"backend/vscode:/vscode.git/clone" did not exist on "9755cd5baa367620f6b1f08ef0565498c505e10b"

First commit
Showing
LICENSE
0 → 100644
README.md
0 → 100644
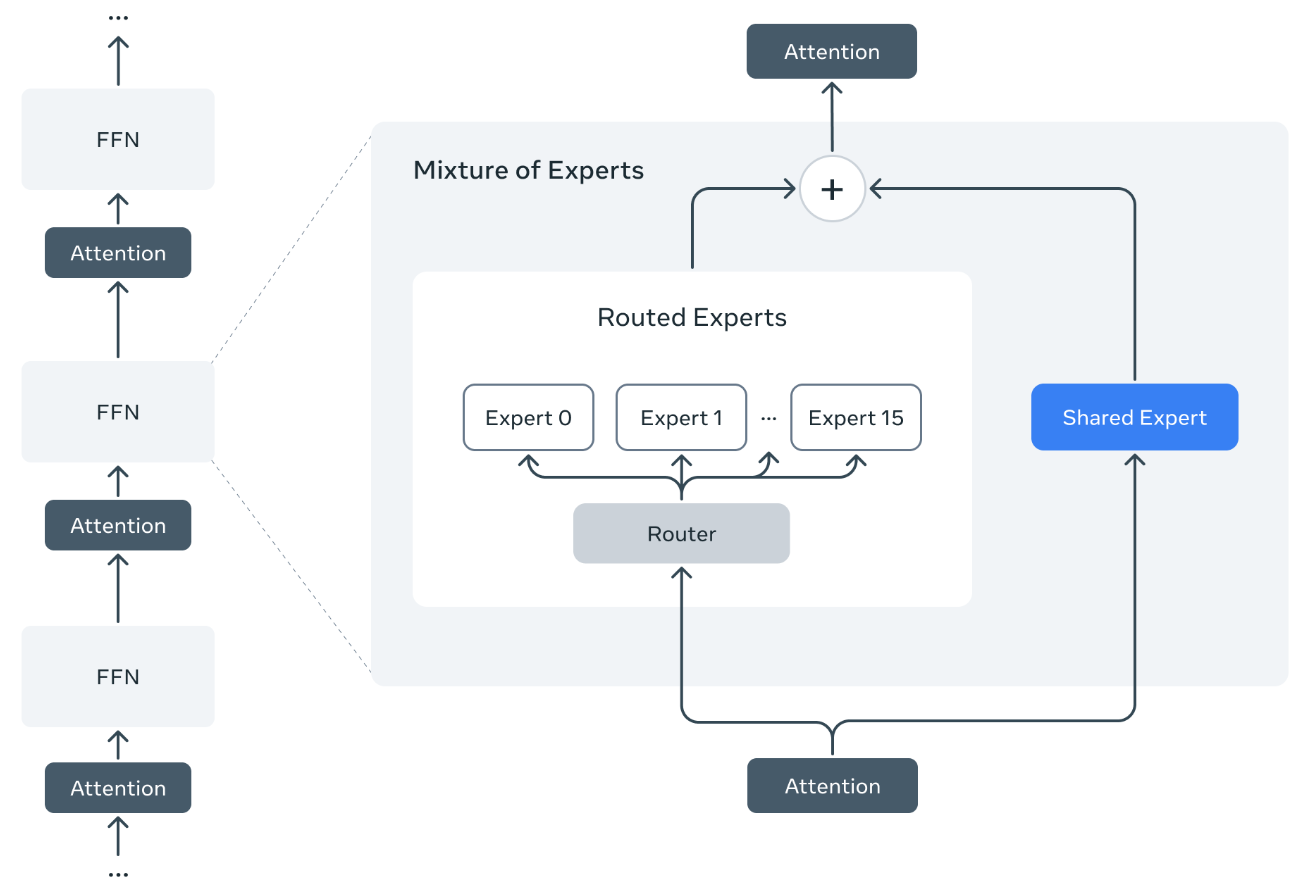
doc/method.png
0 → 100644
{kind=link}
85.8 KB
docker/Dockerfile
0 → 100644
infer_transformers.py
0 → 100644
infer_vllm.py
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| # This file was autogenerated by uv via the following command: | |||
| # uv export --frozen --no-hashes --no-emit-project --output-file=requirements.txt | |||
| annotated-types==0.7.0 | |||
| certifi==2025.1.31 | |||
| charset-normalizer==3.4.1 | |||
| idna==3.10 | |||
| jinja2==3.1.6 | |||
| markupsafe==3.0.2 | |||
| pillow==11.1.0 | |||
| pydantic==2.10.6 | |||
| pydantic-core==2.27.2 | |||
| pyyaml==6.0.2 | |||
| regex==2024.11.6 | |||
| requests==2.32.3 | |||
| tiktoken==0.8.0 | |||
| typing-extensions==4.12.2 | |||
| urllib3==2.3.0 | |||
| \ No newline at end of file |