
v1.0
Showing
assets/step-ministep32.jpg
0 → 100644
{kind=link}
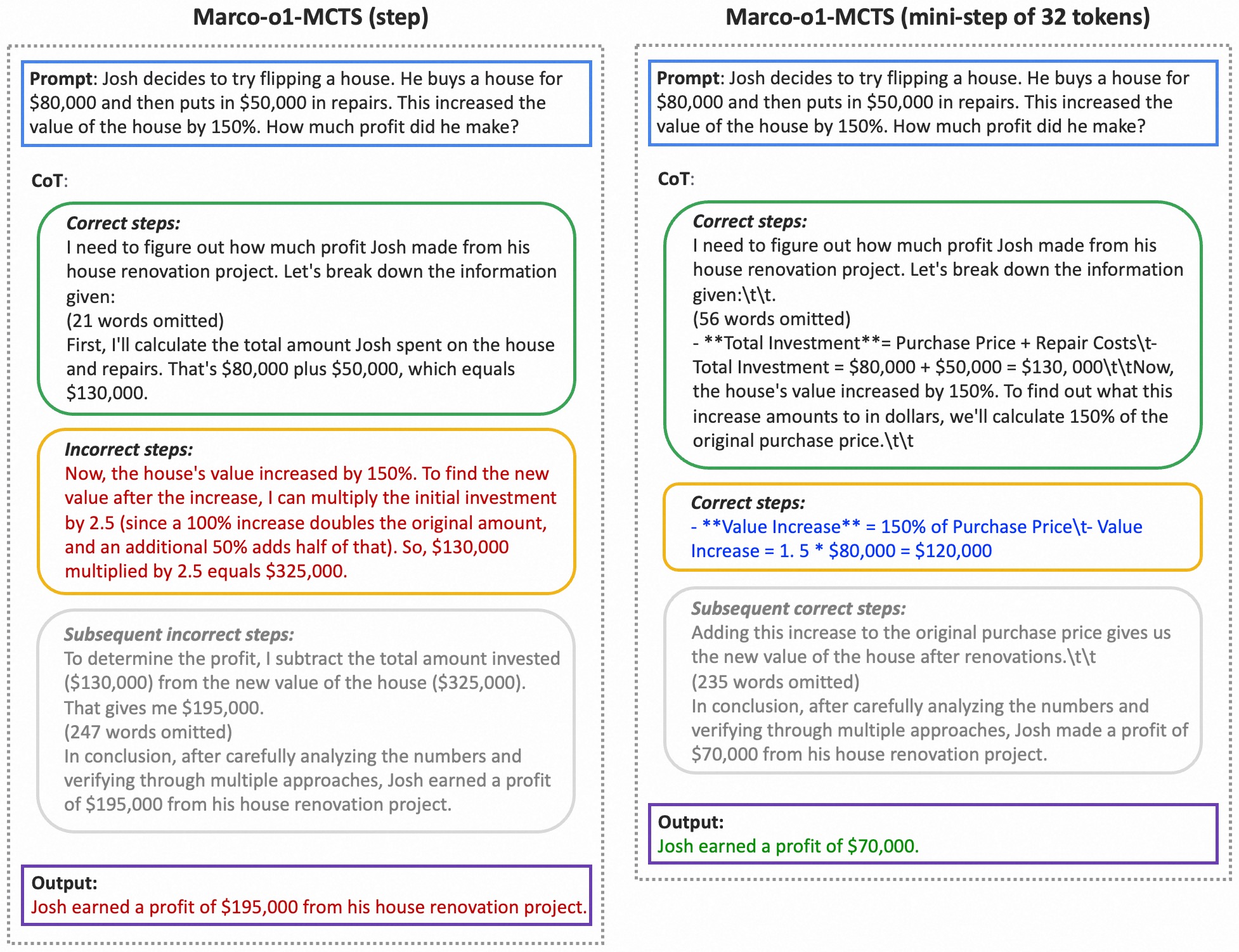
744 KB
assets/step_patch.jpg
0 → 100644
{kind=link}

958 KB
assets/strawberry.jpg
0 → 100644
{kind=link}
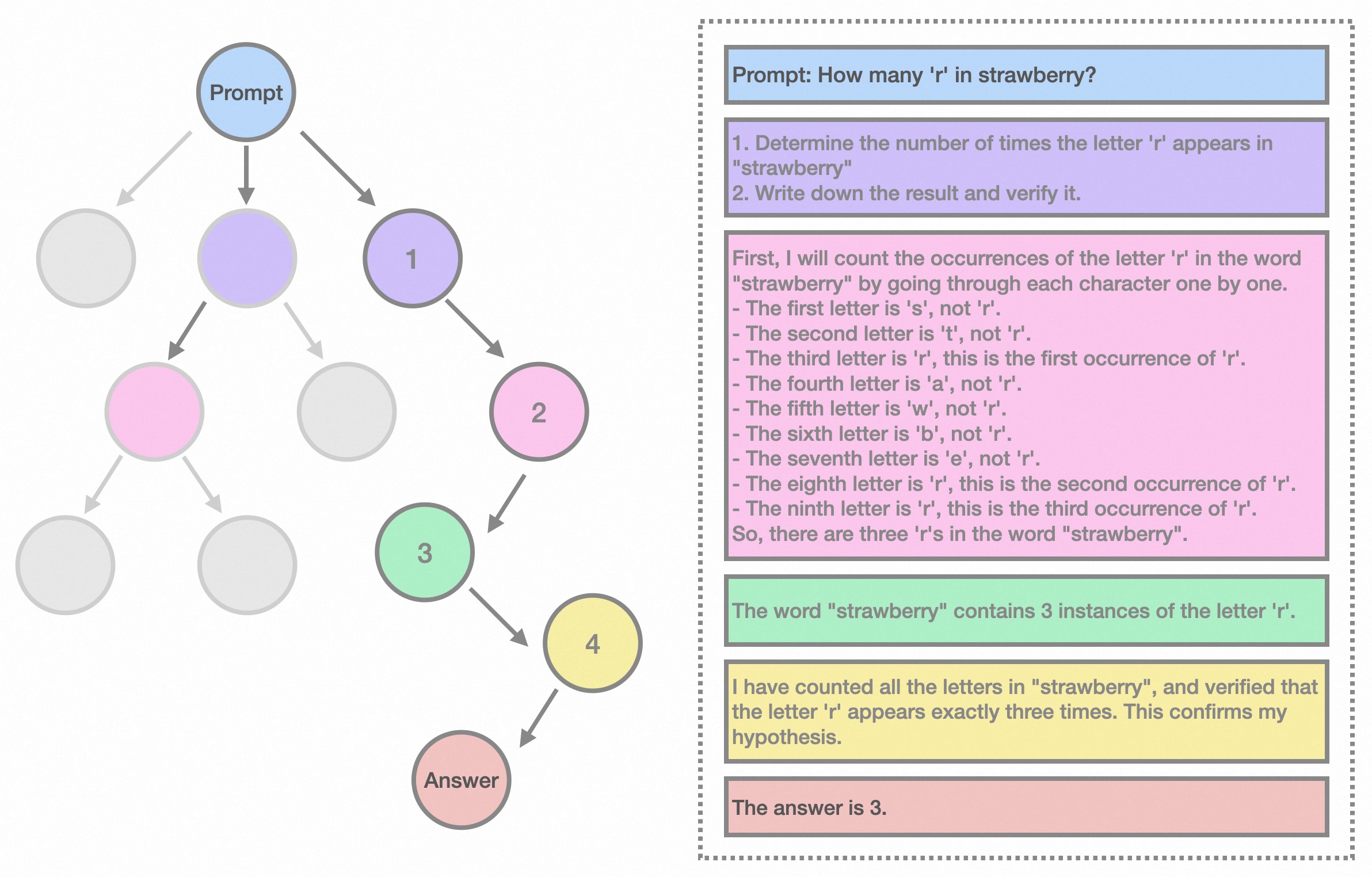
545 KB
