
Update 图片5.jpg, 图片4.jpg, 图片1.png, 图片2.jpg, 图片3.jpg, AUTHORS, inf.sh, LICENSE,...
Update 图片5.jpg, 图片4.jpg, 图片1.png, 图片2.jpg, 图片3.jpg, AUTHORS, inf.sh, LICENSE, model.properties, README.md.old, README.md, run.sh, requirements.txt, run-eval.sh, train-demo.py, setup.py files
Showing
AUTHORS
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README.md.old
0 → 100644
inf.sh
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| absl-py==2.1.0 | ||
| accelerate==0.31.0 | ||
| addict==2.4.0 | ||
| aiohttp==3.9.5 | ||
| aiosignal==1.3.1 | ||
| aitemplate @ http://10.6.10.68:8000/release/aitemplate/dtk24.04.1/aitemplate-0.0.1%2Bdas1.1.git5d8aa20.dtk2404.torch2.1.0-py3-none-any.whl#sha256=ad763a7cfd3935857cf10a07a2a97899fd64dda481add2f48de8b8930bd341dd | ||
| aliyun-python-sdk-core==2.15.1 | ||
| aliyun-python-sdk-kms==2.16.3 | ||
| annotated-types==0.7.0 | ||
| anyio==4.4.0 | ||
| apex @ http://10.6.10.68:8000/release/apex/dtk24.04.1/apex-1.1.0%2Bdas1.1.gitf477a3a.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=85eb662d13d6e6c3b61c2d878378c2338c4479bc03a1912c3eabddc2d9d08aa1 | ||
| async-timeout==4.0.3 | ||
| attrs==23.2.0 | ||
| bitsandbytes @ http://10.6.10.68:8000/release/bitsandbyte/dtk24.04.1/bitsandbytes-0.42.0%2Bdas1.1.gitce85679.abi1.dtk2404.torch2.1.0-py3-none-any.whl#sha256=6324e330c8d12b858d39f4986c0ed0836fcb05f539cee92a7cf558e17954ae0d | ||
| certifi==2024.6.2 | ||
| cffi==1.16.0 | ||
| chardet==5.2.0 | ||
| charset-normalizer==3.3.2 | ||
| click==8.1.7 | ||
| colorama==0.4.6 | ||
| coloredlogs==15.0.1 | ||
| contourpy==1.2.1 | ||
