
上传代码
Showing
Algorithm_principle.png
0 → 100644
{kind=link}
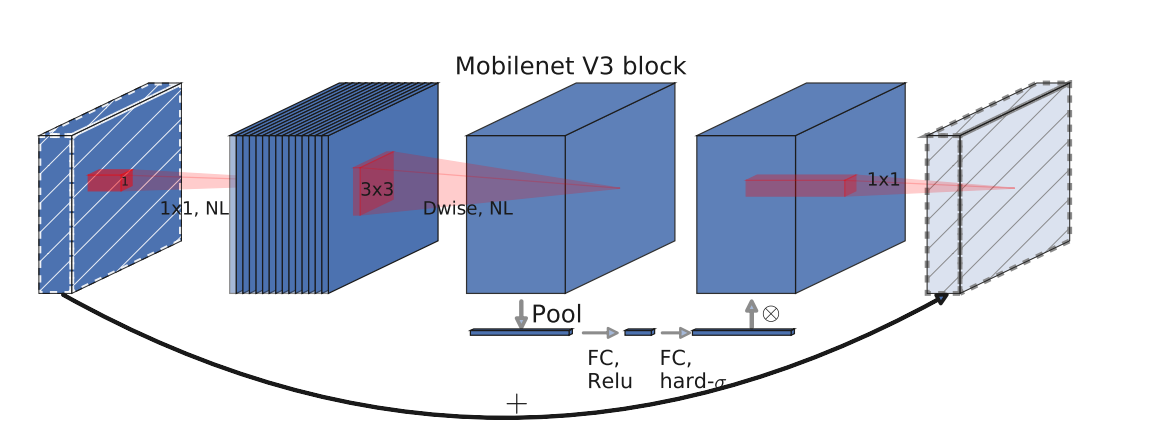
75.7 KB
Backbone.png
0 → 100644
{kind=link}
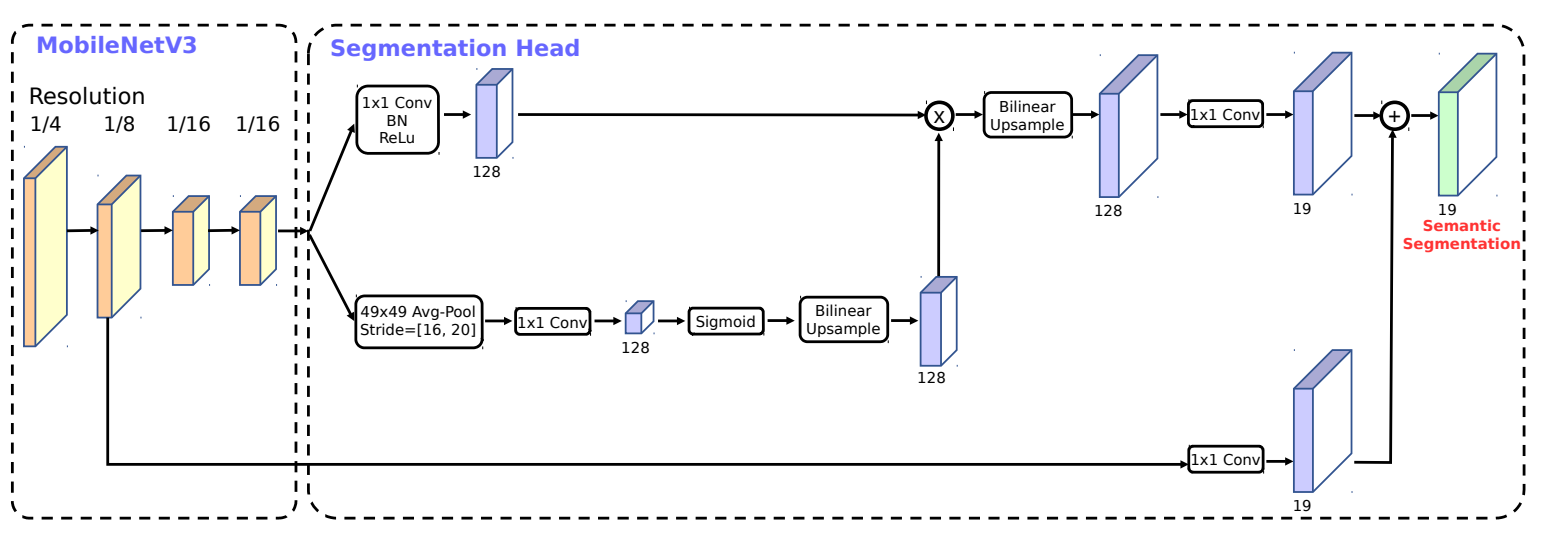
84.1 KB
This diff is collapsed.
File added
File added
mobilenet.onnx
0 → 100644
File added
mobilenet_large.onnx
0 → 100644
File added
model.pt
0 → 100644
File added
presets.py
0 → 100644
requirement.txt
0 → 100644
result.png
0 → 100644
{kind=link}

258 KB
run.sh
0 → 100644
test.py
0 → 100644
torch.result.log
0 → 100644
This diff is collapsed.
tuning.log
0 → 100644
tvm.result.log
0 → 100644
This diff is collapsed.
utils.py
0 → 100644
val.py
0 → 100644
val.py.bak
0 → 100644
val_onnx.py
0 → 100644