Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
LLaMA_TencentPretrain_pytorch
Commits
b9017ab3
Commit
b9017ab3
authored
Sep 08, 2023
by
zhaoying1
Browse files
re-organize the code
parent
ea2d13c2
Changes
3
Hide whitespace changes
Inline
Side-by-side
Showing
3 changed files
with
95 additions
and
42 deletions
+95
-42
README.md
README.md
+87
-36
data/media/llamaa.png
data/media/llamaa.png
+0
-0
model.properties
model.properties
+8
-6
No files found.
README.md
View file @
b9017ab3
##
基于TencentPretrain框架的
LLaMA
微调训练
## LLaMA
## 论文
`LLaMA: Open and Efficient Foundation Language Models`
## 模型介绍
-
[
https://arxiv.org/abs/2302.13971
](
https://arxiv.org/abs/2302.13971
)
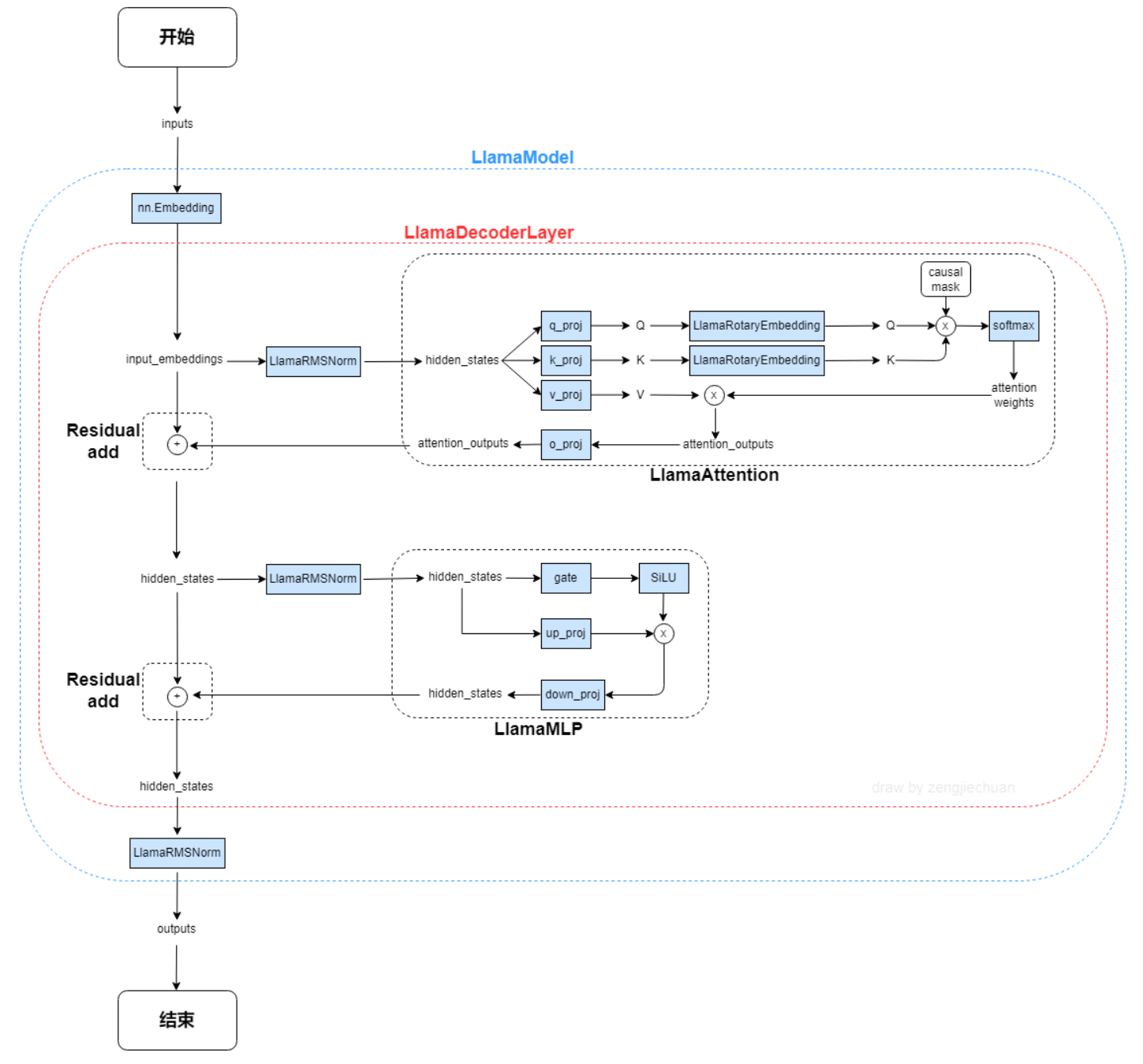
LLaMA,这是一个基础语言模型的集合,参数范围从7B到65B。在数万亿的tokens上训练出的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而不依赖于专有的和不可访问的数据集。特别是,llama 13B在大多数基准测试中优于GPT-3 (175B), LLaMA 65B与最好的模型Chinchilla-70B和PaLM-540B具有竞争力。
LLAMA网络基于 Transformer 架构。提出了各种改进,并用于不同的模型,例如 PaLM。以下是与原始架构的主要区别:
`Llama 2: Open Foundation and Fine-Tuned Chat Models`
**预归一化**
。为了提高训练稳定性,对每个transformer 子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。
-
[
https://arxiv.org/abs/2307.09288
](
https://arxiv.org/abs/2307.09288
)
**SwiGLU 激活函数 [PaLM]**
。使用 SwiGLU 激活函数替换 ReLU 非线性以提高性能。使用 2 /3 4d 的维度而不是 PaLM 中的 4d。
## 模型结构
LLaMA,这是一个基础语言模型的集合,参数范围从7B到65B。在数万亿的tokens上训练出的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而不依赖于专有的和不可访问的数据集。特别是,llama 13B在大多数基准测试中优于GPT-3 (175B), LLaMA 65B与最好的模型Chinchilla-70B和PaLM-540B具有竞争力。LLAMA网络基于 Transformer 架构。提出了各种改进,并用于不同的模型,例如 PaLM。
**旋转嵌入**
。移除了绝对位置嵌入,而是添加了旋转位置嵌入 (RoPE),在网络的每一层。
LLaMA
2是LLaMA的新一代版本,具有商业友好的许可证。 LLaMA 2 有 3 种不同的尺寸:7B、13B 和 70B。Llama 2训练语料相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。Llama 2采用了 Llama 1 的大部分预训练设置和模型架构,使用标准Transformer 架构,使用 RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE。具体细节可参考论文
:
LLaMA
模型具体参数
:
[
Llama 2: Open Foundation and Fine-Tuned Chat Models
](
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
)
| 模型名称 | 隐含层维度 | 层数 | 头数 | 词表大小 | 训练数据(tokens) | 位置编码 | 最大长 |
| -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
| LLaMA-7B | 4,096 | 32 | 32 | 32,000 |1T | RoPE | 2048 |
| LLaMA-13B | 5,120 | 40 | 40 | 32,000 |1T | RoPE | 2048 |
