
v1.0
Showing
AIDC-AI/Marco-o1/README.md
0 → 100644
LICENSE
0 → 100644
NOTICE
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
assets/cot-step.jpg
0 → 100644
{kind=link}

865 KB
assets/cot_step.jpg
0 → 100644
{kind=link}

1.01 MB
assets/fig1.png
0 → 100644
{kind=link}

16.5 KB
assets/fig2.png
0 → 100644
{kind=link}
18.7 KB
assets/fig3.png
0 → 100644
{kind=link}
99.5 KB
assets/fig4.png
0 → 100644
{kind=link}

45.1 KB
assets/fig5.png
0 → 100644
{kind=link}
22.3 KB
assets/fig6.png
0 → 100644
{kind=link}
45.5 KB
assets/fig7.png
0 → 100644
{kind=link}
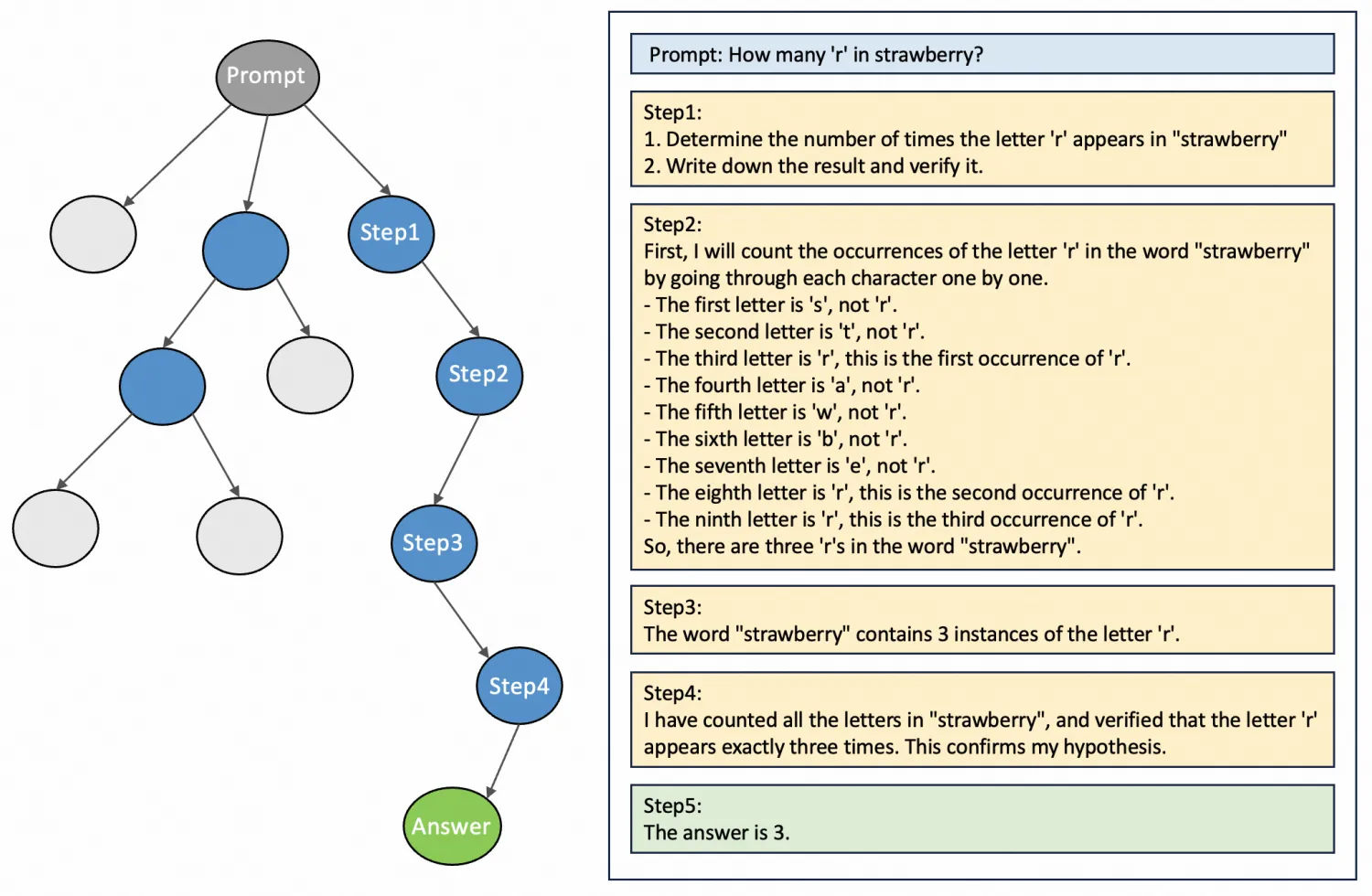
84.4 KB
assets/intro.jpg
0 → 100644
{kind=link}
