
v1.0
parents
Showing
LICENSE
0 → 100644
README-en.md
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
{kind=link}

188 KB
assets/code.case1.gif
0 → 100644
{kind=link}

4.56 MB
assets/code.case2.gif
0 → 100644
{kind=link}
This image diff could not be displayed because it is too large. You can view the blob instead.
assets/creation.case1.png
0 → 100644
{kind=link}
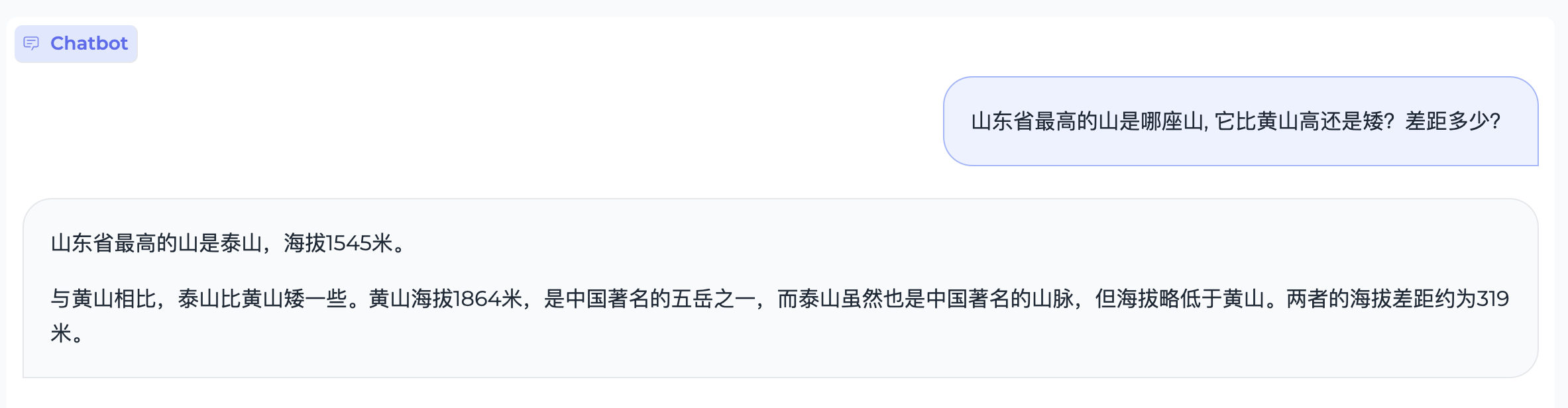
111 KB
assets/creation.case2.png
0 → 100644
{kind=link}
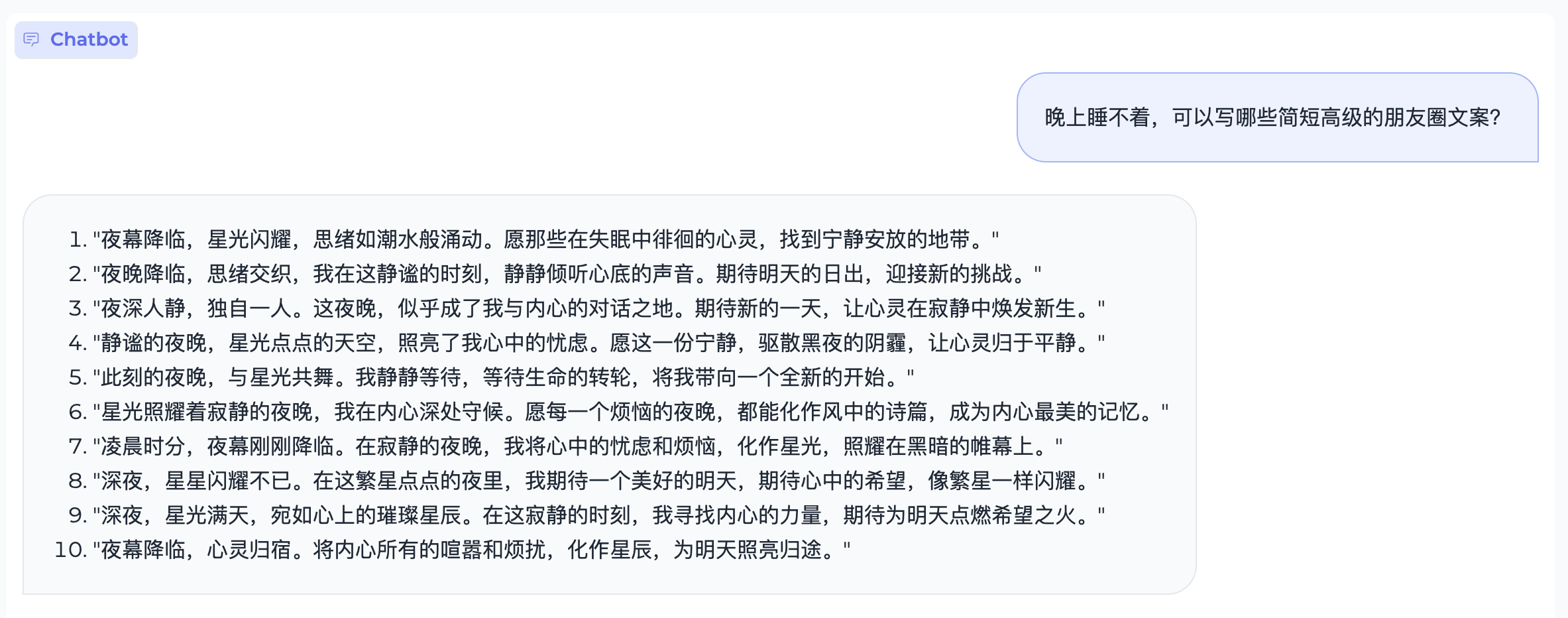
