多卡微调Qwen72B
家好我遇到一个问题,我在使用四卡海光K100想要lora微调Qwen2.5 72B模型,使用到的是社区gitlab提供的llama-factory框架。我在加载模型的时候,四张卡的显存占用迅速同步上涨,在加载第17个safetensors开始OOM。请问是哪里存在问题?请大家不吝赐教,感谢
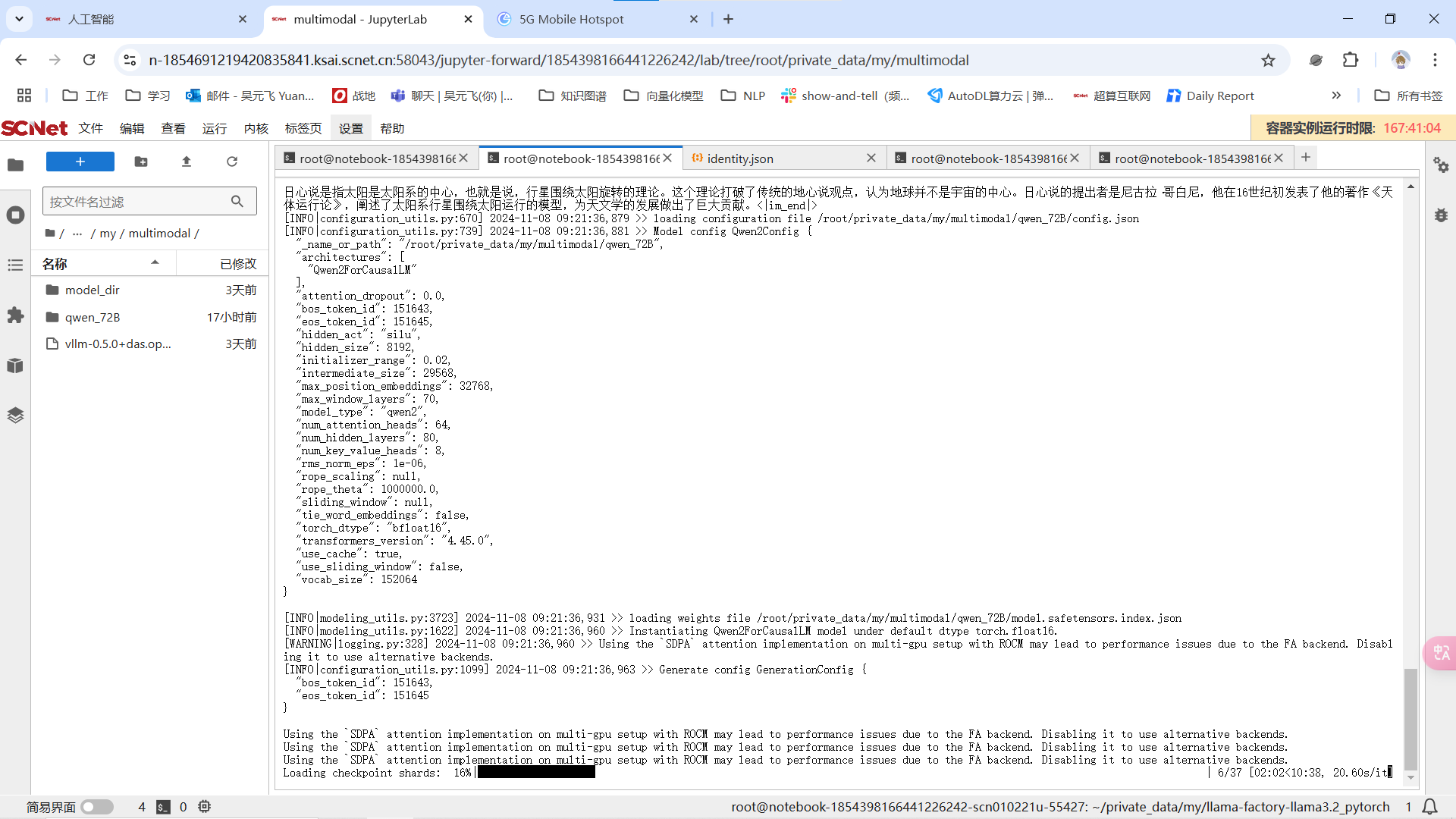
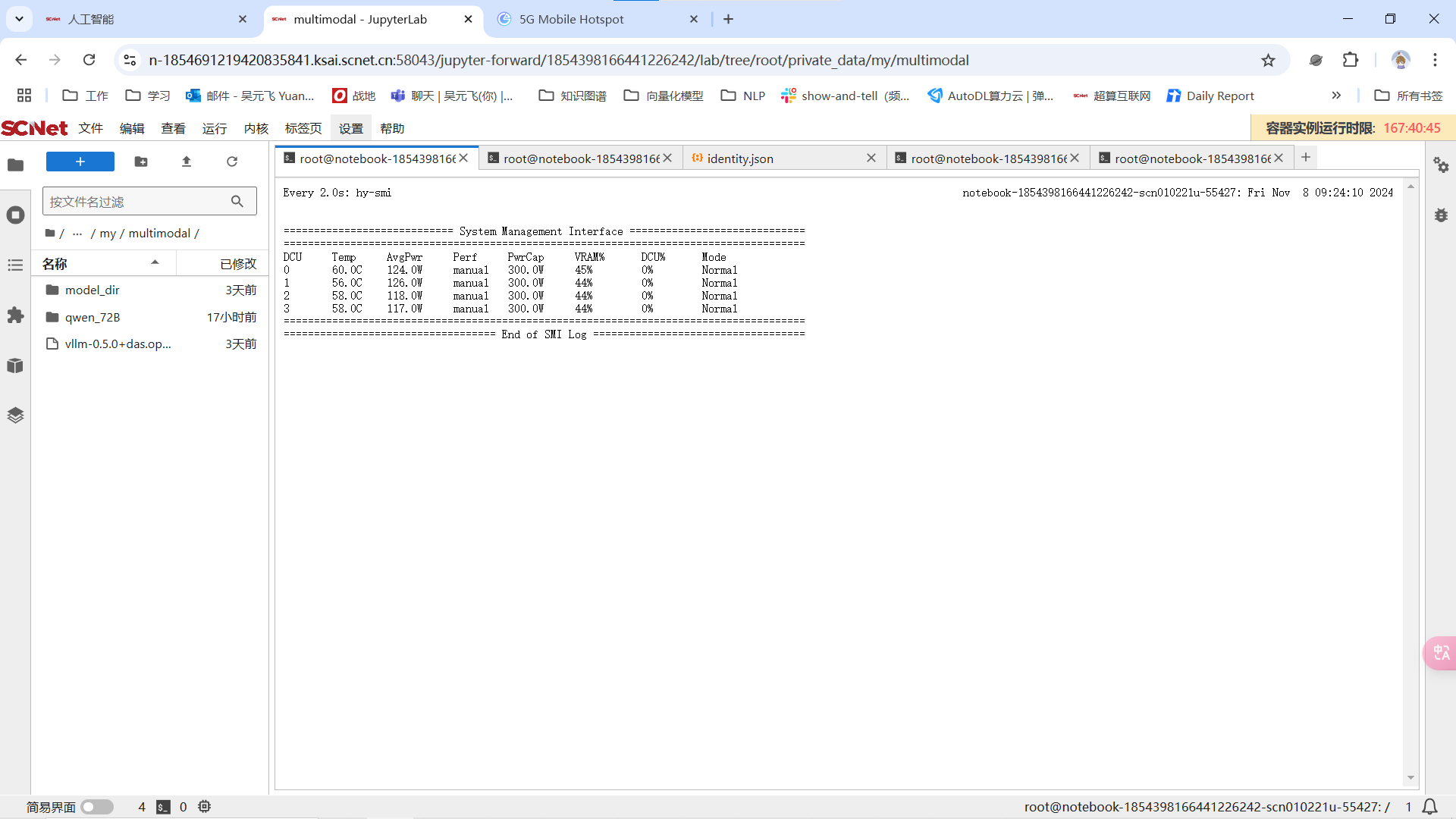
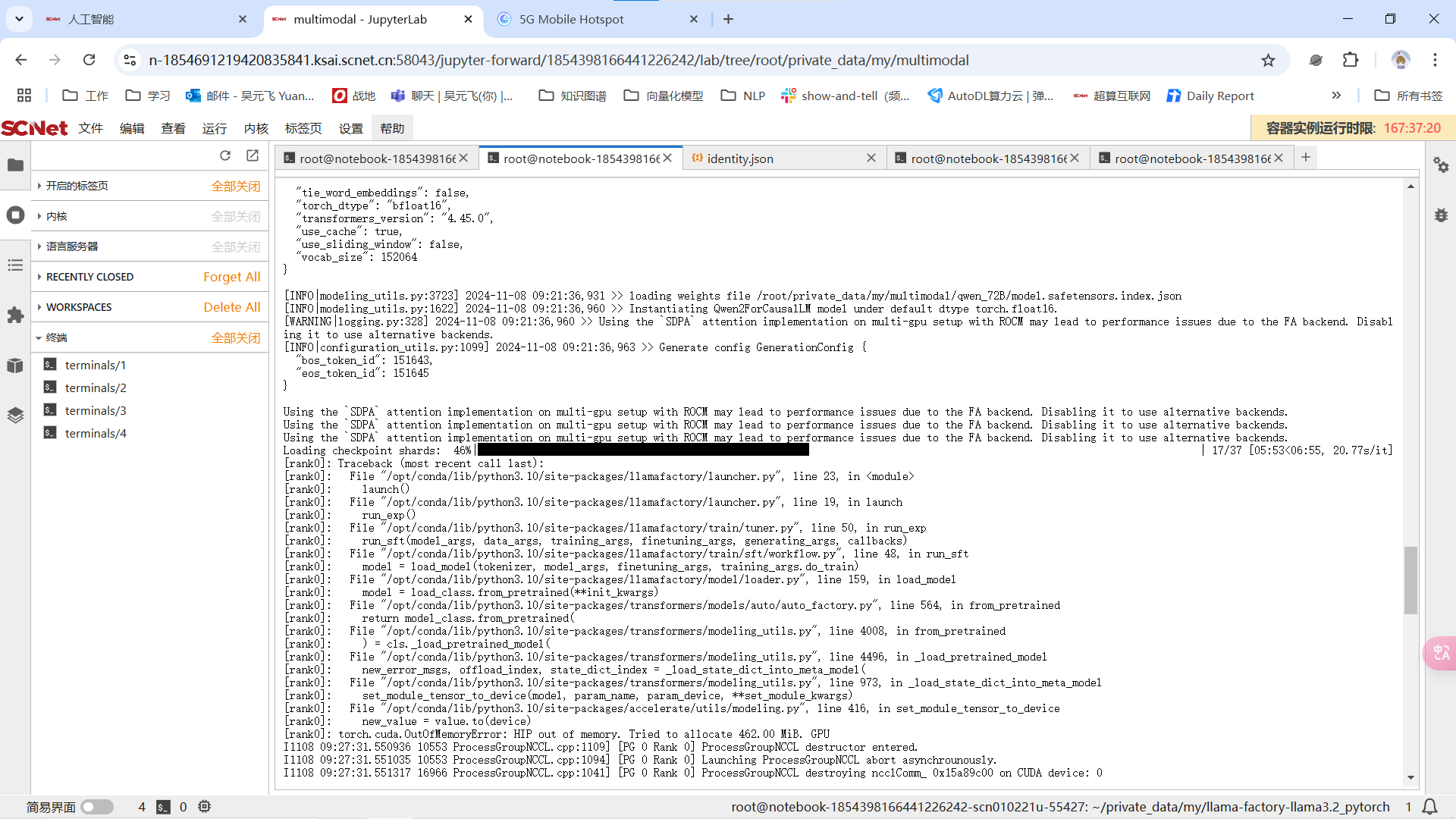 我的指令如下:
我的指令如下:
#!/bin/bash
source activate llama_factory
CUDA_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train
--stage sft
--do_train
--model_name_or_path /root/private_data/my/multimodal/qwen_72B
--dataset alpaca_zh_demo
--dataset_dir ./data
--template qwen
--finetuning_type lora
--output_dir ./saves/qwen_72/lora/sft_2_gpu
--overwrite_cache
--overwrite_output_dir
--cutoff_len 1024
--preprocessing_num_workers 16
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--gradient_accumulation_steps 8
--lr_scheduler_type cosine
--logging_steps 50
--warmup_steps 20
--save_steps 100
--eval_steps 50
--evaluation_strategy steps
--load_best_model_at_end
--learning_rate 5e-5
--num_train_epochs 5.0
--max_samples 1000
--val_size 0.1
--plot_loss
--fp16