| crcmod==1.7 | ||
| cryptography==43.0.0 | ||
| cycler==0.12.1 | ||
| DataProperty==1.0.1 | ||
| datasets==2.18.0 | ||
| deepspeed @ http://10.6.10.68:8000/release/deepspeed/dtk24.04.1/deepspeed-0.12.3%2Bgita724046.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=2c158ed2dab21f4f09e7fc29776cb43a1593b13cec33168ce3483f318b852fc9 | ||
| dill==0.3.8 | ||
| dnspython==2.6.1 | ||
| dropout-layer-norm @ http://10.6.10.68:8000/release/flash_attn/dtk24.04.1/dropout_layer_norm-0.1%2Bdas1.1gitc7a8c18.abi1.dtk2404.torch2.1-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=ae10c7cc231a8e38492292e91e76ba710d7679762604c0a7f10964b2385cdbd7 | ||
| einops==0.8.0 | ||
| email_validator==2.1.1 | ||
| evaluate==0.4.2 | ||
| exceptiongroup==1.2.1 | ||
| fastapi==0.111.0 | ||
| fastapi-cli==0.0.4 | ||
| fastpt @ http://10.6.10.68:8000/release/fastpt/dtk24.04.1/fastpt-1.0.0%2Bdas1.1.abi1.dtk2404-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=ecf30dadcd2482adb1107991edde19b6559b8237379dbb0a3e6eb7306aad3f9a | ||
| filelock==3.15.1 | ||
| fire==0.6.0 | ||
| flash-attn @ http://10.6.10.68:8000/release/flash_attn/dtk24.04.1/flash_attn-2.0.4%2Bdas1.1gitc7a8c18.abi1.dtk2404.torch2.1-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=7ca8e78ee0624b1ff0e91e9fc265e61b9510f02123a010ac71a2f8e5d08a62f7 | ||
| flatbuffers==24.3.25 | ||
| fonttools==4.53.0 | ||
| frozenlist==1.4.1 | ||
| fsspec==2024.2.0 | ||
| fused-dense-lib @ http://10.6.10.68:8000/release/flash_attn/dtk24.04.1/fused_dense_lib-0.1%2Bdas1.1gitc7a8c18.abi1.dtk2404.torch2.1-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=7202dd258a86bb7a1572e3b44b90dae667b0c948bf0f420b05924a107aaaba03 | ||