373 KB
assets/creation.case3.png
0 → 100644
{kind=link}
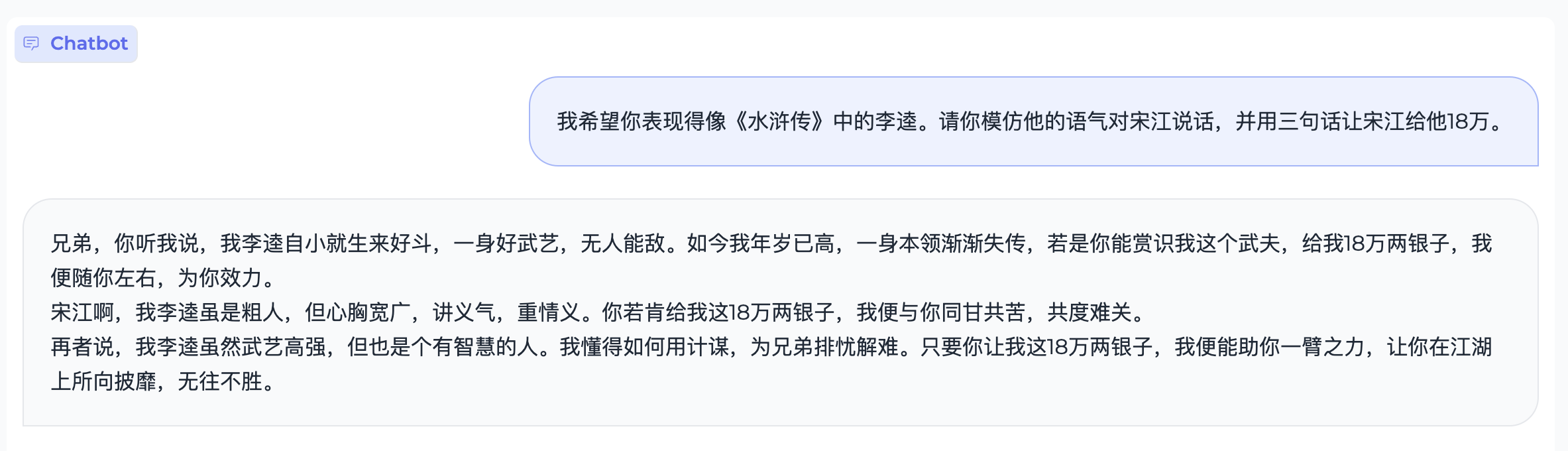
204 KB
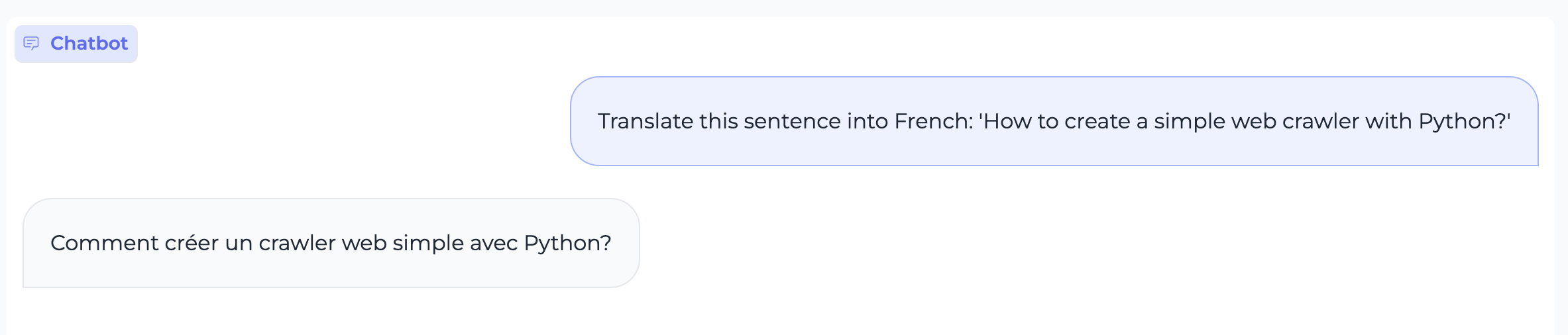