assets/strawberry_2.jpg
0 → 100644
{kind=link}
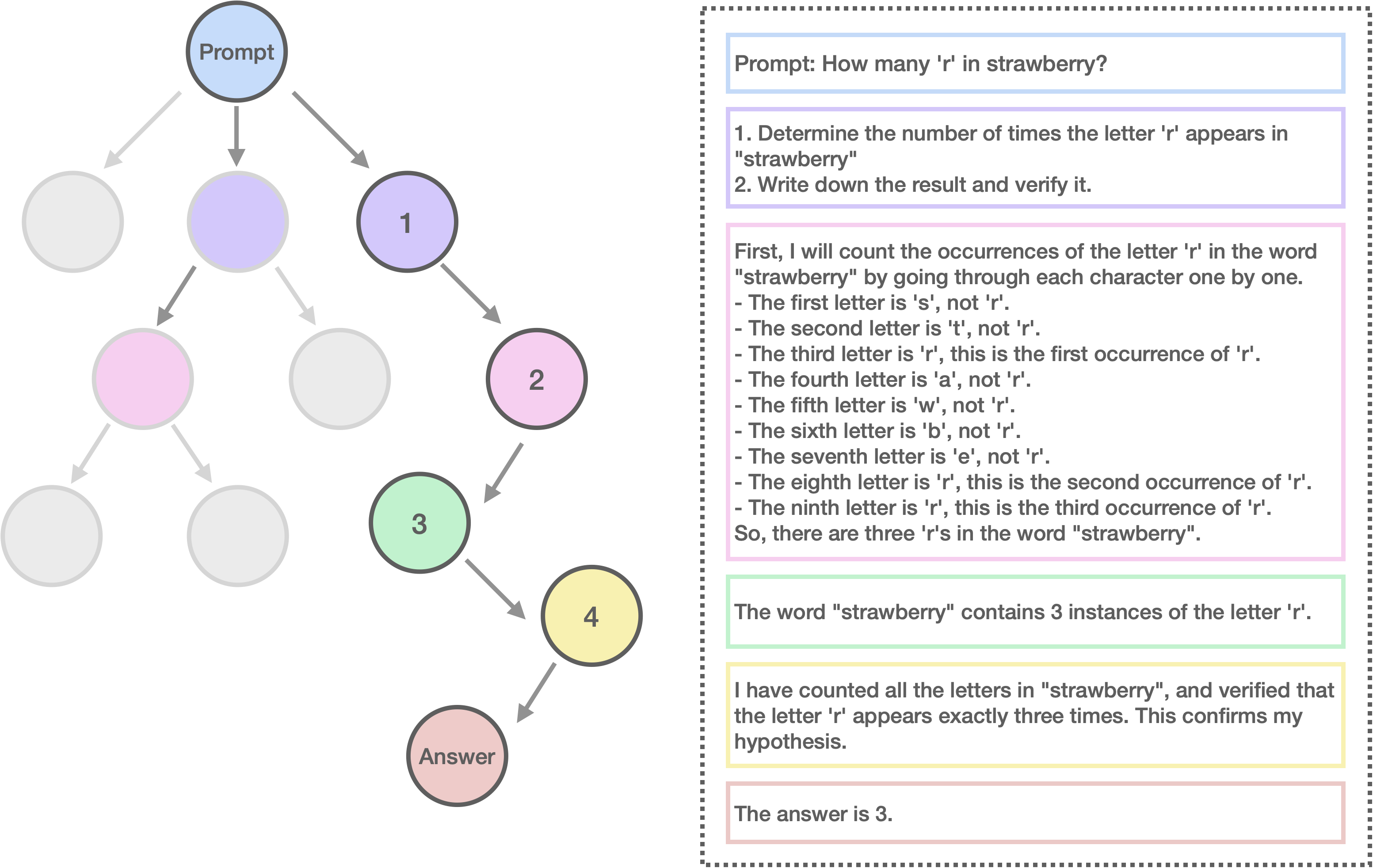
486 KB
assets/test@k.jpg
0 → 100644
{kind=link}
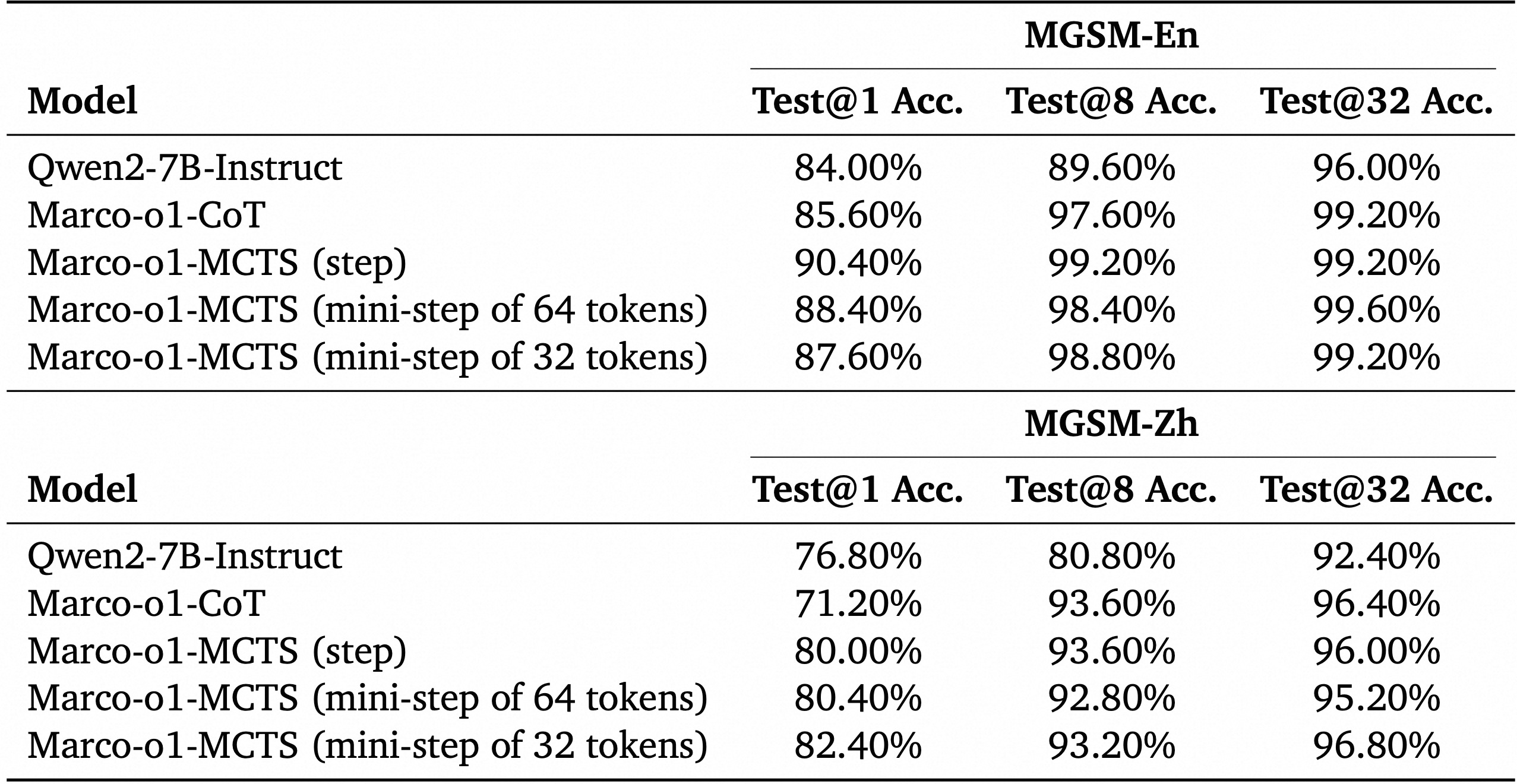
616 KB
assets/trans-case-1.jpg
0 → 100644
{kind=link}

438 KB
assets/trans-case-2.jpg
0 → 100644
{kind=link}

416 KB
assets/translation.jpg
0 → 100644
{kind=link}
823 KB
assets/translation_3.jpg
0 → 100644
{kind=link}

842 KB
{kind=link}
389 KB
data/CoT_demo.json
0 → 100644
This source diff could not be displayed because it is too large. You can view the blob instead.
data/NOTICE
0 → 100644
doc/algorithm.png
0 → 100644
{kind=link}
325 KB
doc/llama3.png
0 → 100644
{kind=link}
356 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
examples/README.md
0 → 100644
examples/client.py
0 → 100644
examples/stream_client.py
0 → 100644