| h11==0.14.0 | ||
| hjson==3.1.0 | ||
| httpcore==1.0.5 | ||
| httptools==0.6.1 | ||
| httpx==0.27.0 | ||
| huggingface-hub==0.23.4 | ||
| humanfriendly==10.0 | ||
| hypothesis==5.35.1 | ||
| idna==3.7 | ||
| importlib_metadata==7.1.0 | ||
| Jinja2==3.1.4 | ||
| jmespath==0.10.0 | ||
| joblib==1.4.2 | ||
| jsonlines==4.0.0 | ||
| jsonschema==4.22.0 | ||
| jsonschema-specifications==2023.12.1 | ||
| kiwisolver==1.4.5 | ||
| layer-check-pt @ http://10.6.10.68:8000/release/layercheck/dtk24.04.1/layer_check_pt-1.2.3.git59a087a.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=807adae2d4d4b74898777f81e1b94f1af4d881afe6a7826c7c910b211accbea7 | ||
| lightop @ http://10.6.10.68:8000/release/lightop/dtk24.04.1/lightop-0.4%2Bdas1.1git8e60f07.abi1.dtk2404.torch2.1-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=2f2c88fd3fe4be179f44c4849e9224cb5b2b259843fc5a2d088e468b7a14c1b1 | ||
| lm_eval==0.4.3 | ||
| lmdeploy @ http://10.6.10.68:8000/release/lmdeploy/dtk24.04.1/lmdeploy-0.2.6%2Bdas1.1.git6ba90df.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=92ecee2c8b982f86e5c3219ded24d2ede219f415bf2cd4297f989a03387a203c | ||
| lxml==5.2.2 | ||
| markdown-it-py==3.0.0 | ||
| MarkupSafe==2.1.5 | ||
| matplotlib==3.9.0 | ||
| mbstrdecoder==1.1.3 | ||
| mdurl==0.1.2 | ||
| mmcv @ http://10.6.10.68:8000/release/mmcv/dtk24.04.1/mmcv-2.0.1%2Bdas1.1.gite58da25.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=7a937ae22f81b44d9100907e11303c31bf9a670cb4c92e361675674a41a8a07f | ||