assets/en.code.case1.gif
0 → 100644
{kind=link}

4.93 MB
assets/en.creation.case1.png
0 → 100644
{kind=link}
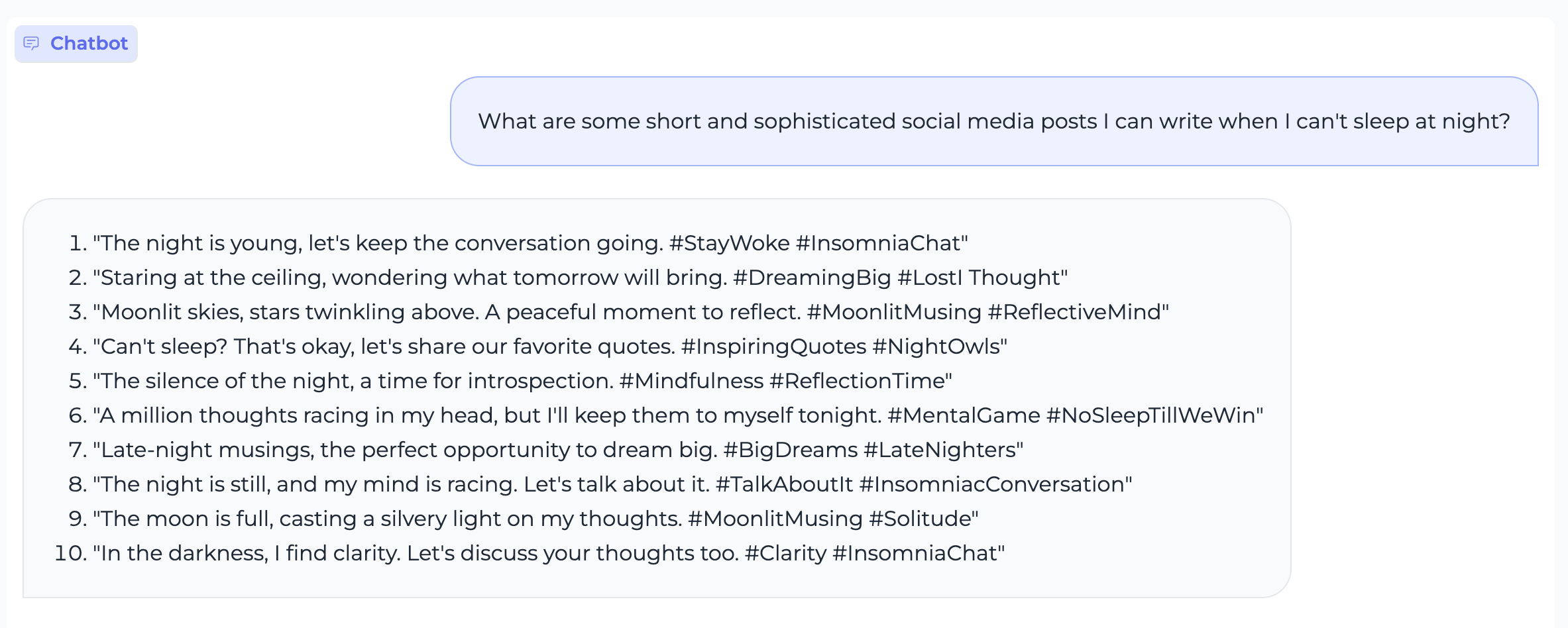
304 KB
assets/en.creation.case2.png
