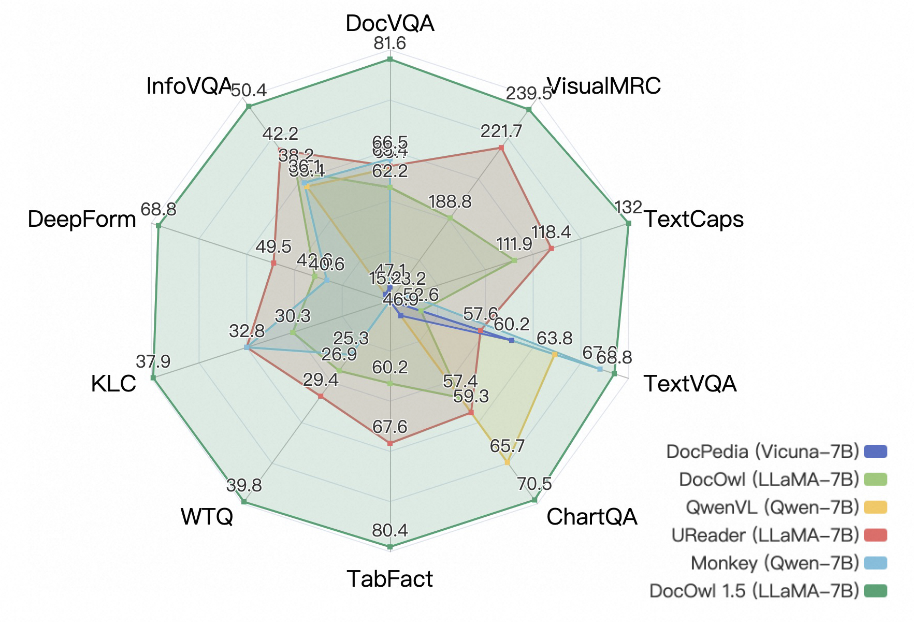
assets/radar.png
0 → 100644
{kind=link}
565 KB
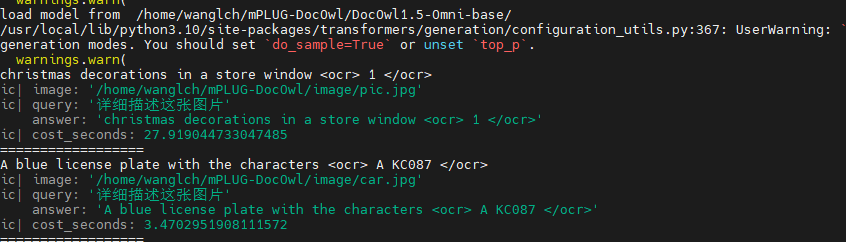
assets/result.jpg
0 → 100644
{kind=link}
25 KB