| mmengine==0.10.4 | ||
| mmengine-lite==0.10.4 | ||
| modelscope==1.16.1 | ||
| more-itertools==10.3.0 | ||
| mpmath==1.3.0 | ||
| msgpack==1.0.8 | ||
| multidict==6.0.5 | ||
| multiprocess==0.70.16 | ||
| networkx==3.3 | ||
| ninja==1.11.1.1 | ||
| nltk==3.8.1 | ||
| numexpr==2.10.1 | ||
| numpy==1.24.3 | ||
| onnxruntime @ http://10.6.10.68:8000/release/onnxruntime/dtk24.04.1/onnxruntime-1.15.0%2Bdas1.1.git739f24d.abi1.dtk2404-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=d0d24167188d2c85f1ed4110fc43e62ea40c74280716d9b5fe9540256f17869a | ||
| opencv-python==4.10.0.82 | ||
| orjson==3.10.5 | ||
| oss2==2.18.6 | ||
| packaging==24.1 | ||
| pandas==2.2.2 | ||
| pathvalidate==3.2.0 | ||
| peft==0.9.0 | ||
| pillow==10.3.0 | ||
| platformdirs==4.2.2 | ||
| portalocker==2.10.1 | ||
| prometheus_client==0.20.0 | ||
| protobuf==5.27.1 | ||
| psutil==5.9.8 | ||
| py-cpuinfo==9.0.0 | ||
| pyarrow==17.0.0 | ||
| pyarrow-hotfix==0.6 | ||
| pybind11==2.13.1 | ||
| pycparser==2.22 | ||
| pycryptodome==3.20.0 | ||
| pydantic==2.7.4 | ||
| pydantic_core==2.18.4 | ||
| Pygments==2.18.0 | ||
| pynvml==11.5.0 | ||
| pyparsing==3.1.2 | ||
| pytablewriter==1.2.0 | ||
| python-dateutil==2.9.0.post0 | ||
| python-dotenv==1.0.1 | ||
| python-multipart==0.0.9 | ||
| pytz==2024.1 | ||
| PyYAML==6.0.1 | ||
| ray==2.9.1 | ||
| referencing==0.35.1 | ||
| regex==2024.5.15 | ||
| requests==2.32.3 | ||
| rich==13.7.1 | ||
| rotary-emb @ http://10.6.10.68:8000/release/flash_attn/dtk24.04.1/rotary_emb-0.1%2Bdas1.1gitc7a8c18.abi1.dtk2404.torch2.1-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=cc15ec6ae73875515243d7f5c96ab214455a33a4a99eb7f1327f773cae1e6721 | ||
