Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
Mistral-Small_pytorch
Commits
8a7ff08b
"vscode:/vscode.git/clone" did not exist on "e061b268d284a6f43acc44314b83ec6ffe58e91a"
Commit
8a7ff08b
authored
Jun 16, 2025
by
chenych
Browse files
Add train loss
parent
dc061ea0
Changes
4
Hide whitespace changes
Inline
Side-by-side
Showing
4 changed files
with
24 additions
and
4 deletions
+24
-4
README.md
README.md
+22
-4
doc/results.png
doc/results.png
+0
-0
llama-factory/train_full/mistral_small_full_sft.yaml
llama-factory/train_full/mistral_small_full_sft.yaml
+1
-0
llama-factory/train_lora/mistral_small_lora_sft.yaml
llama-factory/train_lora/mistral_small_lora_sft.yaml
+1
-0
No files found.
README.md
View file @
8a7ff08b
...
...
@@ -84,13 +84,32 @@ SFT训练脚本示例,参考`llama-factory/train_lora`下对应yaml文件。
参数解释同
[
#全参微调
](
#全参微调
)
## 推理
暂无
### vllm 推理
#### offline
需要先修改vllm代码:如图
<div
align=
center
>
<img
src=
"./doc/img_v3_02n6_c32e8a36-8338-4dff-9aec-d710746a61fg.jpg"
/>
</div>
修改完成后,执行下面的方法。
```
bash
python infer_vllm.py
--model_name_or_path
/path_of/model
```
## result
暂无
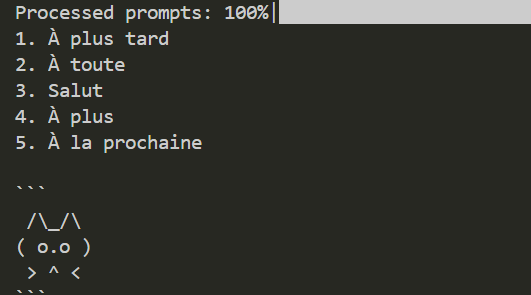
Prompt: "Give me 5 non-formal ways to say 'See you later' in French."
<div
align=
center
>
<img
src=
"./doc/results.png"
/>
</div>
### 精度
DCU与GPU精度一致,推理框架:pytorch。
训练框架:
[
Llama-Factory
](
https://developer.sourcefind.cn/codes/OpenDAS/llama-factory
)
训练脚本:
[
mistral_small_lora_sft.yaml
](
llama-factory/train_lora/mistral_small_lora_sft.yaml
)
| device | train_loss |
|:----------:|:-------:|
| DCU K100AI | 0.7417 |
| GPU A800 | 0.7424 |
## 应用场景
### 算法类别
...
...
@@ -108,4 +127,3 @@ DCU与GPU精度一致,推理框架:pytorch。
## 参考资料
-
https://mistral.ai/news/mistral-small-3-1
-
https://github.com/hiyouga/LLaMA-Factory/
doc/results.png
0 → 100644
View file @
8a7ff08b
11.8 KB
llama-factory/train_full/mistral_small_full_sft.yaml
View file @
8a7ff08b
...
...
@@ -23,6 +23,7 @@ save_steps: 500
plot_loss
:
true
overwrite_output_dir
:
true
save_only_model
:
false
report_to
:
none
# choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size
:
1
...
...
llama-factory/train_lora/mistral_small_lora_sft.yaml
View file @
8a7ff08b
...
...
@@ -26,6 +26,7 @@ save_steps: 500
plot_loss
:
true
overwrite_output_dir
:
true
save_only_model
:
false
report_to
:
none
# choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size
:
1
...
...
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}