0 → 100644
{kind=link}
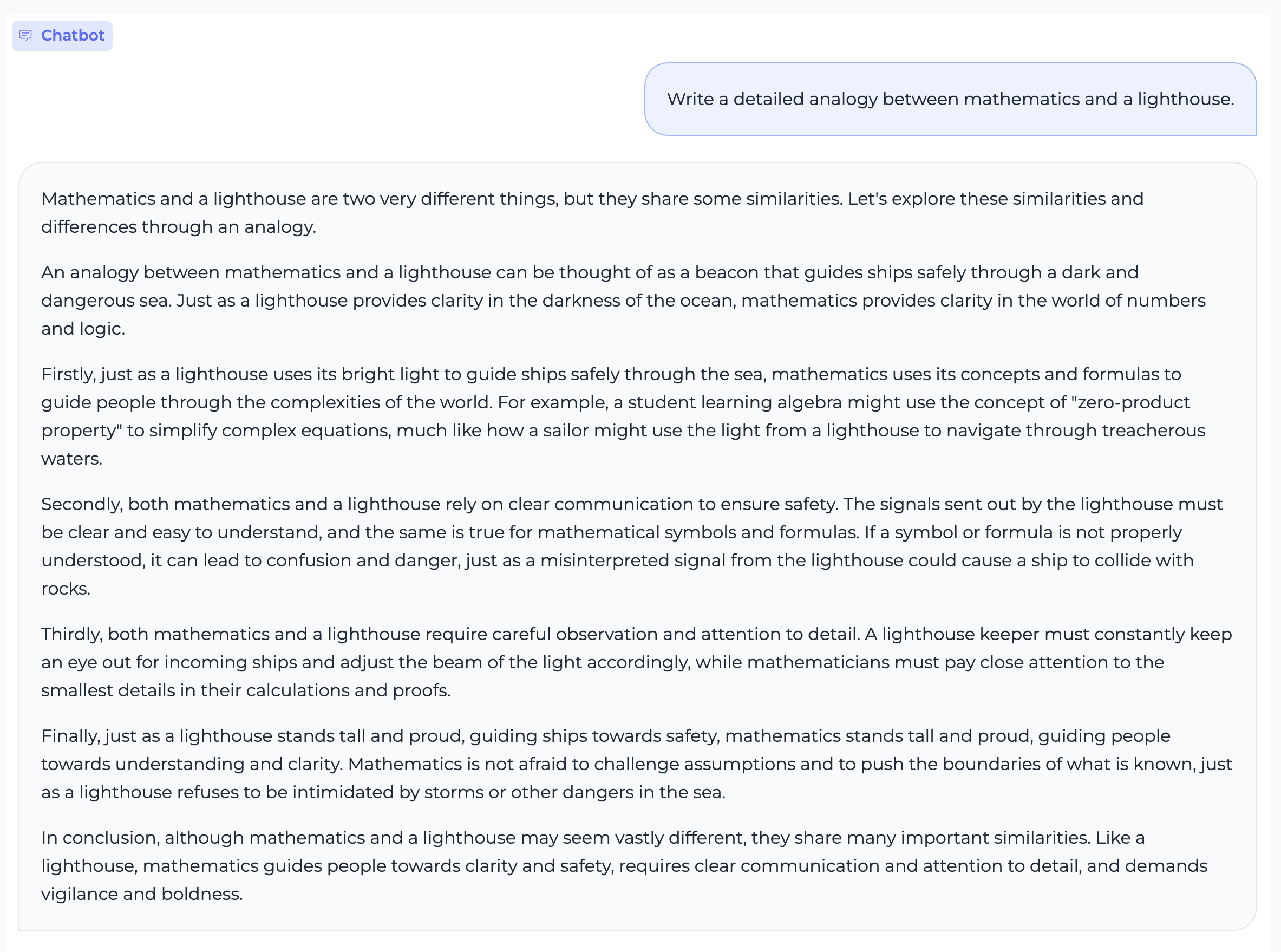
557 KB
{kind=link}
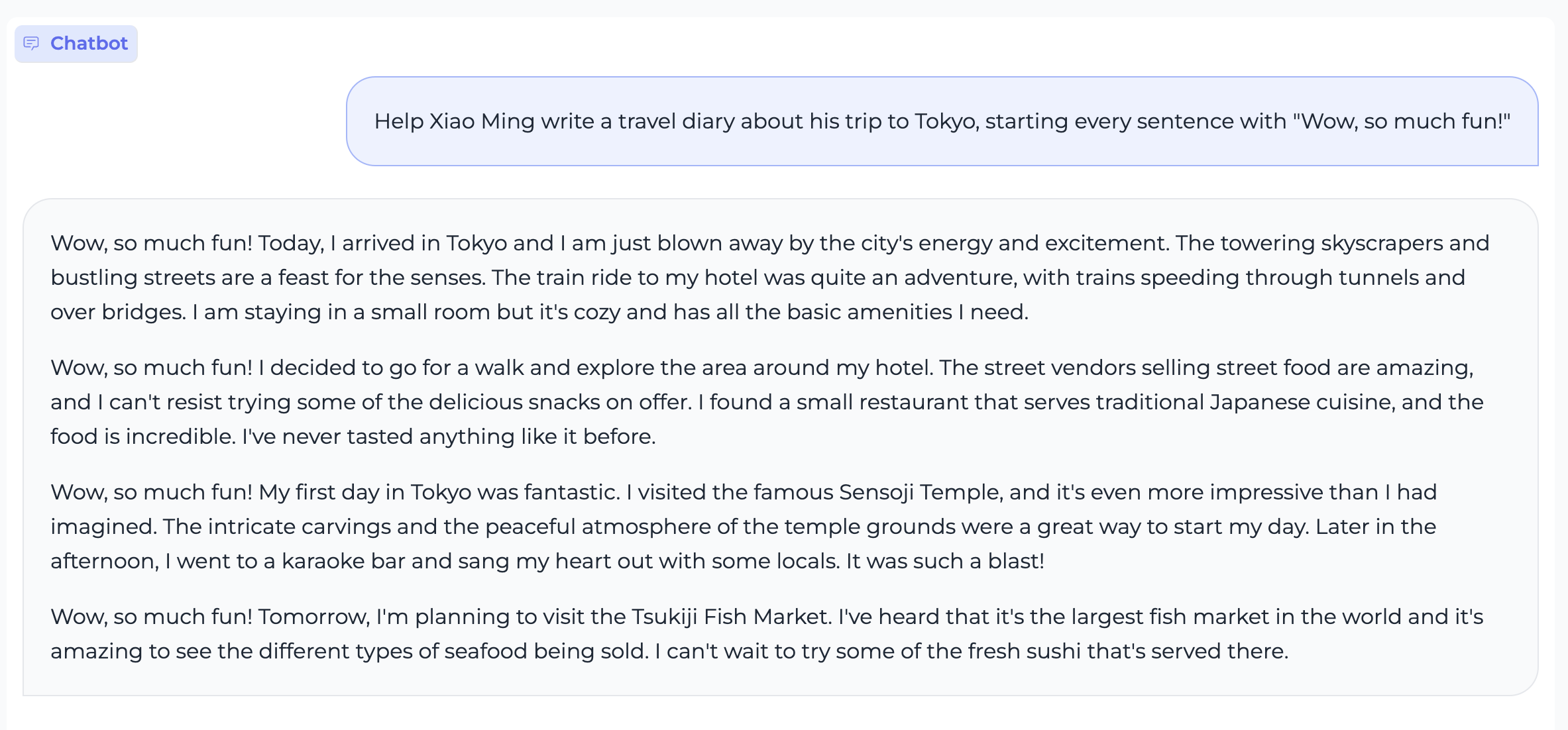
353 KB
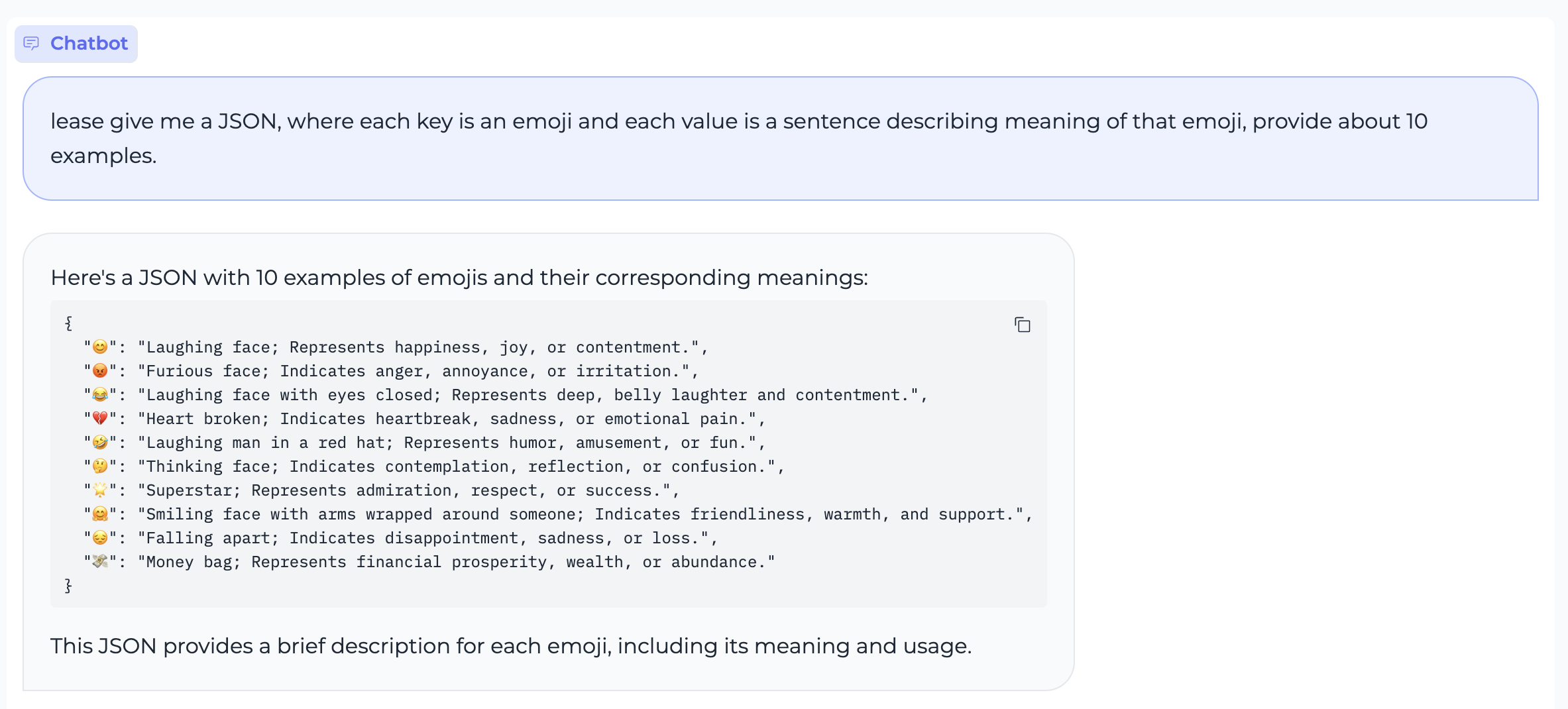
