Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
Mistral_pytorch
Commits
bc137ddf
Commit
bc137ddf
authored
Jun 11, 2025
by
chenych
Browse files
Update
parent
1ff71e49
Changes
4
Hide whitespace changes
Inline
Side-by-side
Showing
4 changed files
with
50 additions
and
42 deletions
+50
-42
README.md
README.md
+26
-14
doc/results.png
doc/results.png
+0
-0
infer_mistral.py
infer_mistral.py
+0
-28
infer_vllm.py
infer_vllm.py
+24
-0
No files found.
README.md
View file @
bc137ddf
...
...
@@ -28,7 +28,6 @@ docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:vllm0.8.5-ubuntu22.04
docker run
-it
--shm-size
200g
--network
=
host
--name
{
docker_name
}
--privileged
--device
=
/dev/kfd
--device
=
/dev/dri
--device
=
/dev/mkfd
--group-add
video
--cap-add
=
SYS_PTRACE
--security-opt
seccomp
=
unconfined
-u
root
-v
/path/your_code_data/:/path/your_code_data/
-v
/opt/hyhal/:/opt/hyhal/:ro
{
imageID
}
bash
cd
/your_code_path/mistral_pytorch
pip
install
mistral_inference
```
### Dockerfile(方法二)
...
...
@@ -38,24 +37,19 @@ docker build --no-cache -t mistral:latest .
docker run
-it
--shm-size
200g
--network
=
host
--name
{
docker_name
}
--privileged
--device
=
/dev/kfd
--device
=
/dev/dri
--device
=
/dev/mkfd
--group-add
video
--cap-add
=
SYS_PTRACE
--security-opt
seccomp
=
unconfined
-u
root
-v
/path/your_code_data/:/path/your_code_data/
-v
/opt/hyhal/:/opt/hyhal/:ro
{
imageID
}
bash
cd
/your_code_path/mistral_pytorch
pip
install
mistral_inference
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从
[
光合
](
https://developer.
hpccube.com
/tool/
)
开发者社区下载安装。
关于本项目DCU显卡所需的特殊深度学习库可从
[
光合
](
https://developer.
sourcefind.cn
/tool/
)
开发者社区下载安装。
```
bash
DTK: 25.04
python: 3.10
vllm: 0.8.5
torch: 2.4.1+das.opt2.dtk2504
deepspeed: 0.14.2+das.opt2.dtk2504
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库安装方式如下:
```
bash
pip
install
mistral_inference
```
## 数据集
无
...
...
@@ -86,23 +80,41 @@ SFT训练脚本示例,参考`llama-factory/train_lora`下对应yaml文件。
参数解释同
[
#全参微调
](
#全参微调
)
## 推理
### mistral-chat
### vllm
#### offline
```
bash
mistral-ch
at /path_of/mistral
_models/
7B-Instruct-v0.3
--instruct
--max_tokens
256
python infer_vllm.py
--model_name_or_p
at
h
/path_of/mistral
ai/Mistral-
7B-Instruct-v0.3
```
### offline
### server
1.
启动服务
```
bash
python infer_mistral.py
--model_name_or_path
/path_of/model
vllm serve mistralai/Mistral-7B-Instruct-v0.3
--tokenizer_mode
mistral
--config_format
mistral
--load_format
mistral
--served-model-name
Mistral-7B-Instruct
--trust-remote-code
--enforce-eager
```
2.
测试client
```
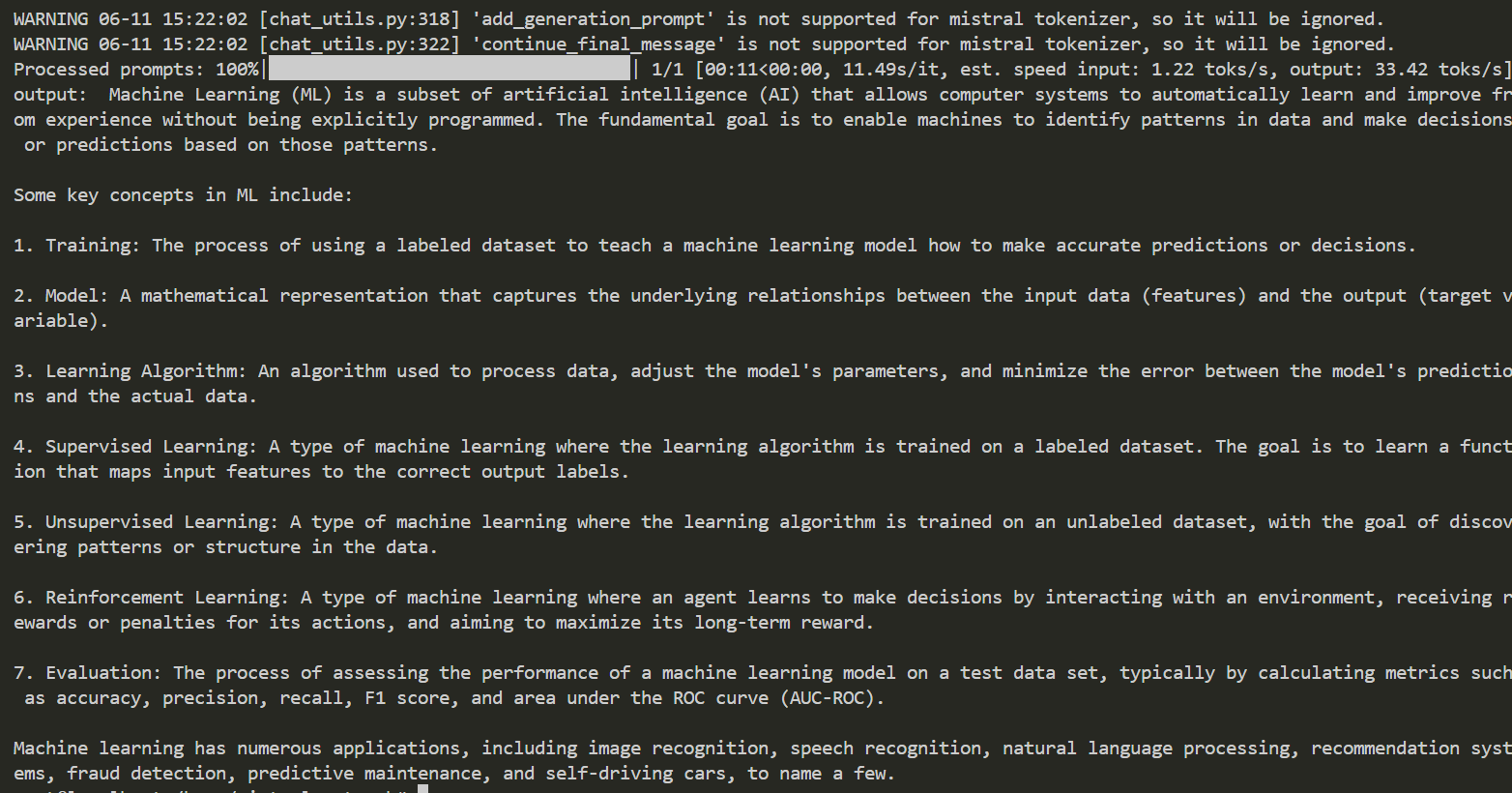
