
Initial commit
Showing
Dockerfile
0 → 100644
Kimi_VL_inference.py
0 → 100644
Pic/arch.png
0 → 100644
{kind=link}
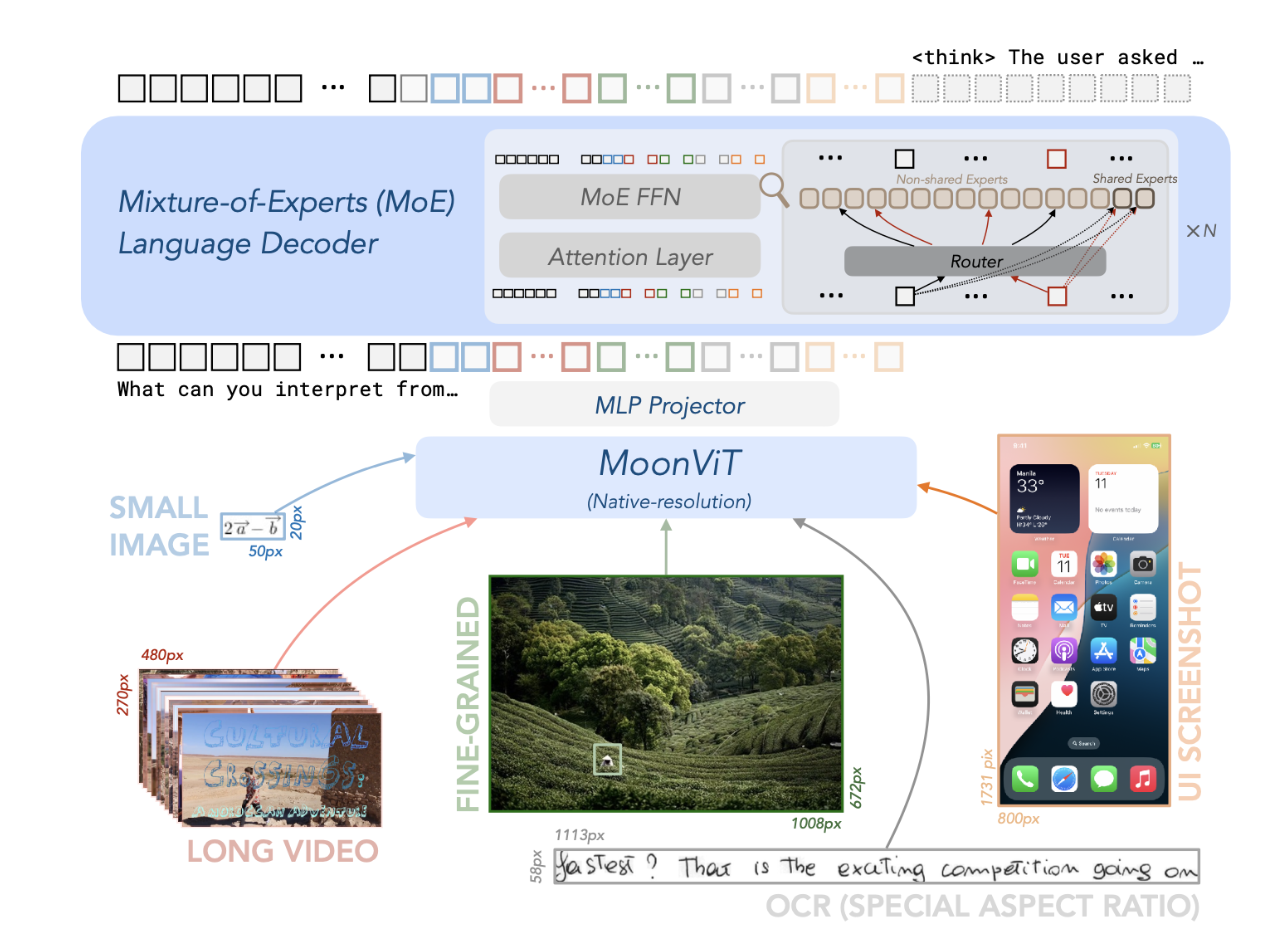
612 KB
Pic/result.png
0 → 100644
{kind=link}

27.8 KB
Pic/theory.png
0 → 100644
{kind=link}
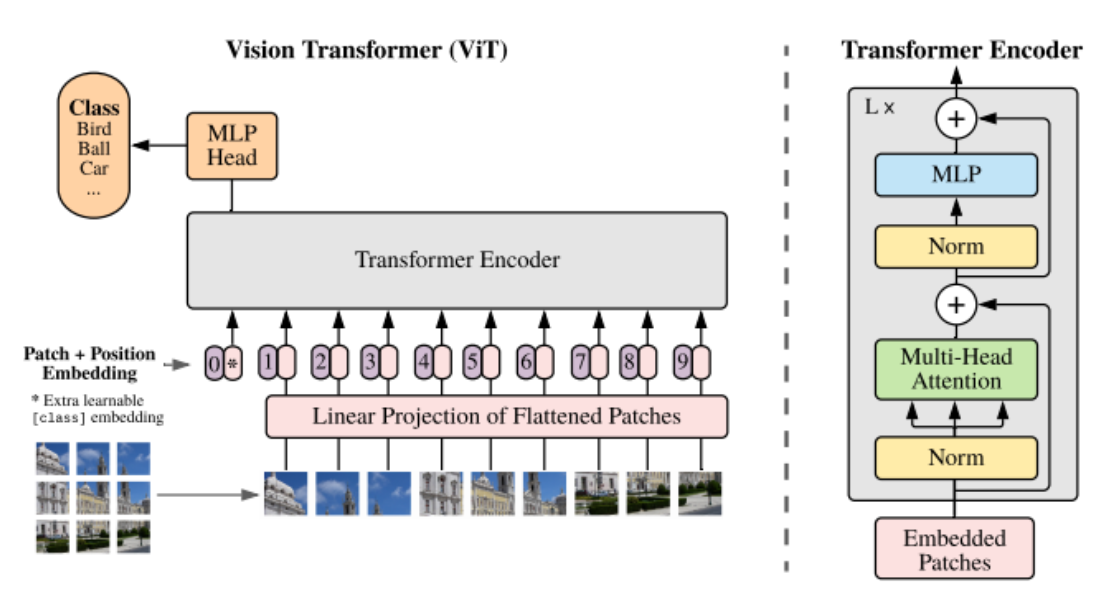
228 KB
README.md
0 → 100644
finetune.sh
0 → 100644
icon.png
0 → 100644
{kind=link}
53.8 KB
model.properties
0 → 100644
requirements.txt
0 → 100644