
v1.0
parents
Showing
LICENSE
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
This diff is collapsed.
assets/READMEv1.md
0 → 100644
assets/mobilevlm_arch.png
0 → 100644
{kind=link}
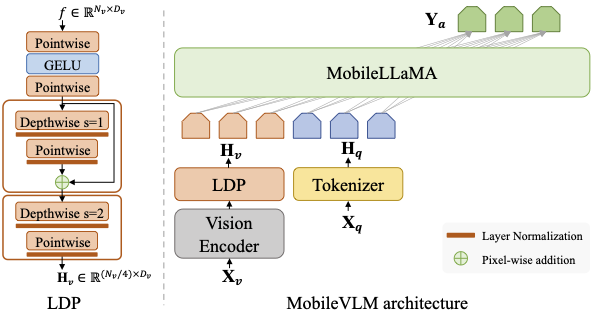
51.2 KB
assets/mobilevlm_v2_arch.png
0 → 100644
{kind=link}
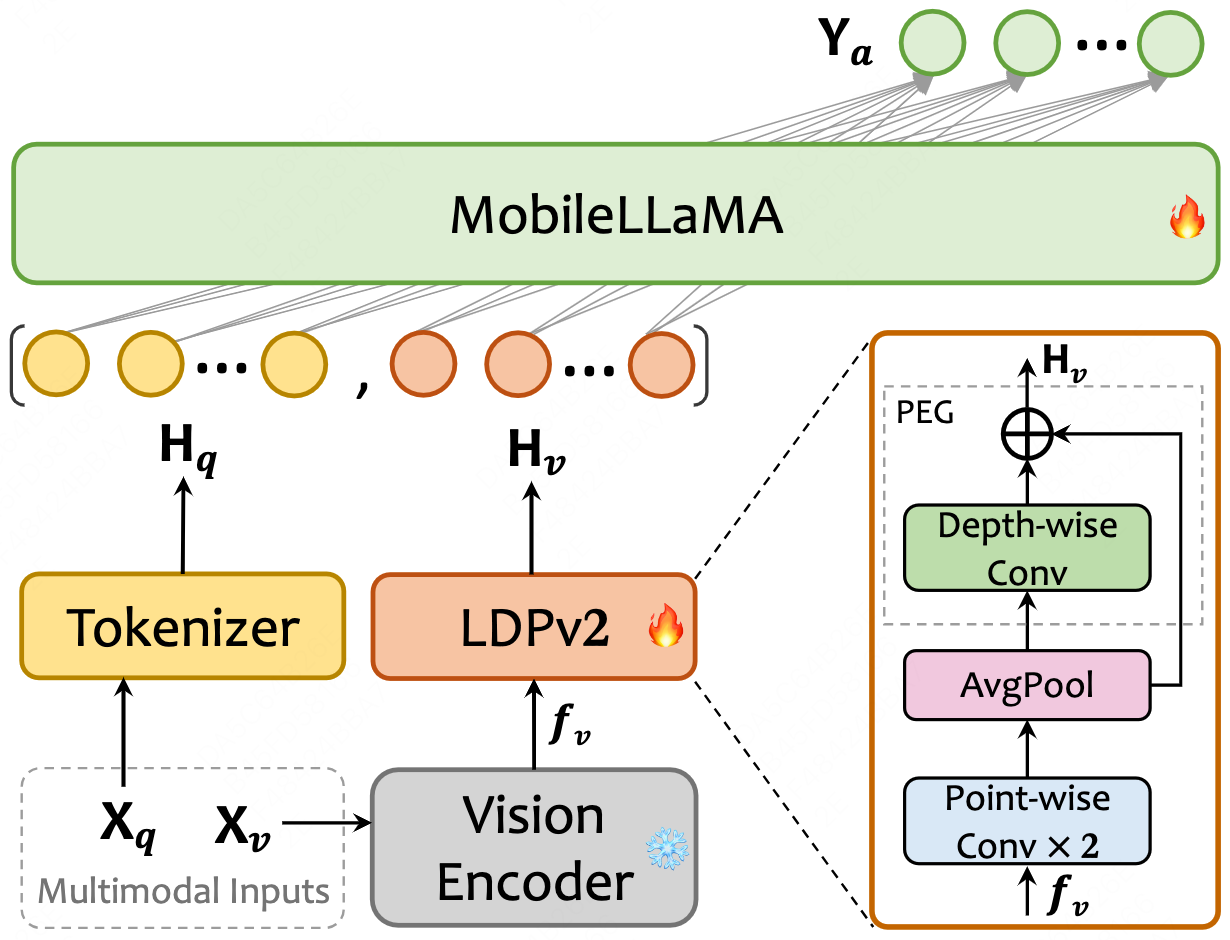
222 KB
assets/samples/demo.jpg
0 → 100644
{kind=link}

