
add llama inference by tgi tutorial
parents
Showing
.gitmodules
0 → 100644
README.md
0 → 100644
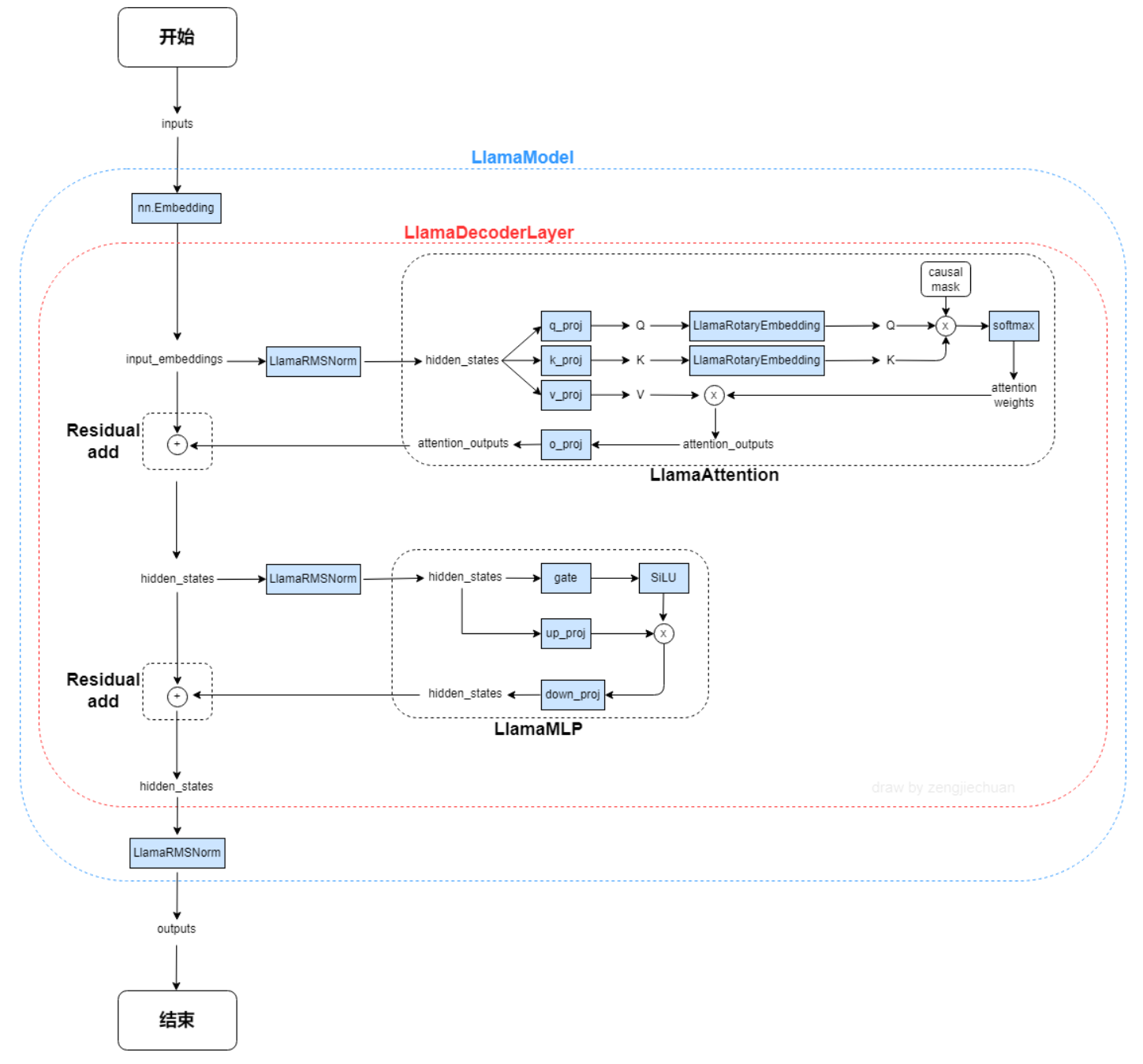
docs/llama_pri.png
0 → 100644
{kind=link}
188 KB
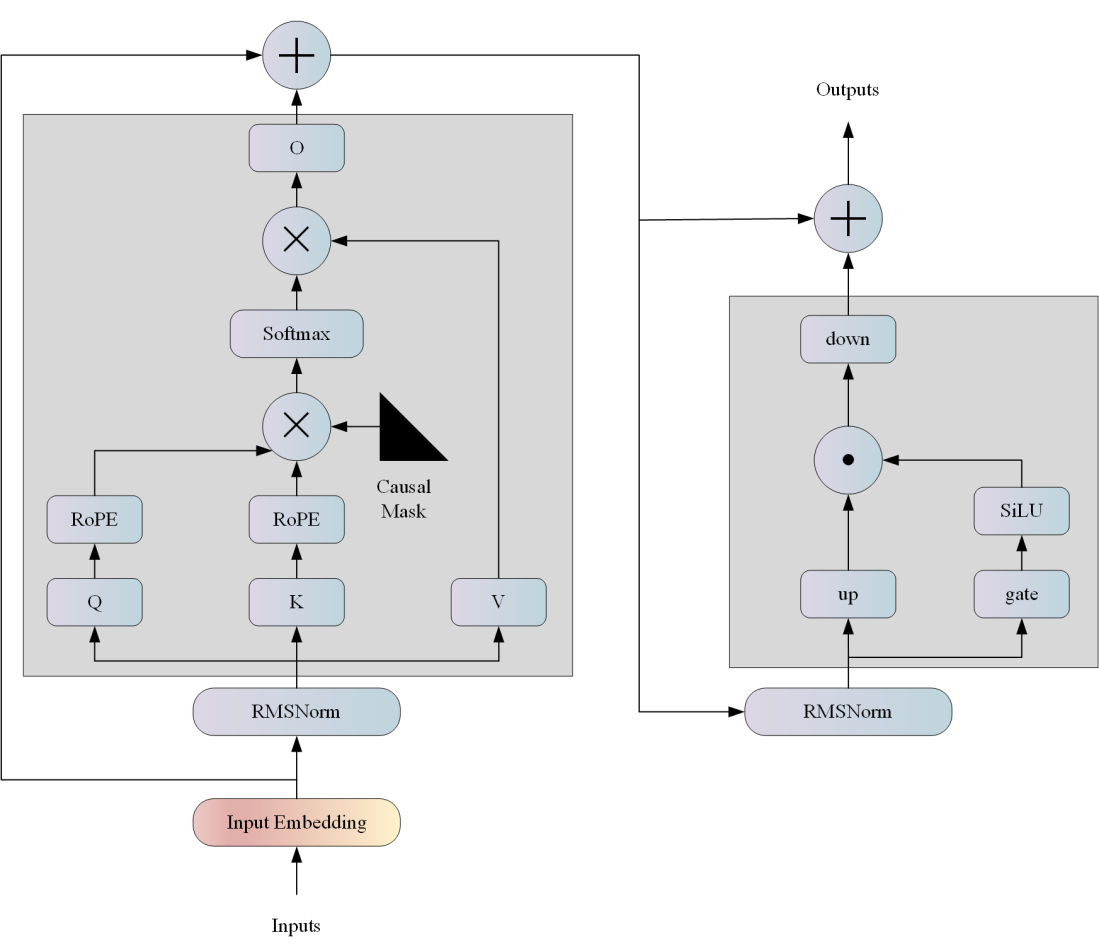
docs/llama_str.png
0 → 100644
{kind=link}
77.3 KB
text-generation-inference @ 6e6d3c1a