assets/en.math.case1.png
0 → 100644
{kind=link}
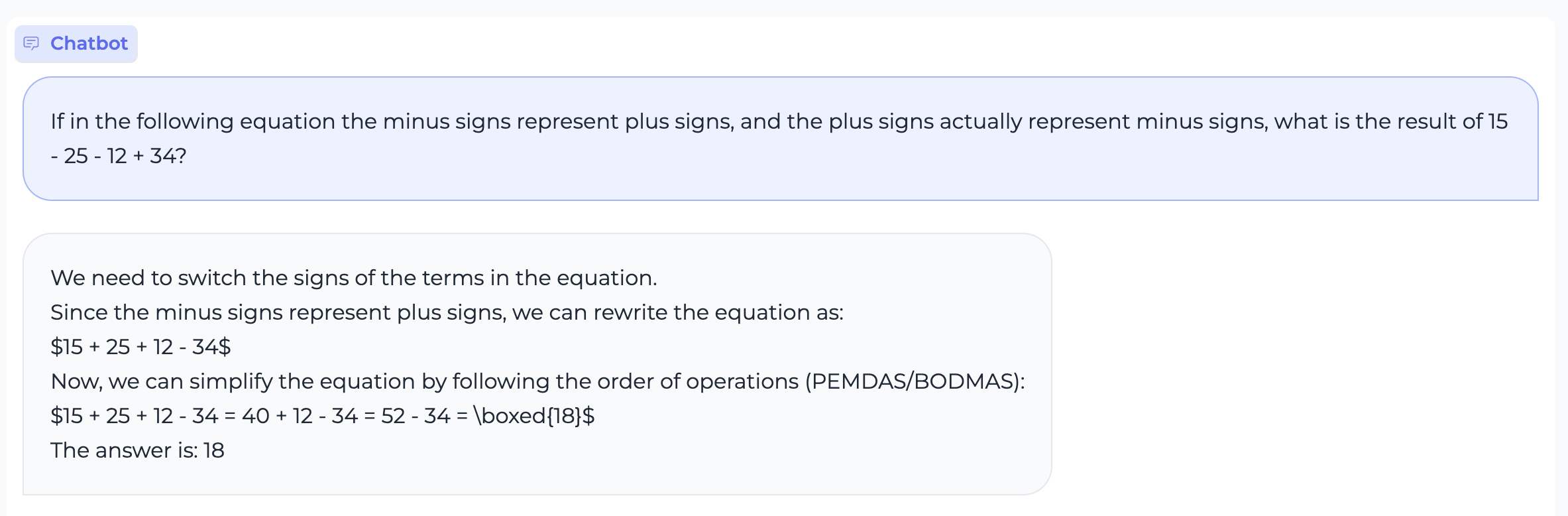
163 KB
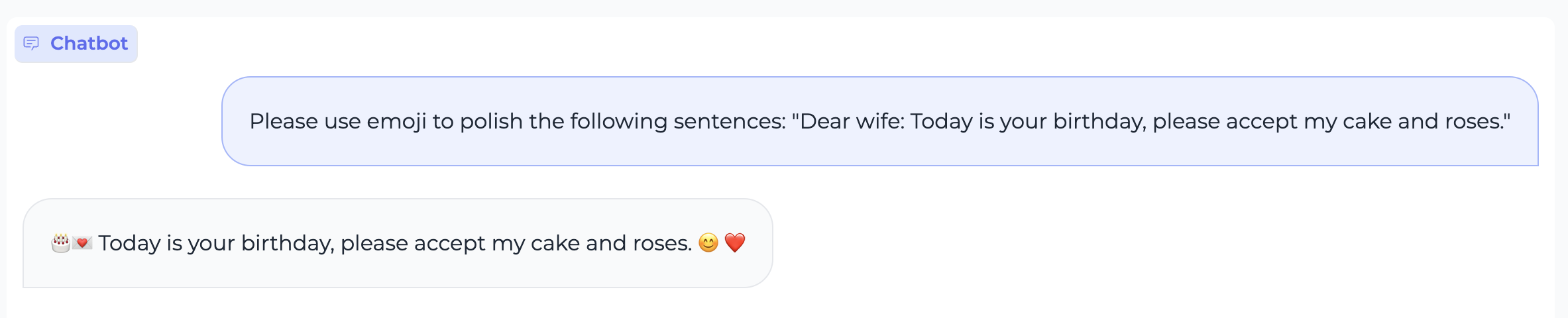