| rouge-score==0.1.2 | ||
| rpds-py==0.18.1 | ||
| sacrebleu==2.4.2 | ||
| safetensors==0.4.3 | ||
| scikit-learn==1.5.1 | ||
| scipy==1.13.1 | ||
| sentencepiece==0.2.0 | ||
| shellingham==1.5.4 | ||
| shortuuid==1.0.13 | ||
| six==1.16.0 | ||
| sniffio==1.3.1 | ||
| sortedcontainers==2.4.0 | ||
| sqlitedict==2.1.0 | ||
| starlette==0.37.2 | ||
| sympy==1.12.1 | ||
| tabledata==1.3.3 | ||
| tabulate==0.9.0 | ||
| tcolorpy==0.1.6 | ||
| termcolor==2.4.0 | ||
| threadpoolctl==3.5.0 | ||
| tiktoken==0.7.0 | ||
| tokenizers==0.15.0 | ||
| tomli==2.0.1 | ||
| torch @ http://10.6.10.68:8000/release/pytorch/dtk24.04.1/torch-2.1.0%2Bdas1.1.git3ac1bdd.abi1.dtk2404-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=5fd3bcef3aa197c0922727913aca53db9ce3f2fd4a9b22bba1973c3d526377f9 | ||
| torchaudio @ http://10.6.10.68:8000/release/torchaudio/dtk24.04.1/torchaudio-2.1.2%2Bdas1.1.git63d9a68.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=4fcc556a7a2fffe64ddd57f22e5972b1b2b723f6fdfdaa305bd01551036df38b | ||
| torchvision @ http://10.6.10.68:8000/release/vision/dtk24.04.1/torchvision-0.16.0%2Bdas1.1.git7d45932.abi1.dtk2404.torch2.1-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=e3032e1bcc0857b54391d66744f97e5cff0dc7e7bb508196356ee927fb81ec01 | ||
| tqdm==4.66.4 | ||
| tqdm-multiprocess==0.0.11 | ||
| transformers==4.39.0 | ||
| triton @ http://10.6.10.68:8000/release/triton/dtk24.04.1/triton-2.1.0%2Bdas1.1.git4bf1007a.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=4c30d45dab071e65d1704a5cd189b14c4ac20bd59a7061032dfd631b1fc37645 | ||
