
v1.0
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
data_provider/__init__.py
0 → 100644
data_provider/data_loader.py
0 → 100644
dataset/ETT-small/ETTm2.csv
0 → 100644
This diff is collapsed.
doc/iTransformer.png
0 → 100644
{kind=link}
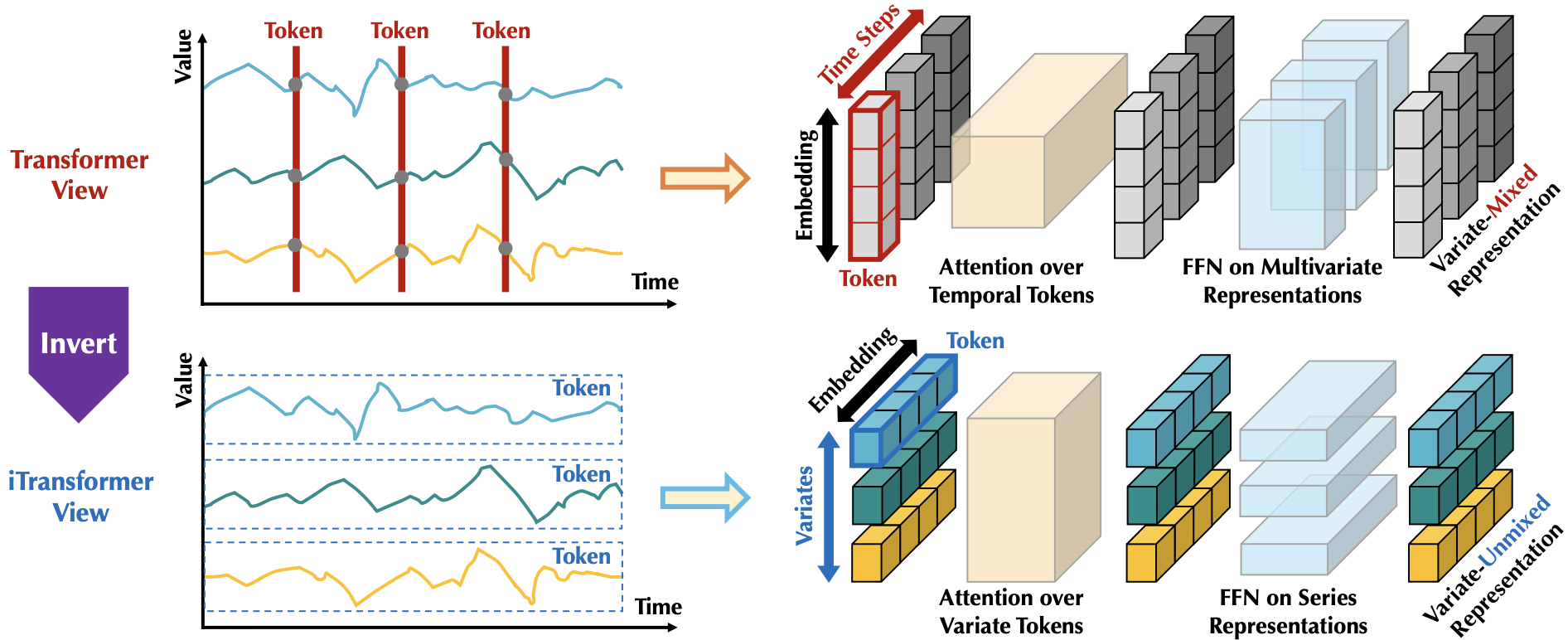
232 KB
doc/transformer.png
0 → 100644
{kind=link}
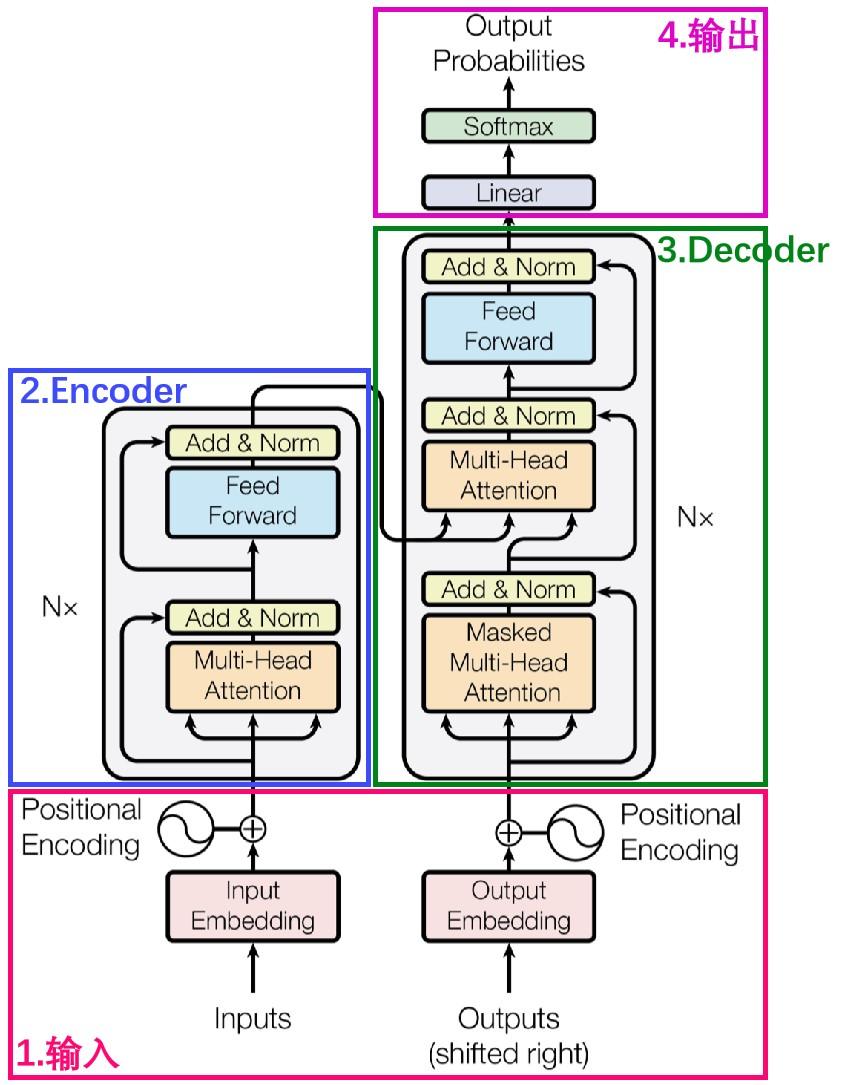
366 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
docker_start.sh
0 → 100644
experiments/exp_basic.py
0 → 100644
figures/ablations.png
0 → 100644