assets/en.math.case2.png
0 → 100644
{kind=link}
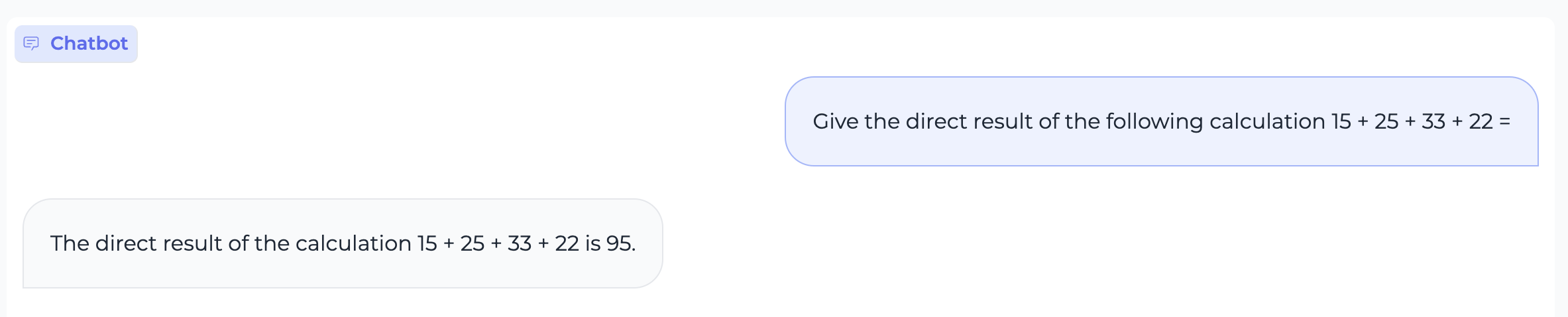
68.5 KB
{kind=link}
279 KB
{kind=link}
87.1 KB
{kind=link}
70.9 KB
{kind=link}

365 KB