
v1.0
parents
Showing
examples/run_evalharness.sh
0 → 100644
examples/vit_dsp.sh
0 → 100644
examples/vit_mpi.sh
0 → 100644
gpt2-merges.txt
0 → 100644
This diff is collapsed.
gpt2-vocab.json
0 → 100644
This diff is collapsed.
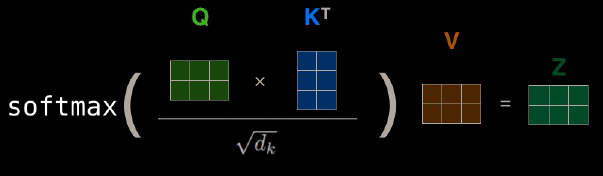
images/attention.png
0 → 100644
{kind=link}
28.4 KB
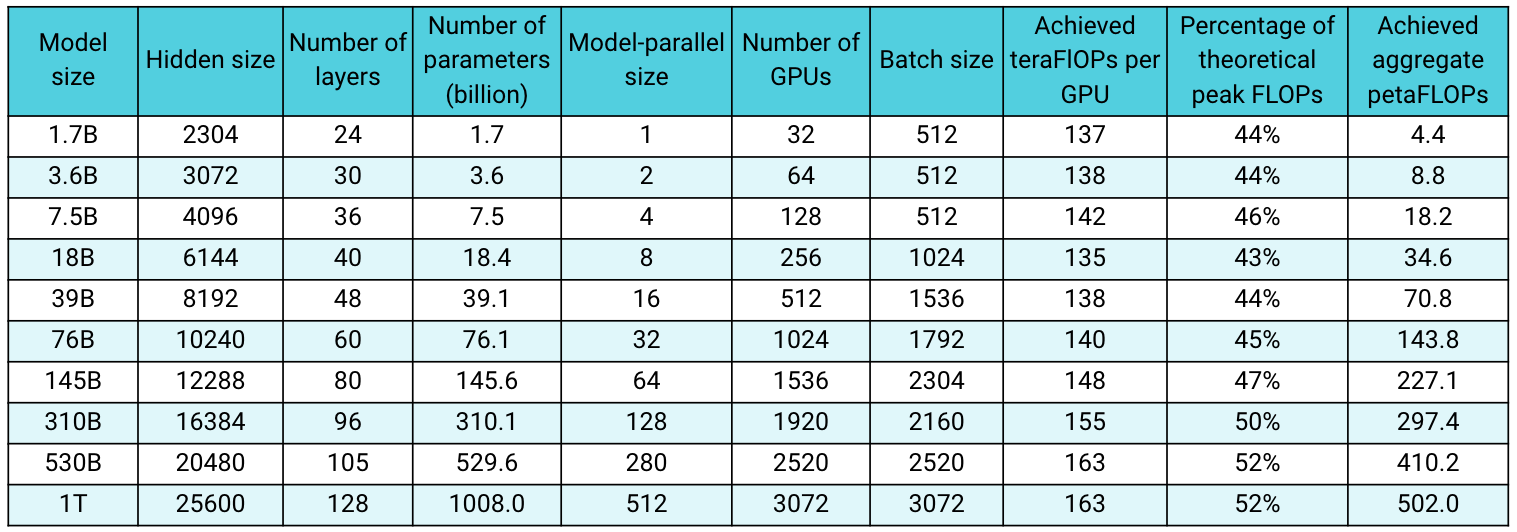
images/cases_april2021.png
0 → 100644
{kind=link}
159 KB
images/classify.png
0 → 100644
{kind=link}

412 KB
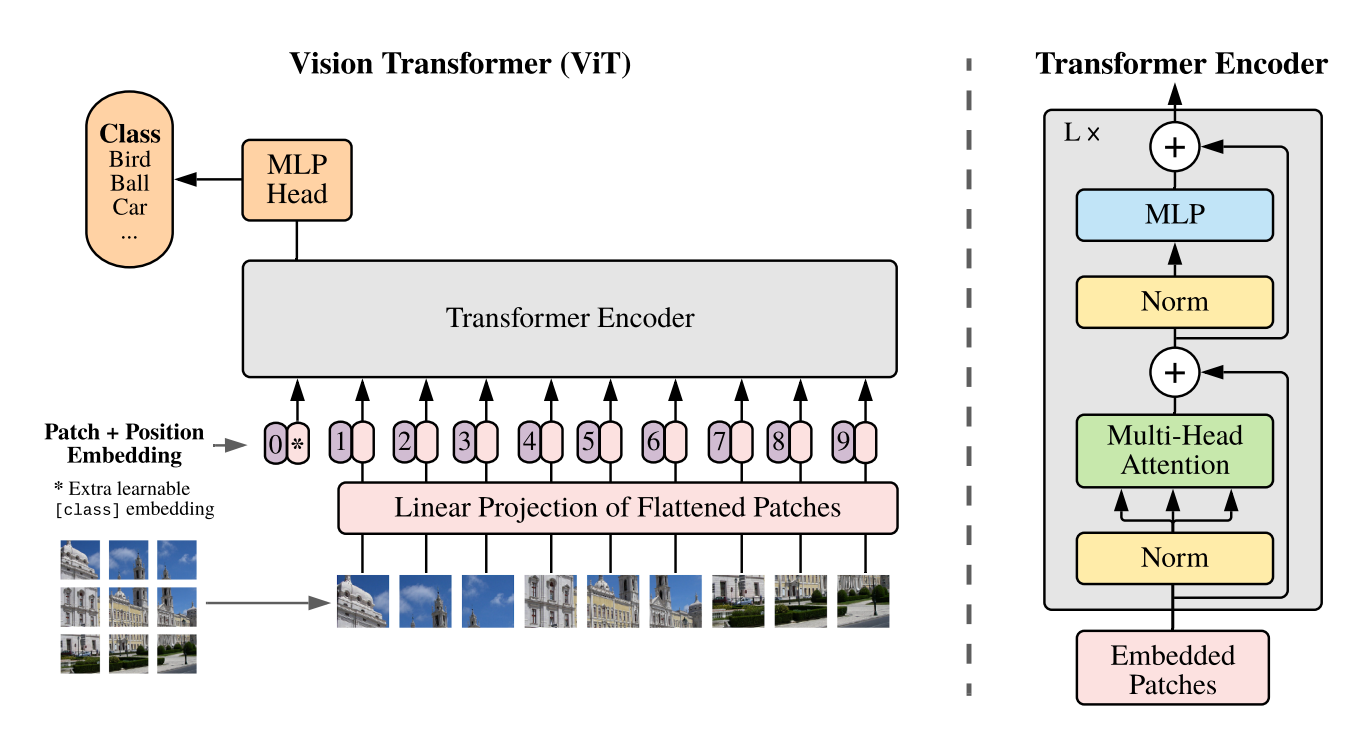
images/vit.png
0 → 100644
{kind=link}
223 KB
megatron/__init__.py
0 → 100644
megatron/arguments.py
0 → 100644
This diff is collapsed.
megatron/checkpointing.py
0 → 100644
megatron/data/Makefile
0 → 100644
megatron/data/__init__.py
0 → 100644
megatron/data/autoaugment.py
0 → 100644
This diff is collapsed.