
Initial commit
Showing
Dockerfile
0 → 100644
Pic/arch.png
0 → 100644
{kind=link}
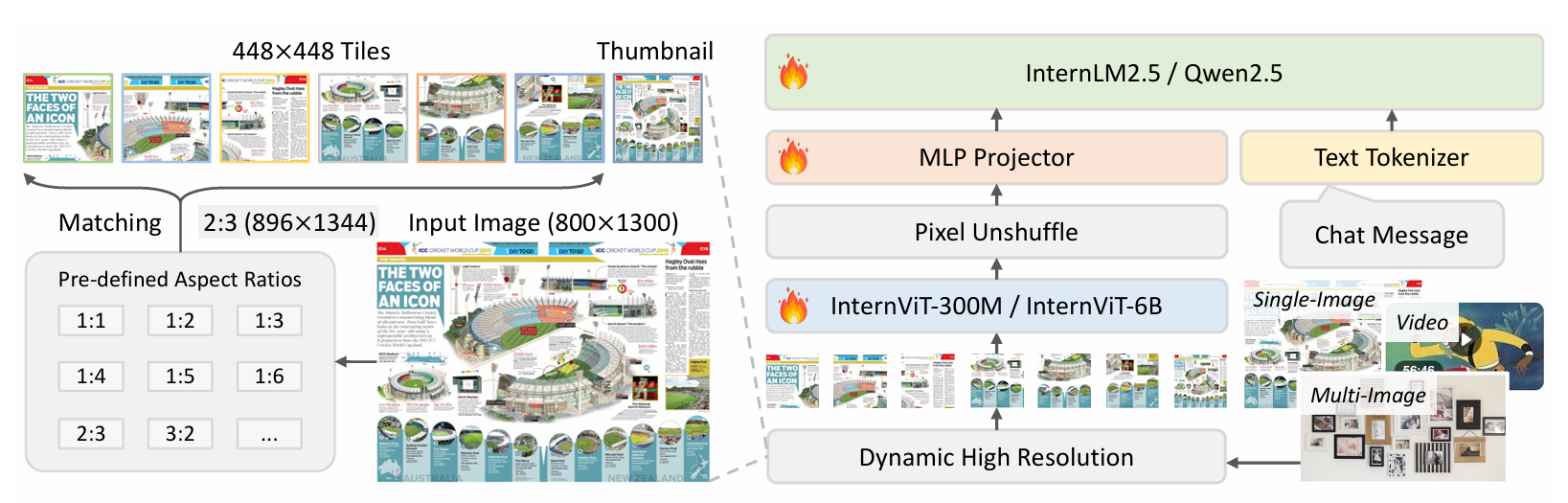
612 KB
Pic/result.png
0 → 100644
{kind=link}
