
修改readme
Showing
assets/selection.png
0 → 100644
{kind=link}
799 KB
assets/ssd_algorithm.png
0 → 100644
{kind=link}
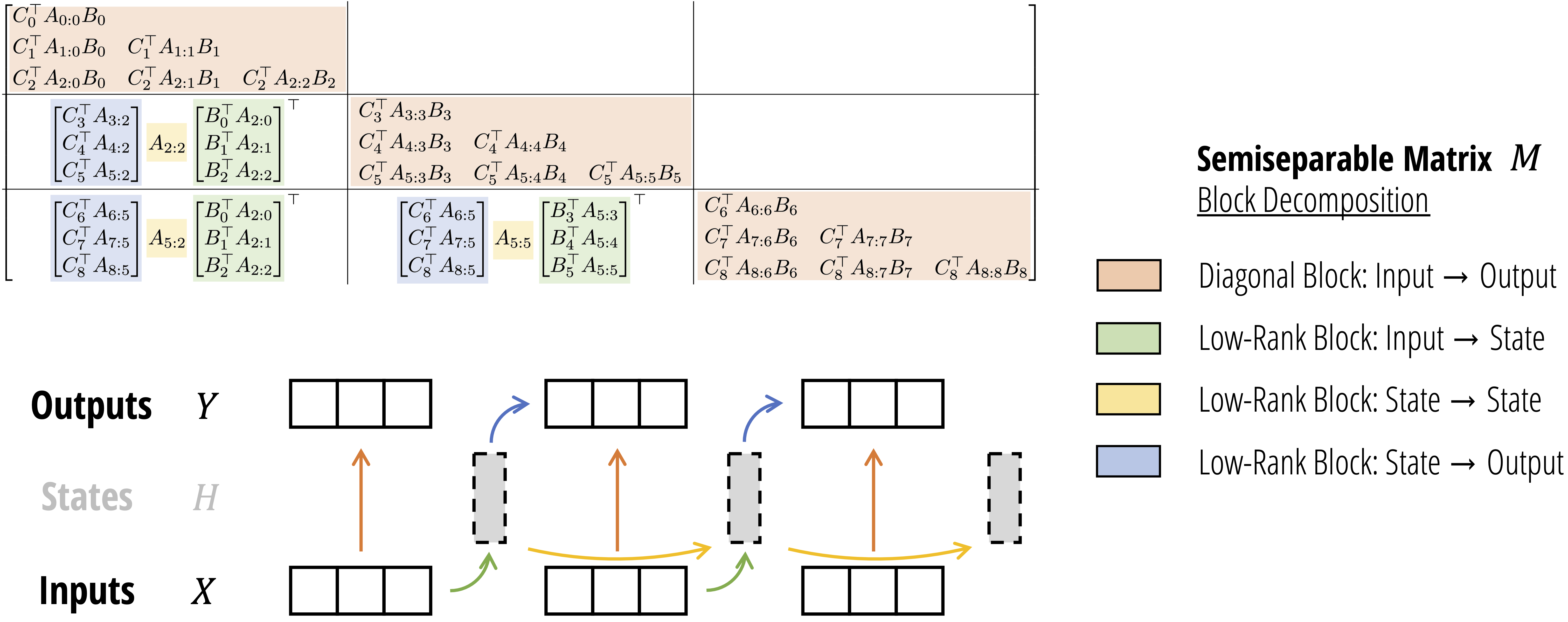
1.07 MB
causal-conv1d-1.4.0/AUTHORS
0 → 100644
causal-conv1d-1.4.0/LICENSE
0 → 100644
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.