[
LLaMA: Open and Efficient Foundation Language Models
](
https://arxiv.org/pdf/2302.13971v1.pdf
)
### 依赖环境
<div
align=
"center"
>
*
Python >= 3.6
<img
src=
"./data/media/llamaa.png"
width=
"600"
height=
"500"
>
*
[
torch >= 1.1
](
https://cancon.hpccube.com:65024/4/main/pytorch/dtk23.04
)
</div>
*
six >= 1.12.0
*
argparse
*
packaging
*
regex
*
[
DeepSpeed
](
https://cancon.hpccube.com:65024/4/main/deepspeed/dtk23.04
)
推荐使用docker方式运行,提供
[
光源
](
https://www.sourcefind.cn/#/service-list
)
拉取的docker镜像:image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py37-latest
LLaMA 2是LLaMA的新一代版本,具有商业友好的许可证。 LLaMA 2 有 3 种不同的尺寸:7B、13B 和 70B。Llama 2训练语料相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。Llama 2采用了 Llama 1 的大部分预训练设置和模型架构,使用标准Transformer 架构,使用 RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE。
#### Docker配置方式
```
commandline
## 算法原理
以下是与原始架构的主要区别:
**预归一化**
。为了提高训练稳定性,对每个transformer 子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。
**SwiGLU 激活函数**
。使用 SwiGLU 激活函数替换 ReLU 非线性以提高性能。使用 2 /3 4d 的维度而不是 PaLM 中的 4d。
**旋转嵌入**
。移除了绝对位置嵌入,而是添加了旋转位置嵌入 (RoPE),在网络的每一层。
## 环境配置
### Docker(方式一)
推荐使用docker方式运行,提供拉取的docker镜像:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py37-latest
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py37-latest
```
进入docker,安装docker中没有的依赖:
```
docker run -dit --network=host --name=llama-tencentpretrain --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py37-latest
docker run -dit --network=host --name=llama-tencentpretrain --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py37-latest
docker exec -it llama-tencentpretrain /bin/bash
docker exec -it llama-tencentpretrain /bin/bash
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
```
也可从目录下的
Dockerfile
构建镜像:
###
Dockerfile
(方式二)
```
commandline
```
docker build -t llama:latest .
docker build -t llama:latest .
docker run -dit --network=host --name=llama-tencentpretrain --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 llama:latest
docker run -dit --network=host --name=llama-tencentpretrain --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 llama:latest
docker exec -it llama-tencentpretrain /bin/bash
```
```
### Conda(方法三)
1.
