
liveportrait
Showing
assets/gradio_title.md
0 → 100644
icon.png
0 → 100644
{kind=link}
68.4 KB
inference.py
0 → 100644
model.properties
0 → 100644
pretrained_weights/.gitkeep
0 → 100644
readme_imgs/alg.png
0 → 100644
{kind=link}
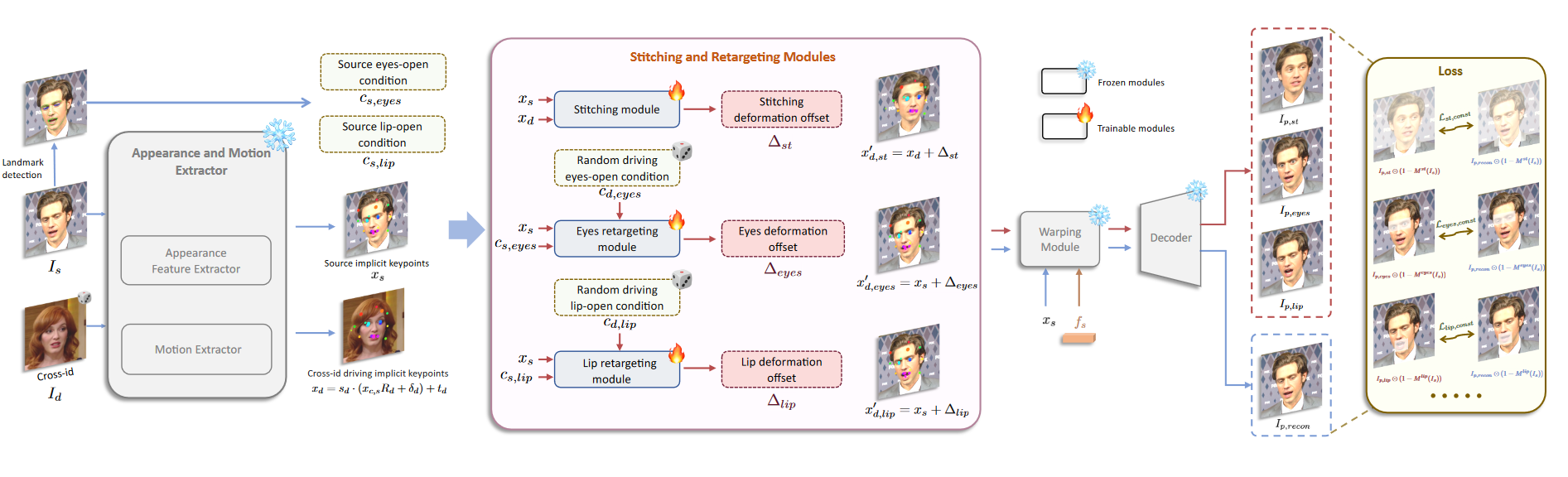
456 KB
readme_imgs/d0.gif
0 → 100644
{kind=link}

1.76 MB
readme_imgs/model.png
0 → 100644
{kind=link}

379 KB
readme_imgs/s20d19.gif
0 → 100644
{kind=link}
This image diff could not be displayed because it is too large. You can view the blob instead.
readme_imgs/s7.jpg
0 → 100644
{kind=link}

137 KB
readme_imgs/s7d0.gif
0 → 100644
{kind=link}

2.98 MB
readme_official.md
0 → 100644
requirements.txt
0 → 100644
| -r requirements_base.txt | |||
| onnxruntime-gpu==1.18.0 |
requirements_base.txt
0 → 100644
requirements_docker.txt
0 → 100644
requirements_macOS.txt
0 → 100644
speed.py
0 → 100644
src/config/__init__.py
0 → 100644
src/config/base_config.py
0 → 100644