{kind=link}
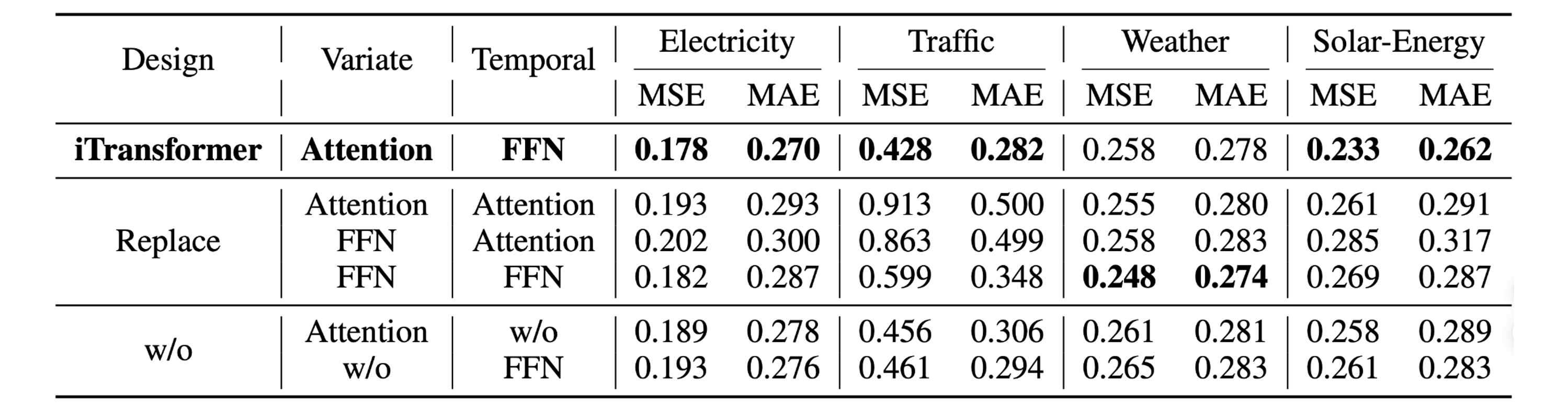
466 KB
figures/algorithm.png
0 → 100644
{kind=link}

302 KB
figures/analysis.png
0 → 100644
{kind=link}
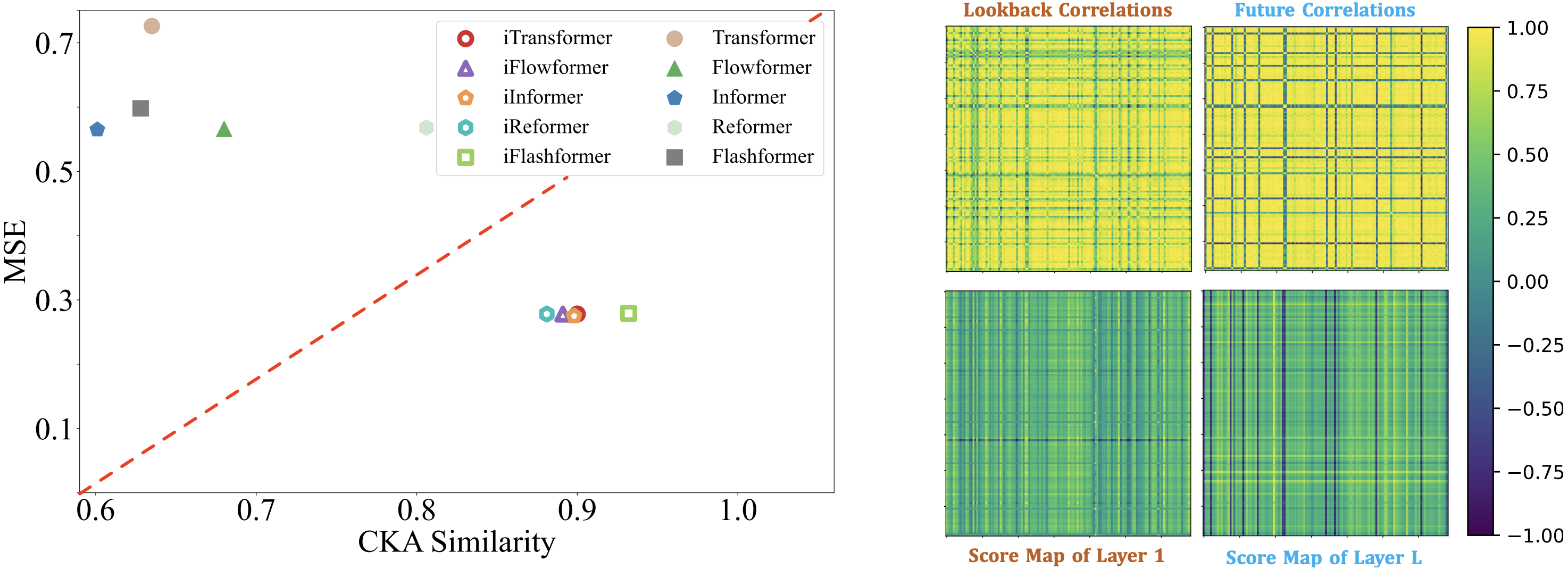
1.3 MB
figures/architecture.png
0 → 100644
{kind=link}
369 KB