创建conda虚拟环境:
```
conda create -n chatglm python=3.7
```
2.
关于本项目DCU显卡所需的工具包、深度学习库等均可从
[
光合
](
https://developer.hpccube.com/tool/
)
开发者社区下载安装。
-
[
DTK 23.04
](
https://cancon.hpccube.com:65024/1/main/DTK-23.04.1
)
-
[
Pytorch 1.13.1
](
https://cancon.hpccube.com:65024/4/main/pytorch/dtk23.04
)
-
[
Deepspeed 0.9.2
](
https://cancon.hpccube.com:65024/4/main/deepspeed/dtk23.04
)
Tips:以上dtk驱动、python、deepspeed等工具版本需要严格一一对应。
3.
其它依赖库参照requirements.txt安装:
```
pip install -r requirements.txt
```
### 模型权重下载
## 数据集
我们在
[
data
](
./data
)
目录下集成了中文公开指令数据集
[
alpaca_gpt4_data_zh.json
](
https://huggingface.co/datasets/shibing624/alpaca-zh
)
,供用户快速验证:
```
./data/alpaca_gpt4_data_zh.json
```
## 模型权重下载
1.
方式一:下载huggingface格式模型。以 7B 模型为例,首先下载预训练
[
LLaMA权重
](
https://huggingface.co/decapoda-research/llama-7b-hf
)
,转换到TencentPretrain格式:
1.
方式一:下载huggingface格式模型。以 7B 模型为例,首先下载预训练
[
LLaMA权重
](
https://huggingface.co/decapoda-research/llama-7b-hf
)
,转换到TencentPretrain格式:
```
commandline
```
commandline
python3 scripts/convert_llama_from_huggingface_to_tencentpretrain.py --input_model_path $LLaMA_HF_PATH \
python3 scripts/convert_llama_from_huggingface_to_tencentpretrain.py --input_model_path $LLaMA_HF_PATH \
...
@@ -54,8 +93,8 @@ python3 scripts/convert_llama_from_huggingface_to_tencentpretrain.py --input_mod
...
@@ -54,8 +93,8 @@ python3 scripts/convert_llama_from_huggingface_to_tencentpretrain.py --input_mod
```
```
2.
方式二:也可以直接下载
[
TencentPretrain对应格式模型
](
https://huggingface.co/Linly-AI/
)
进行微调训练,不需要转换格式。
2.
方式二:也可以直接下载
[
TencentPretrain对应格式模型
](
https://huggingface.co/Linly-AI/
)
进行微调训练,不需要转换格式。
##
#
全参数增量预训练
## 全参数增量预训练
###
##
数据预处理
### 数据预处理
1.
构建预训练数据集
1.
构建预训练数据集
txt预训练语料:多个txt需要合并到一个 .txt 文件并按行随机打乱,语料格式如下:
txt预训练语料:多个txt需要合并到一个 .txt 文件并按行随机打乱,语料格式如下:
...
@@ -79,7 +118,7 @@ python3 preprocess.py --corpus_path $CORPUS_PATH --spm_model_path $LLaMA_PATH/to
...
@@ -79,7 +118,7 @@ python3 preprocess.py --corpus_path $CORPUS_PATH --spm_model_path $LLaMA_PATH/to
可选参数: --json_format_corpus:使用jsonl格式数据;
可选参数: --json_format_corpus:使用jsonl格式数据;
--full_sentences:对长度不足的样本使用其他样本进行填充(没有 pad token);
--full_sentences:对长度不足的样本使用其他样本进行填充(没有 pad token);
###
## 增量预
训练
###
训练
1.
单机
1.
单机
```
commandline
```
commandline
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
...
@@ -96,8 +135,10 @@ deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_conf
...
@@ -96,8 +135,10 @@ deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_conf
cd slurm_scripts
cd slurm_scripts
bash run-pt.sh
bash run-pt.sh
```
```
### 全参数指令微调
##### 数据预处理
## 全参数指令微调
#### 数据预处理
1.
构建指令数据集:指令数据为 json 格式,包含instruction、input、output三个字段(可以为空),每行一条样本。
1.
构建指令数据集:指令数据为 json 格式,包含instruction、input、output三个字段(可以为空),每行一条样本。
示例:
示例:
```
commandline
```
commandline
...
@@ -109,7 +150,7 @@ bash run-pt.sh
...
