
kolors
Showing
This diff is collapsed.
kolors/pipelines/__init__.py
0 → 100755
This diff is collapsed.
model.properties
0 → 100755
readme_imgs/alg.png
0 → 100755
{kind=link}
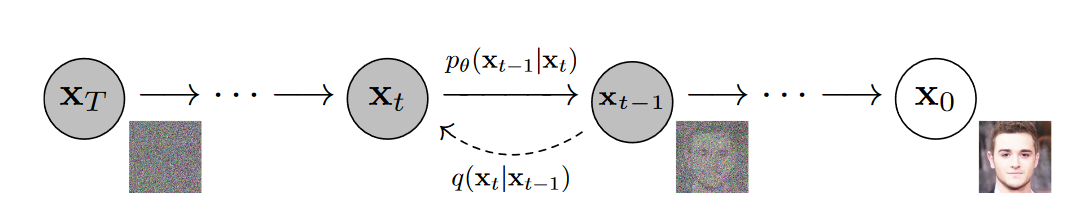
72.3 KB
readme_imgs/arch.png
0 → 100755
{kind=link}
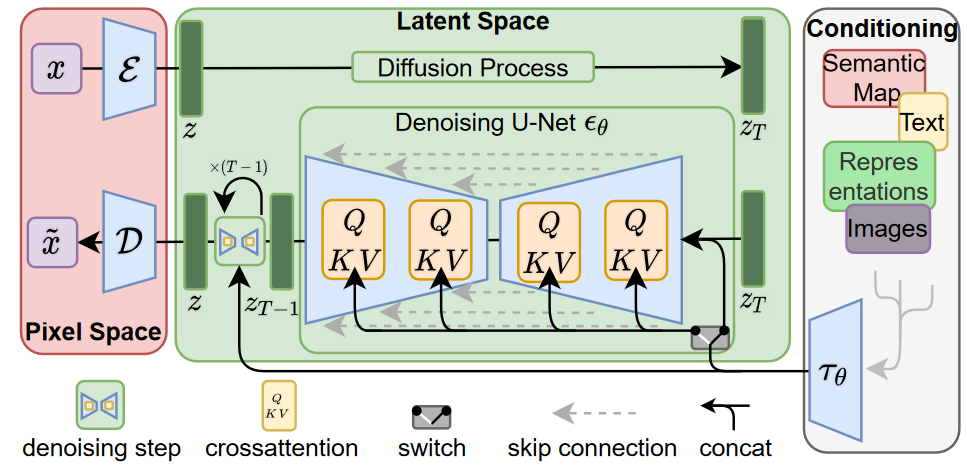
114 KB
readme_imgs/r1.png
0 → 100755
{kind=link}

1.89 MB
readme_imgs/r2.png
0 → 100755
{kind=link}

1.79 MB
readme_imgs/r3.png
0 → 100755
{kind=link}

1.45 MB
requirements.txt
0 → 100755
| fire | ||
| # triton | ||
| pydantic==2.8.2 | ||
| # accelerate==0.27.2 | ||
| # deepspeed==0.8.1 | ||
| huggingface-hub==0.20.2 | ||
| imageio==2.25.1 | ||
| # numpy==1.21.6 | ||
| omegaconf==2.3.0 | ||
| pandas==1.3.5 | ||
| Pillow==9.4.0 | ||
| tokenizers==0.13.2 | ||
| # torch==1.13.1 | ||
| # torchvision==0.14.1 | ||
| transformers==4.26.1 | ||
| # xformers==0.0.16 | ||
| safetensors==0.3.3 | ||
| diffusers==0.28.2 | ||
| sentencepiece==0.1.99 | ||
| gradio==4.37.2 |
{kind=link}

159 KB
{kind=link}

89.9 KB
{kind=link}

134 KB
{kind=link}

156 KB
{kind=link}

156 KB
{kind=link}

138 KB
{kind=link}

97 KB
scripts/sample.py
0 → 100755