28.2 KB
doc/clip.png
0 → 100644
{kind=link}
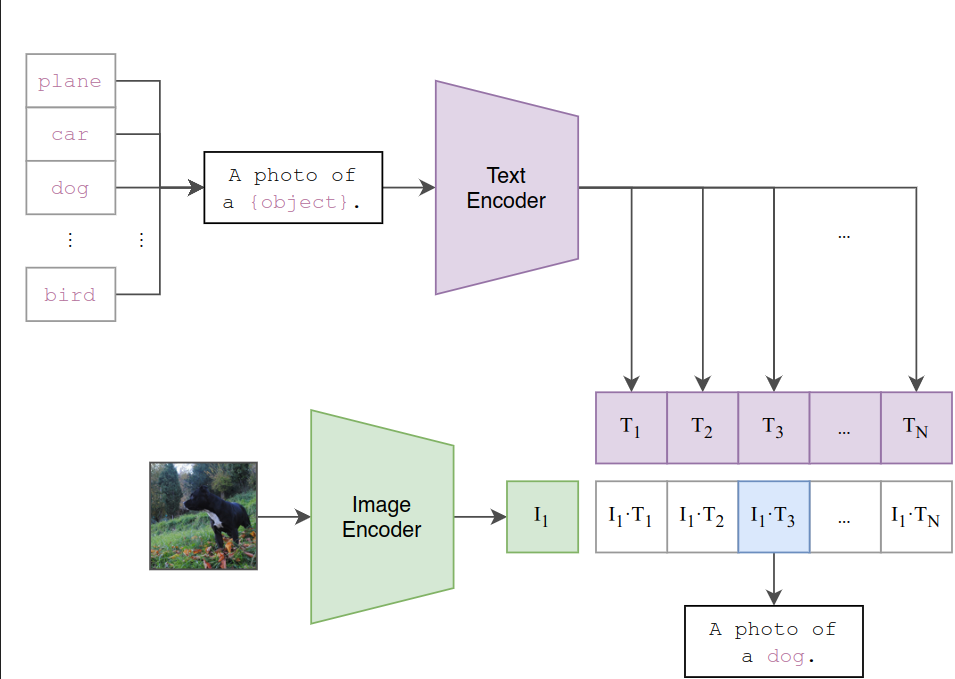
56.4 KB
doc/mobilevlm.png
0 → 100644
{kind=link}
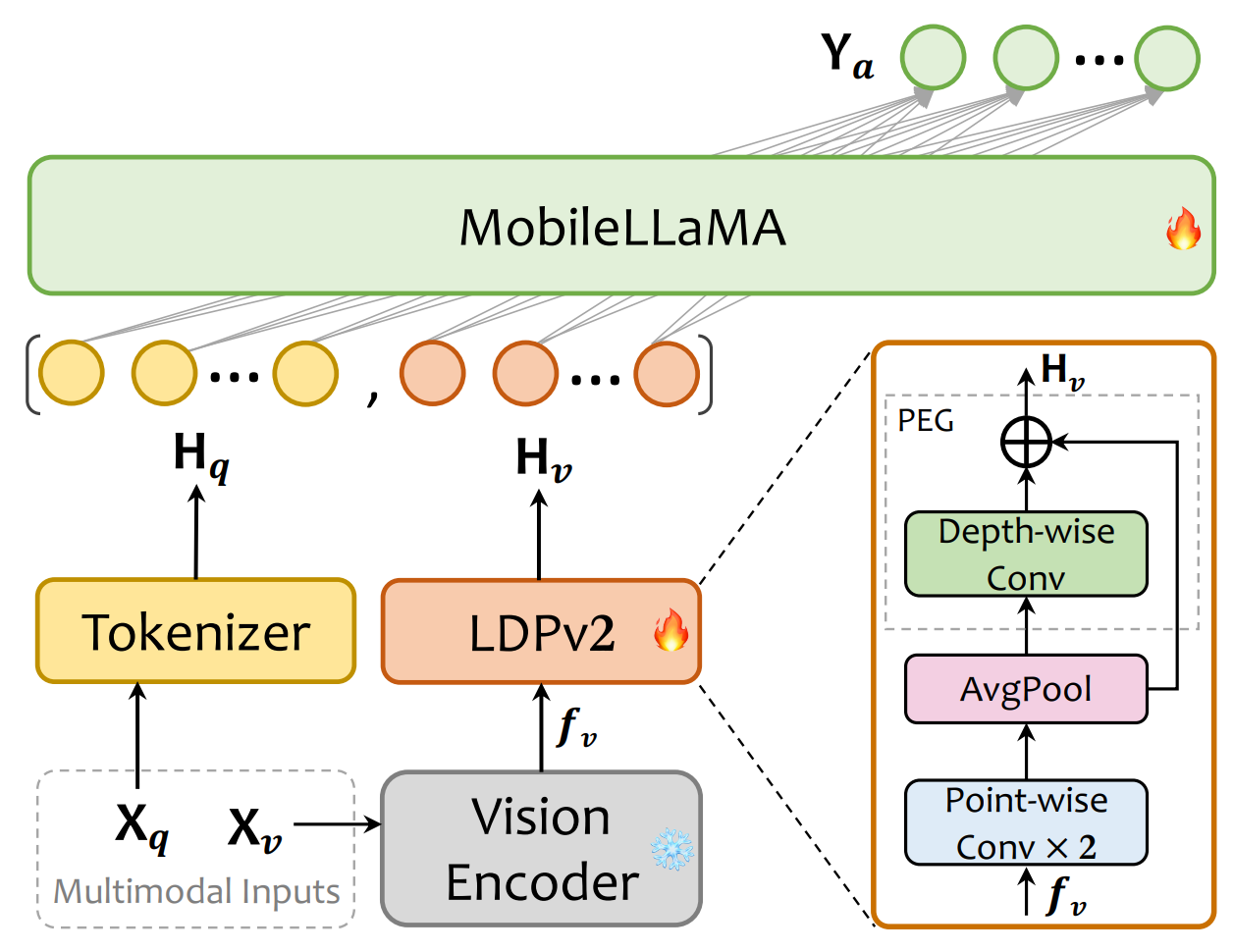
188 KB
doc/transformer.png
0 → 100644
{kind=link}
396 KB
docker_start.sh
0 → 100644
infer.py
0 → 100644
File added
File added
File added
mobilevlm/constants.py
0 → 100644
mobilevlm/conversation.py
0 → 100644