@@ -109,7 +150,7 @@ bash run-pt.sh
python3 preprocess.py --corpus_path $INSTRUCTION_PATH --spm_model_path $LLaMA_PATH/tokenizer.model \
python3 preprocess.py --corpus_path $INSTRUCTION_PATH --spm_model_path $LLaMA_PATH/tokenizer.model \
--dataset_path $OUTPUT_DATASET_PATH --data_processor alpaca --seq_length 1024
--dataset_path $OUTPUT_DATASET_PATH --data_processor alpaca --seq_length 1024
```
```
###
## 微调
训练
###
训练
1.
单机
1.
单机
```
commandline
```
commandline
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
...
@@ -128,7 +169,7 @@ bash run-ift.sh
...
@@ -128,7 +169,7 @@ bash run-ift.sh
```
```
##
#
模型分块
## 模型分块
训练初始化时,每张卡会加载一个模型的拷贝,因此内存需求为模型大小
*
GPU数量。内存不足时可以通过以下方式将模型分块,然后使用分块加载。
训练初始化时,每张卡会加载一个模型的拷贝,因此内存需求为模型大小
*
GPU数量。内存不足时可以通过以下方式将模型分块,然后使用分块加载。
```
commandline
```
commandline
python3 scripts/convert_model_into_blocks.py \
python3 scripts/convert_model_into_blocks.py \
...
@@ -138,11 +179,11 @@ python3 scripts/convert_model_into_blocks.py \
...
@@ -138,11 +179,11 @@ python3 scripts/convert_model_into_blocks.py \
```
```
其中,--input_model_path 输入模型路径; --output_model_path 输出模型目录; --block_size 分块大小;在训练加载模型时,将 pretrained_model_path 改为以上输出的目录即可。
其中,--input_model_path 输入模型路径; --output_model_path 输出模型目录; --block_size 分块大小;在训练加载模型时,将 pretrained_model_path 改为以上输出的目录即可。
##
# 模型
推理
##
推理
TencentPretrain格式模型推理请参考
[
LLAMA
_pytorch
](
https://developer.hpccube.com/codes/modelzoo/llama_pytorch
)
TencentPretrain格式模型推理请参考
[
llama_inference
_pytorch
](
https://developer.hpccube.com/codes/modelzoo/llama_
inference_
pytorch
)
###
训练实验结果
###
Results
-
利用公开指令数据集
[
alpaca_gpt4_data_zh.json
](
https://huggingface.co/datasets/shibing624/alpaca-zh
)
,基于汉化ChineseLLaMA的7B、13B基础模型,我们进行指令微调训练实验,以下为训练Loss:
-
利用公开指令数据集
[
alpaca_gpt4_data_zh.json
](
https://huggingface.co/datasets/shibing624/alpaca-zh
)
,基于汉化ChineseLLaMA的7B、13B基础模型,我们进行指令微调训练实验,以下为训练Loss:
<div
align=
"center"
>
<div
align=
"center"
>
<figure
class=
"half"
>
<figure
class=
"half"
>
...
@@ -156,9 +197,19 @@ TencentPretrain格式模型推理请参考[LLAMA_pytorch](https://developer.hpcc
...
@@ -156,9 +197,19 @@ TencentPretrain格式模型推理请参考[LLAMA_pytorch](https://developer.hpcc
<img
src=
"./data/media/ift_llama2_7B_bs2_32node_128cards.jpg"
width=
"300"
height=
"250"
>
<img
src=
"./data/media/ift_llama2_7B_bs2_32node_128cards.jpg"
width=
"300"
height=
"250"
>
</div>
</div>
## 应用场景
### 算法类别
`自然语言处理`
### 热点应用行业
`nlp,智能聊天助手,科研`
## 源码仓库及问题反馈
## 源码仓库及问题反馈
-
https://developer.hpccube.com/codes/modelzoo/llama
1-2
-
https://developer.hpccube.com/codes/modelzoo/llama
_tencentpretrain_pytorch
## 参考
## 参考
...
...
data/media/llamaa.png
0 → 100644
View file @
b9017ab3
188 KB
model.properties
View file @
b9017ab3
# 模型唯一标识
modelCode
=
408
# 模型名称
# 模型名称
modelName
=
LLaMA(T
encent
P
retrain
)_P
ytorch
modelName
=
llama_t
encent
p
retrain
_p
ytorch
# 模型描述
# 模型描述
modelDescription
=
基于
Pytorch框架的LLaMA微调训练
modelDescription
=
基于
tencentpretrain训练框架的llama
# 应用场景
(多个标签以英文逗号分割)
# 应用场景
appScenario
=
训练,train,nlp,智能聊天助手
appScenario
=
训练,
推理,
train,
inference,
nlp,智能聊天助手
# 框架类型
(多个标签以英文逗号分割)
# 框架类型
frameType
=
Pytorch
frameType
=
Pytorch
,Transformers,Deepspeed
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}