
Initial commit
Showing
.gitconfig
0 → 100644
.gitignore
0 → 100644
LICENSE.md
0 → 100644
README.md
0 → 100644
demo/app.py
0 → 100644
demo/app_s2s.py
0 → 100644
demo/resources/MTLogo.png
0 → 100644
{kind=link}

45.6 KB
demo/resources/demo-en.wav
0 → 100644
File added
demo/resources/demo.wav
0 → 100644
File added
{kind=link}

19.4 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
hostfile
0 → 100644
icon.png
0 → 100644
{kind=link}
68.4 KB
images/asr-and-ast.png
0 → 100644
{kind=link}
534 KB
images/model_structure.png
0 → 100644
{kind=link}
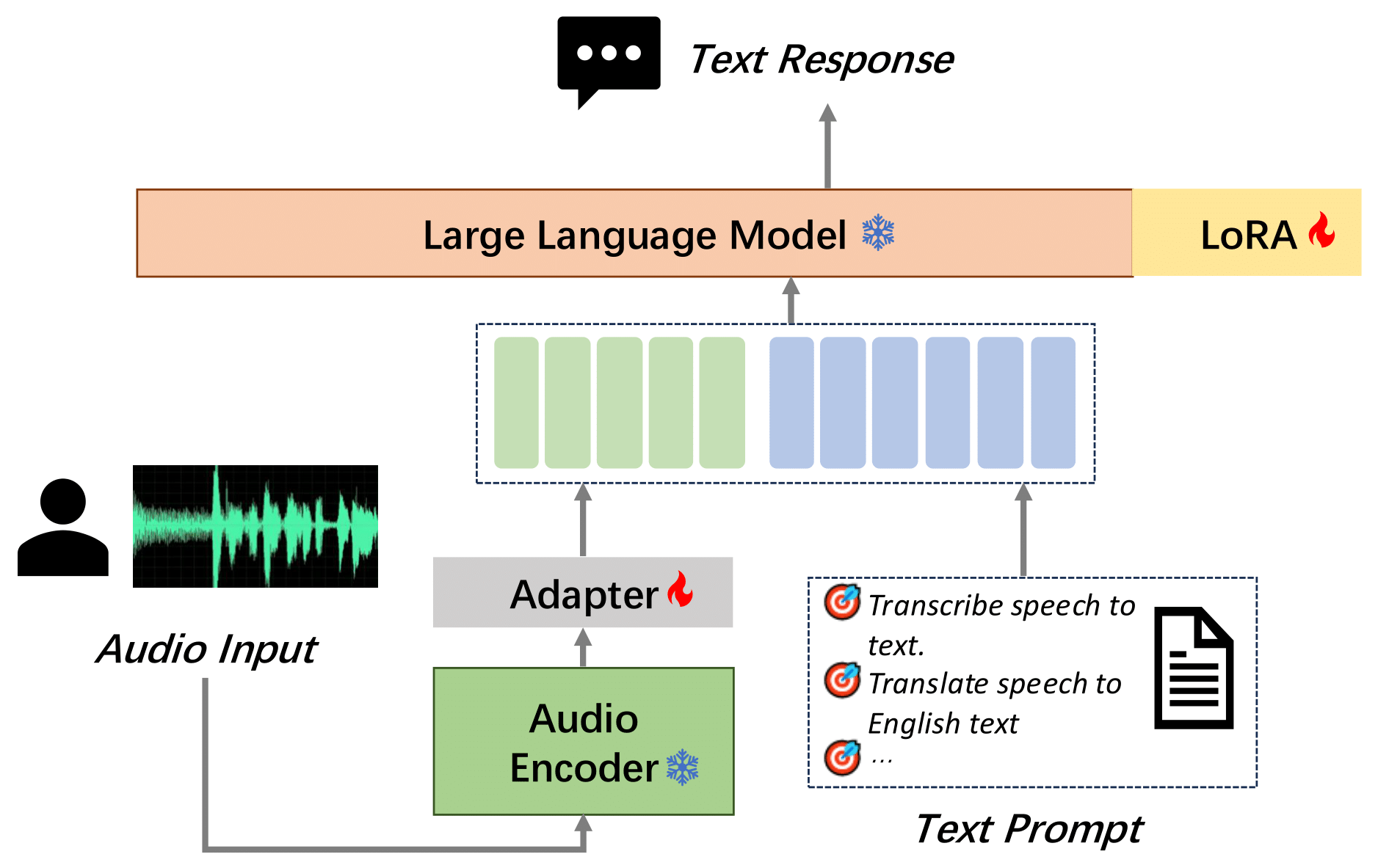
283 KB
images/only-asr.png
0 → 100644
{kind=link}
541 KB
images/only-ast.png
0 → 100644
{kind=link}
555 KB
inference.py
0 → 100644
inference.sh
0 → 100644