curl http://<your-node-url>:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Mistral-7B-Instruct",
"messages": [
{
"role": "user",
"content": "Explain Machine Learning to me in a nutshell."
}
],
"temperature": 0.15
}'
```
## result
<div
align=
center
>
<img
src=
"./doc/results.
jpg
"
/>
<img
src=
"./doc/results.
pngcd ../
"
/>
</div>
### 精度
暂无
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
...
...
doc/results.png
0 → 100644
View file @
bc137ddf
129 KB
infer_mistral.py
deleted
100644 → 0
View file @
1ff71e49
import
argparse
from
mistral_inference.transformer
import
Transformer
from
mistral_inference.generate
import
generate
from
mistral_common.tokens.tokenizers.mistral
import
MistralTokenizer
from
mistral_common.protocol.instruct.messages
import
UserMessage
from
mistral_common.protocol.instruct.request
import
ChatCompletionRequest
parse
=
argparse
.
ArgumentParser
()
parse
.
add_argument
(
"--user_prompt"
,
type
=
str
,
default
=
"Explain Machine Learning to me in a nutshell."
)
parse
.
add_argument
(
"--model_name_or_path"
,
type
=
str
,
default
=
"mistralai/Mistral-7B-Instruct-v0.3"
)
args
=
parse
.
parse_args
()
tokenizer
=
MistralTokenizer
.
from_file
(
f
"
{
args
.
model_name_or_path
}
/tokenizer.model.v3"
)
model
=
Transformer
.
from_folder
(
args
.
model_name_or_path
)
completion_request
=
ChatCompletionRequest
(
messages
=
[
UserMessage
(
content
=
args
.
user_prompt
)])
tokens
=
tokenizer
.
encode_chat_completion
(
completion_request
).
tokens
out_tokens
,
_
=
generate
([
tokens
],
model
,
max_tokens
=
64
,
temperature
=
0.0
,
eos_id
=
tokenizer
.
instruct_tokenizer
.
tokenizer
.
eos_id
)
result
=
tokenizer
.
instruct_tokenizer
.
tokenizer
.
decode
(
out_tokens
[
0
])
print
(
result
)
infer_vllm.py
0 → 100644
View file @
bc137ddf
import
argparse
from
vllm
import
LLM
,
SamplingParams
parse
=
argparse
.
ArgumentParser
()
parse
.
add_argument
(
"--user_prompt"
,
type
=
str
,
default
=
"Explain Machine Learning to me in a nutshell."
)
parse
.
add_argument
(
"--model_name_or_path"
,
type
=
str
,
default
=
"mistralai/Mistral-7B-Instruct-v0.3"
)
args
=
parse
.
parse_args
()
sampling_params
=
SamplingParams
(
max_tokens
=
8192
)
# If you want to divide the GPU requirement over multiple devices, please add *e.g.* `tensor_parallel=2`
llm
=
LLM
(
model
=
args
.
model_name_or_path
,
tokenizer_mode
=
"mistral"
,
config_format
=
"mistral"
,
load_format
=
"mistral"
)
messages
=
[
{
"role"
:
"user"
,
"content"
:
args
.
user_prompt
},
]
outputs
=
llm
.
chat
(
messages
,
sampling_params
=
sampling_params
)
print
(
"output:"
,
outputs
[
0
].
outputs
[
0
].
text
)
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}