| typepy==1.3.2 | ||
| typer==0.12.3 | ||
| typing_extensions==4.12.2 | ||
| tzdata==2024.1 | ||
| ujson==5.10.0 | ||
| urllib3==2.2.1 | ||
| uvicorn==0.30.1 | ||
| uvloop==0.19.0 | ||
| vllm @ http://10.6.10.68:8000/release/vllm/dtk24.04.1/vllm-0.3.3%2Bdas1.1.gitdf6349c.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=48d265b07efa36f028eca45a3667fa10d3cf30eb1b8f019b62e3b255fb9e49c4 | ||
| watchfiles==0.22.0 | ||
| websockets==12.0 | ||
| word2number==1.1 | ||
| xentropy-cuda-lib @ http://10.6.10.68:8000/release/flash_attn/dtk24.04.1/xentropy_cuda_lib-0.1%2Bdas1.1gitc7a8c18.abi1.dtk2404.torch2.1-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=91b058d6a5fd2734a5085d68e08d3a1f948fe9c0119c46885d19f55293e2cce4 | ||
| xformers @ http://10.6.10.68:8000/release/xformers/dtk24.04.1/xformers-0.0.25%2Bdas1.1.git8ef8bc1.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl#sha256=ca87fd065753c1be3b9fad552eba02d30cd3f4c673f01e81a763834eb5cbb9cc | ||
| xxhash==3.4.1 | ||
| yapf==0.40.2 | ||
| yarl==1.9.4 | ||
| zipp==3.19.2 | ||
| zstandard==0.23.0 |
run-eval.sh
0 → 100644
run.sh
0 → 100644
setup.py
0 → 100644
train-demo.py
0 → 100644
图片1.png
0 → 100644
{kind=link}
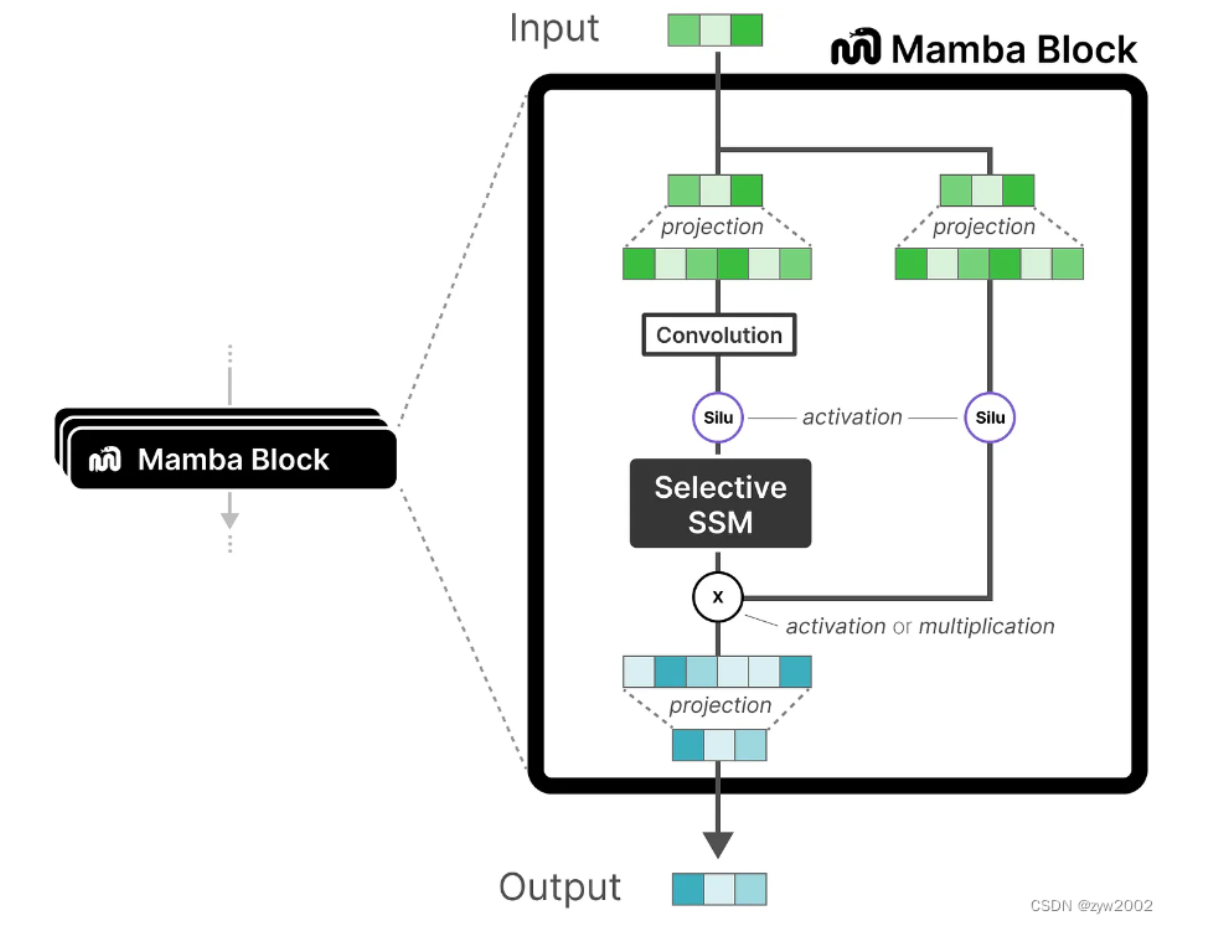
165 KB
图片2.jpg
0 → 100644
{kind=link}
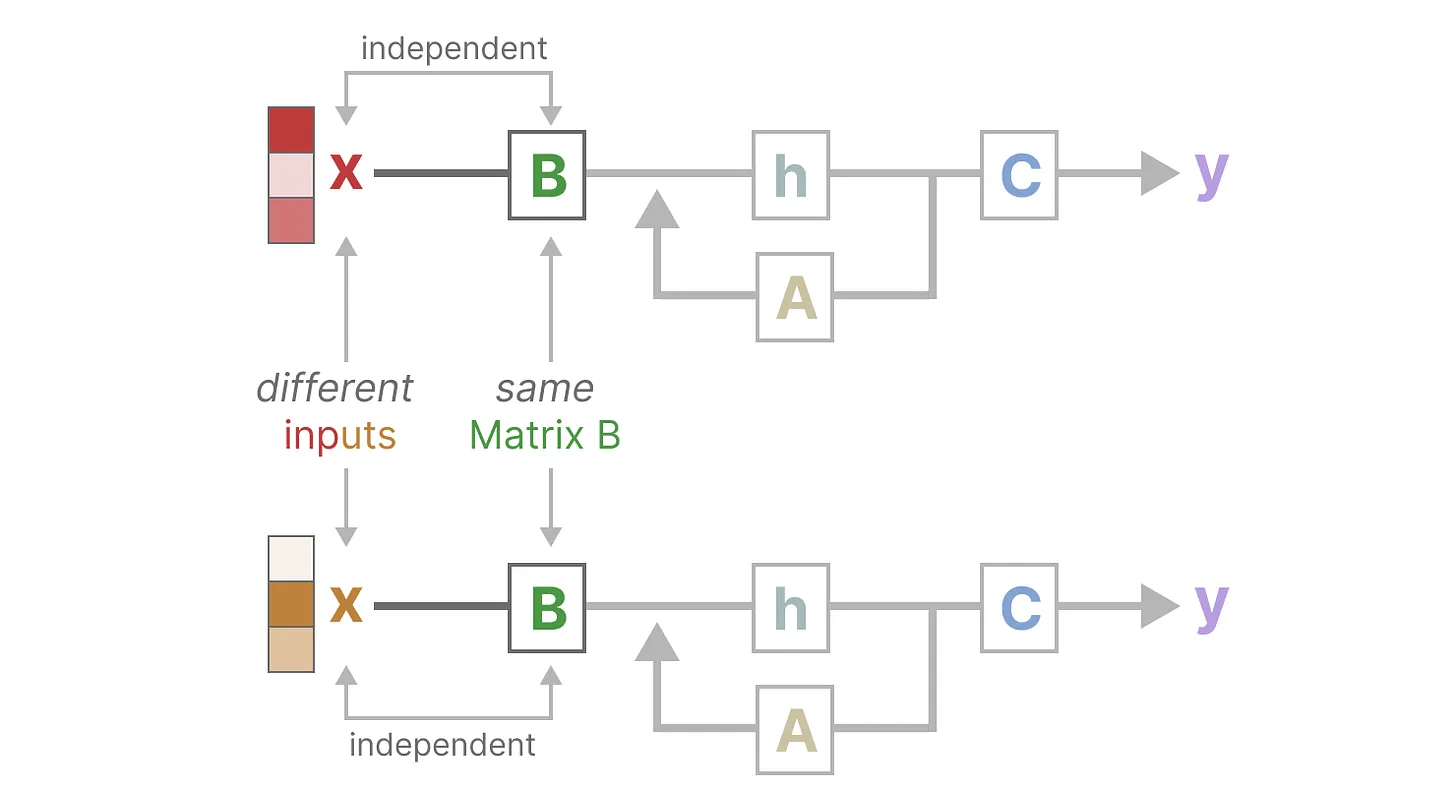
134 KB
图片3.jpg
0 → 100644
{kind=link}
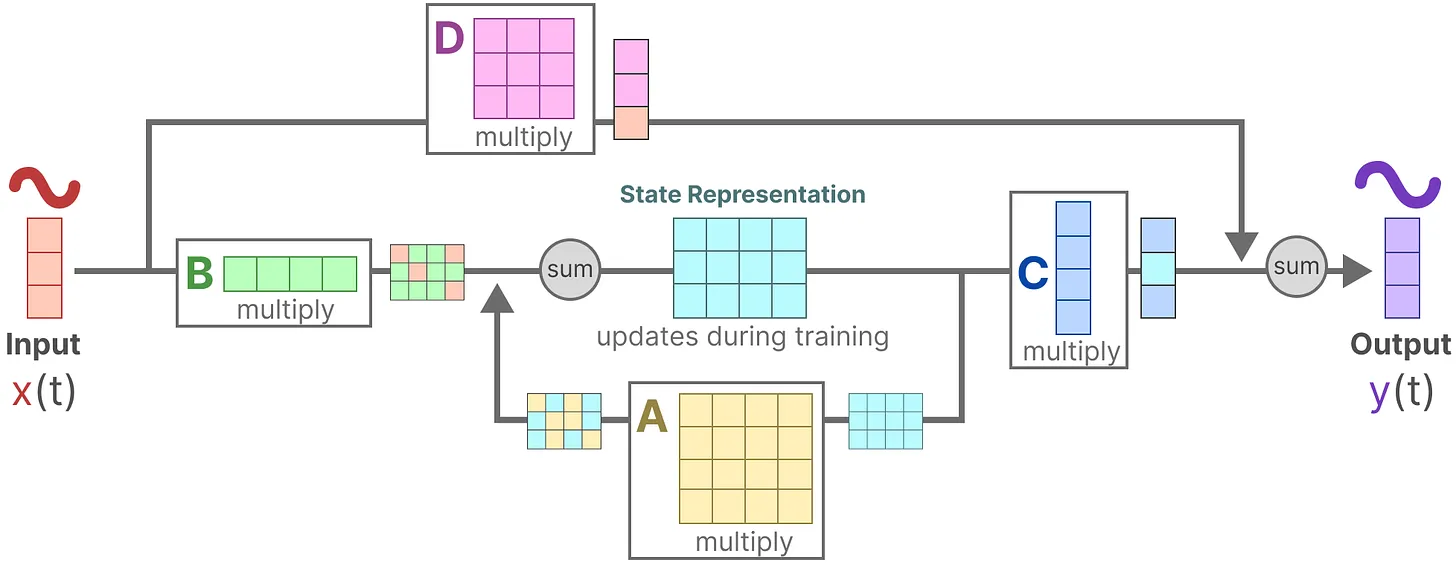
182 KB
图片4.jpg
0 → 100644
{kind=link}

46.9 KB
图片5.jpg
0 → 100644
{kind=link}

26.5 KB