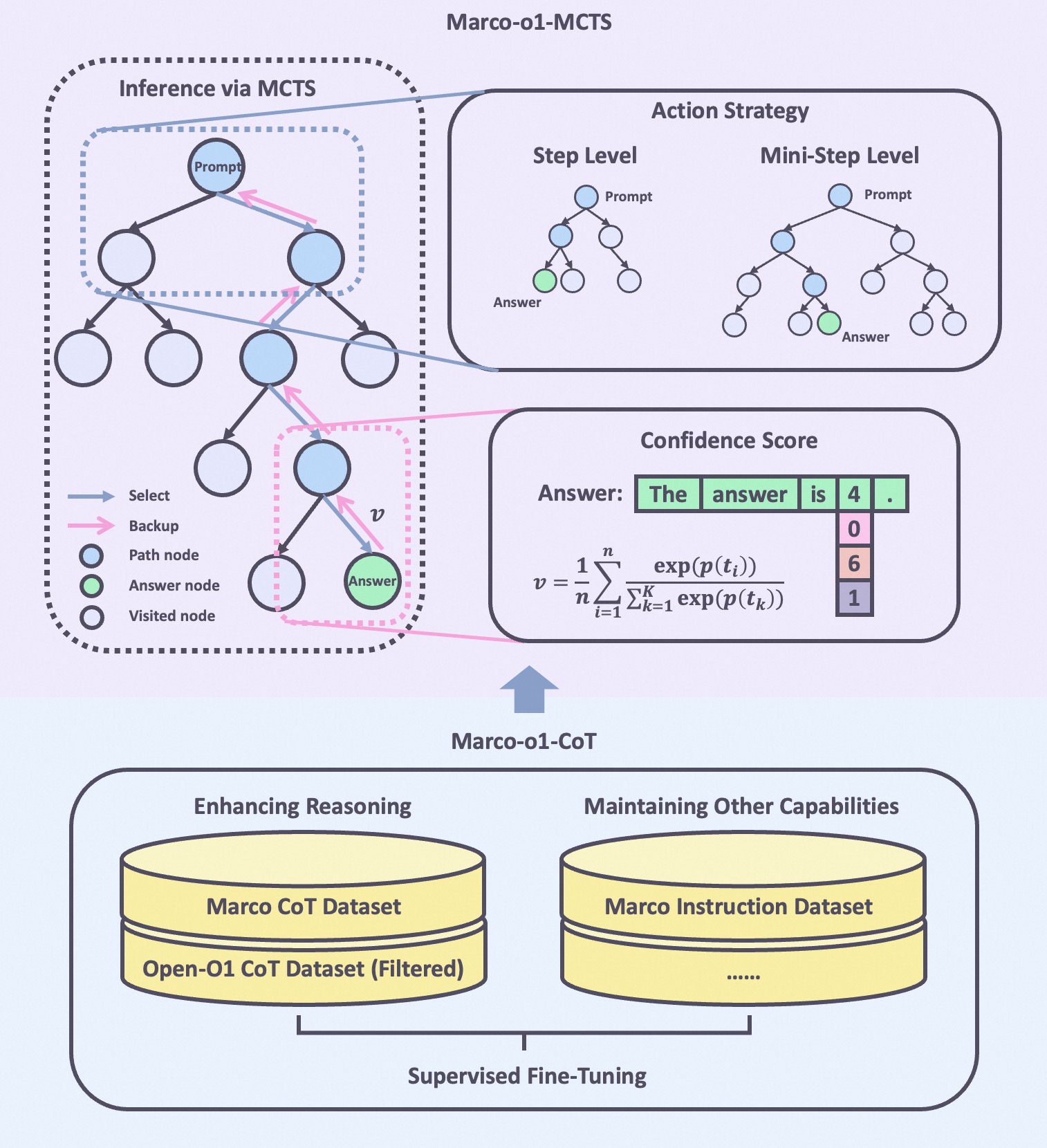
404 KB
assets/intro_2.jpg
0 → 100644
{kind=link}
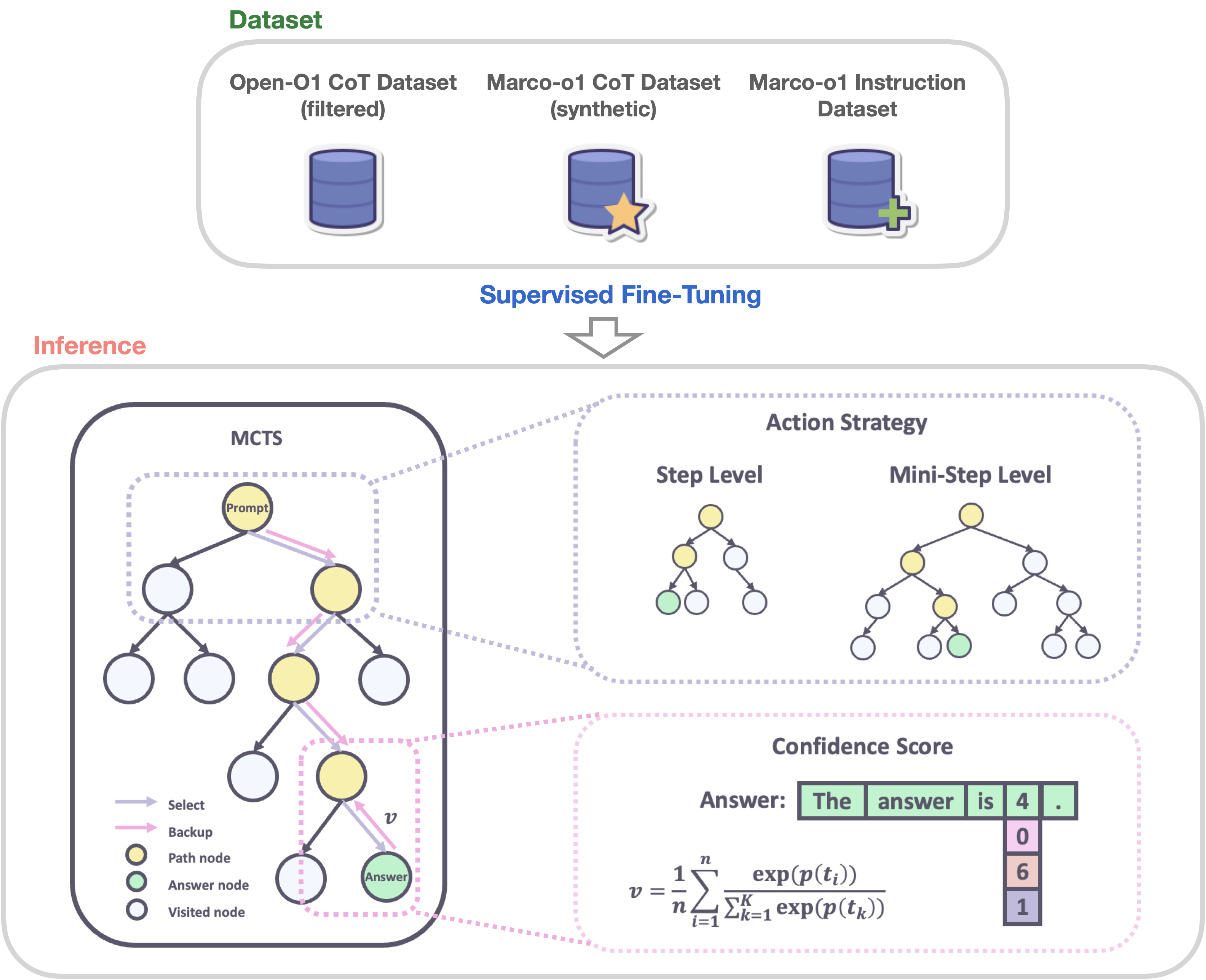
1.14 MB
assets/logo.png
0 → 100644
{kind=link}
152 KB
assets/ministep64-step.jpg
0 → 100644
{kind=link}

836 KB
assets/patch_step.jpg
0 → 100644
{kind=link}

808 KB
assets/results.jpg
0 → 100644
{kind=link}

225 KB