"git@developer.sourcefind.cn:modelzoo/yolov7_migraphx.git" did not exist on "e93d7587634cc6ef3b92a3884928e4592f53c6b6"

metaportrait
Showing
base_model/modules/util.py
0 → 100755
base_model/train_ddp.py
0 → 100755
base_model/utils/__init__.py
0 → 100755
docs/Teaser.png
0 → 100644
{kind=link}
This image diff could not be displayed because it is too large. You can view the blob instead.
environment.yml
0 → 100644
imgs/2500.png
0 → 100644
{kind=link}

707 KB
imgs/image-1.png
0 → 100644
{kind=link}
88.5 KB
imgs/image-2.png
0 → 100644
{kind=link}
72.9 KB
imgs/image-3.png
0 → 100644
{kind=link}
90.5 KB
imgs/image-4.png
0 → 100644
{kind=link}
232 KB
imgs/image-5.png
0 → 100644
{kind=link}
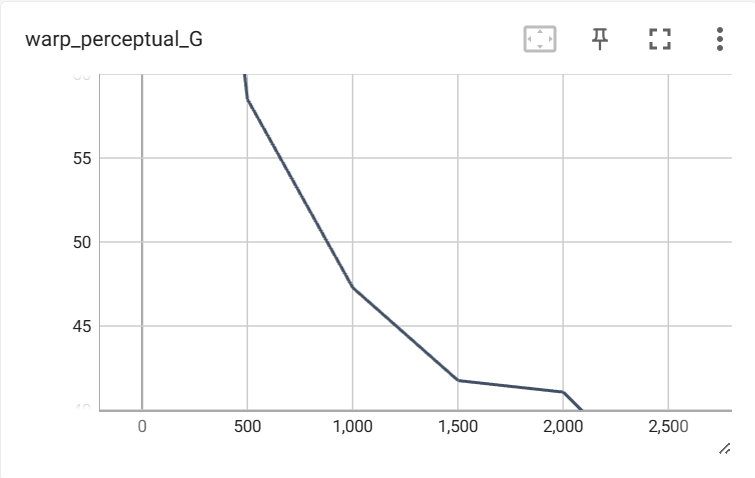
19.2 KB
imgs/image-6.png
0 → 100644
{kind=link}
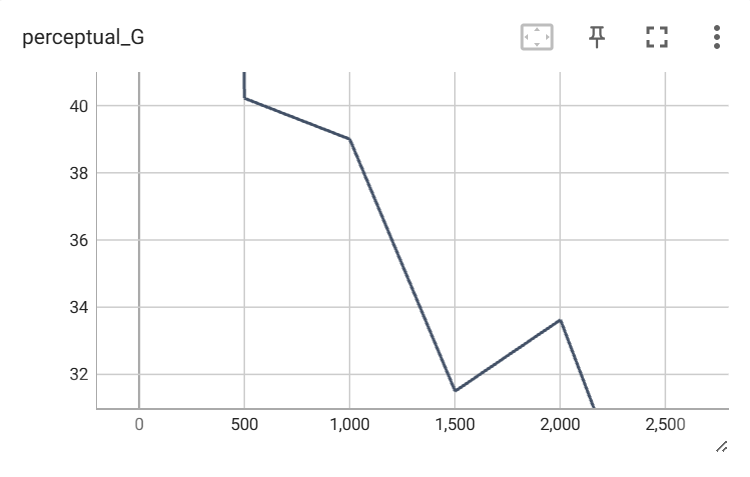
21.3 KB
imgs/image-7.png
0 → 100644
{kind=link}
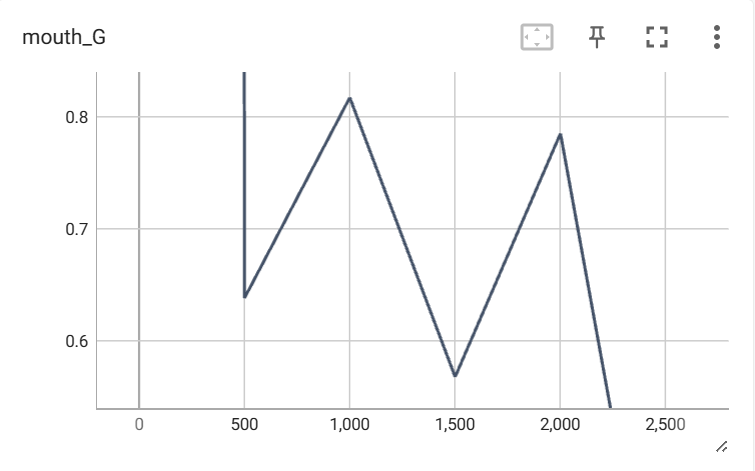
22.4 KB
imgs/image-8.png
0 → 100644
{kind=link}
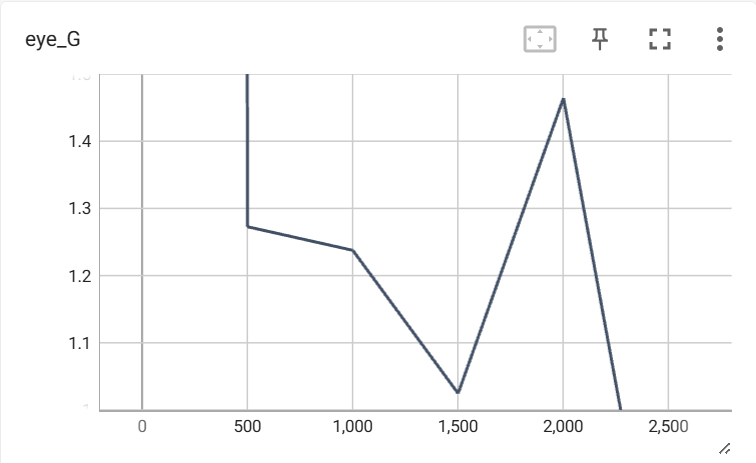
22 KB
imgs/image-9.png
0 → 100644
{kind=link}

372 KB
imgs/image.png
0 → 100644
{kind=link}
629 KB
model.properties
0 → 100644