
v1.0
parents
Showing
{kind=link}

90.2 KB
assets/knowledge.case1.png
0 → 100644
{kind=link}
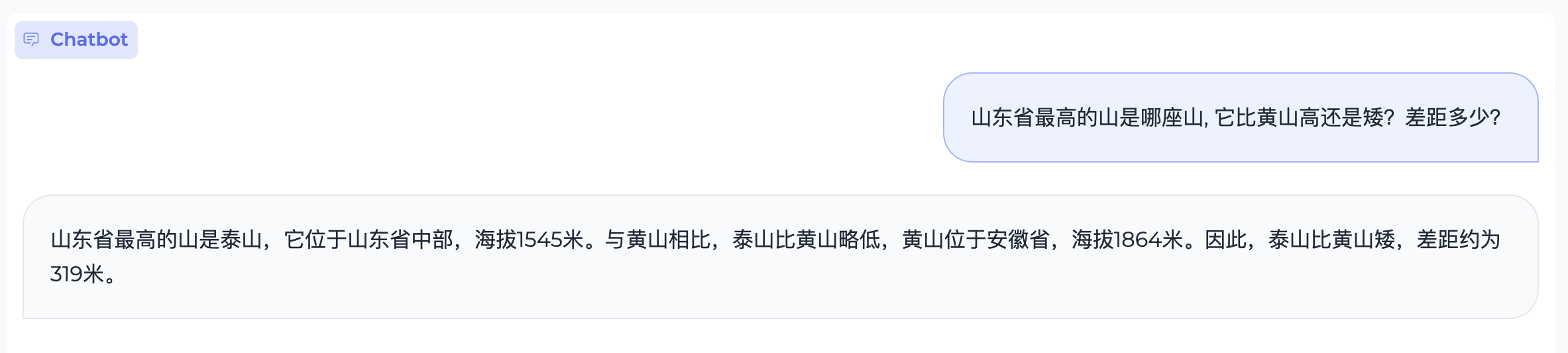
100 KB
assets/math.case1.png
0 → 100644
{kind=link}

67 KB
assets/math.case2.png
0 → 100644
{kind=link}

136 KB
{kind=link}

94.7 KB
{kind=link}

303 KB
assets/translation.case1.png
0 → 100644
{kind=link}

78 KB
assets/translation.case2.png
0 → 100644
{kind=link}

119 KB
assets/wechat.jpg
0 → 100644
{kind=link}

26.8 KB
convert_data.py
0 → 100644
This diff is collapsed.
This diff is collapsed.
demo/hf_based_demo.py
0 → 100644
demo/vllm_based_demo.py
0 → 100644
doc/transformer.png
0 → 100644
{kind=link}

396 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
finetune/README.md
0 → 100644
finetune/README_en.md
0 → 100644