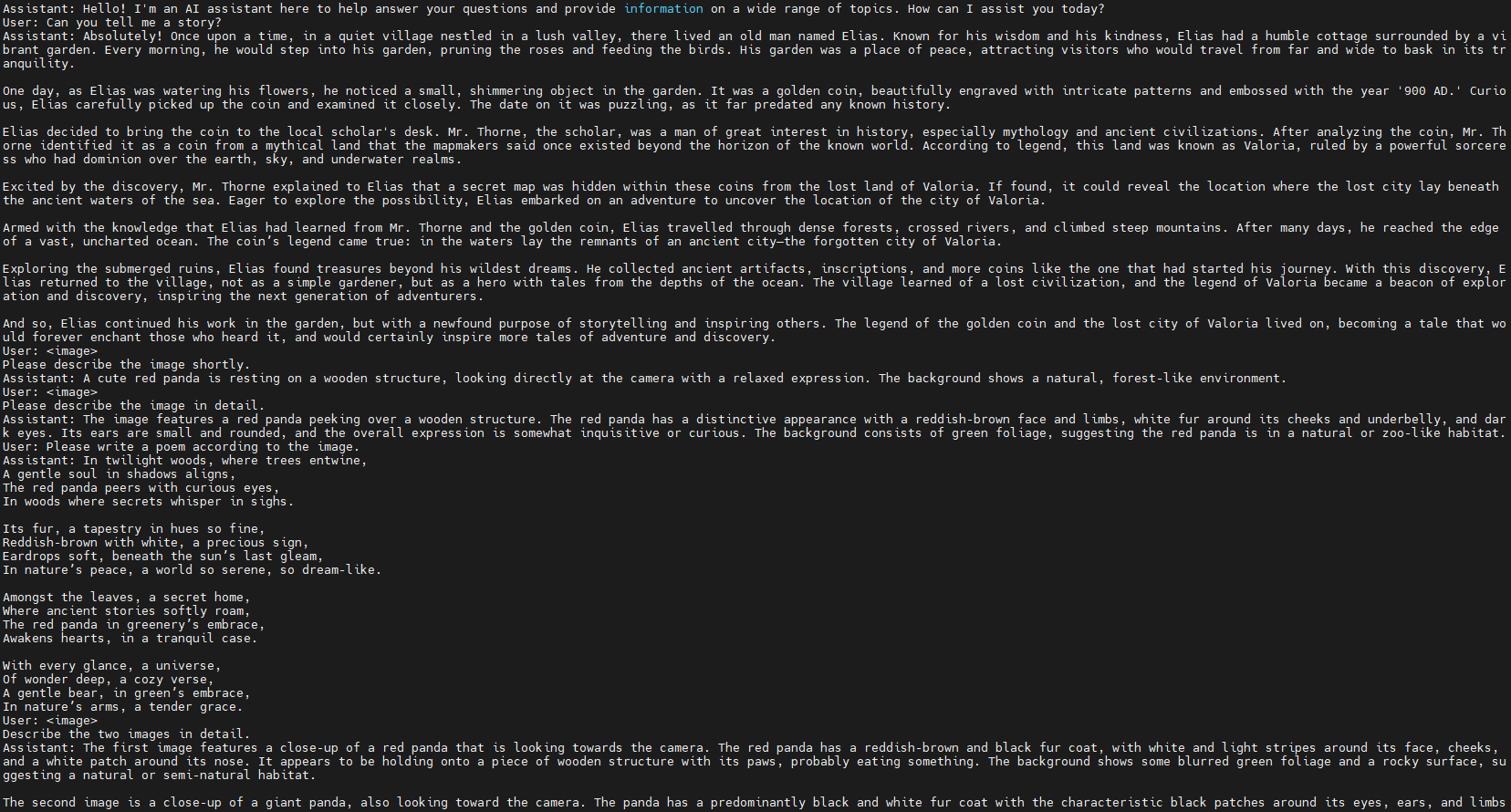
120 KB
Pic/theory.png
0 → 100644
{kind=link}
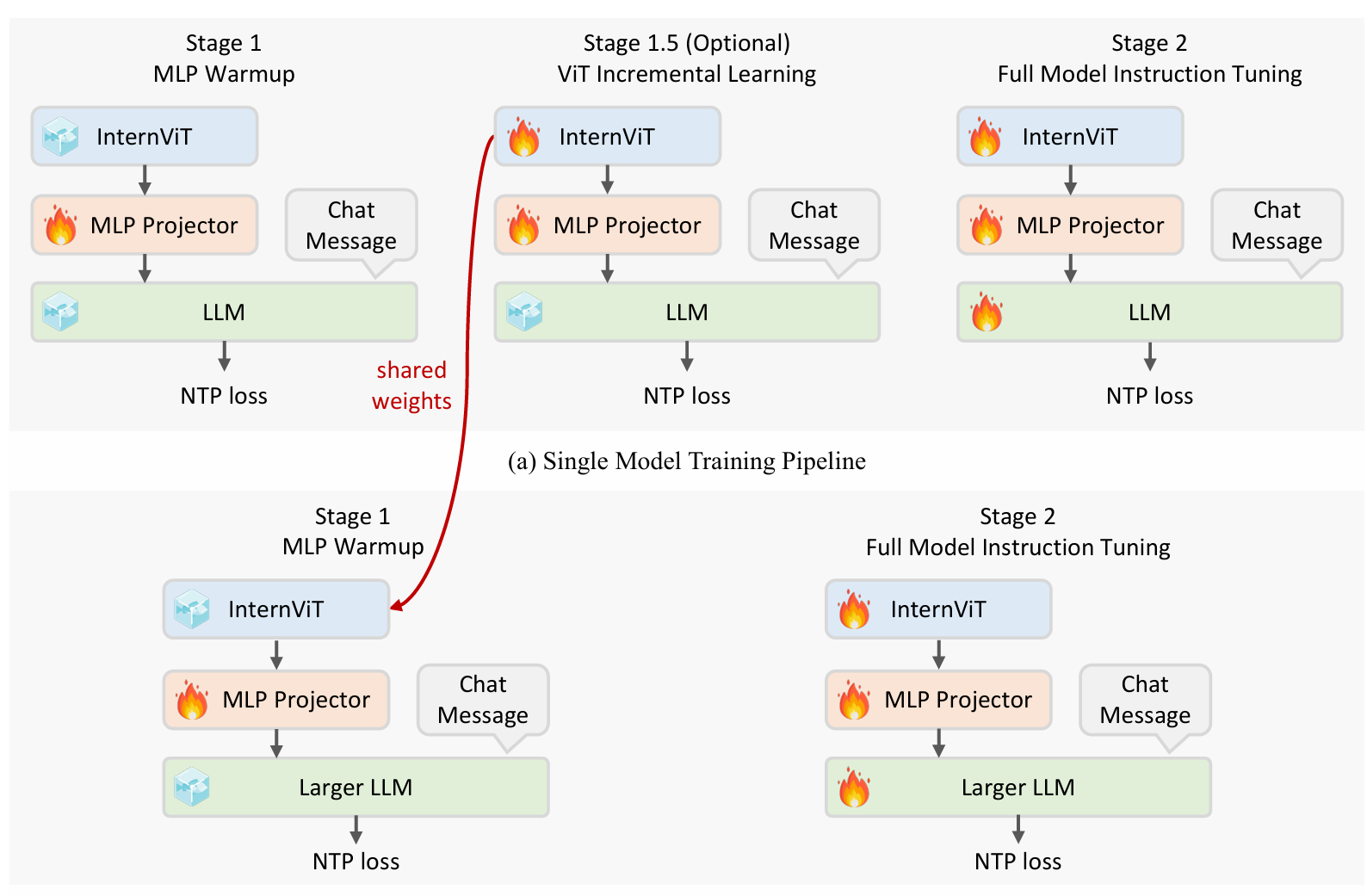
158 KB
README.md
0 → 100644
icon.png
0 → 100644
{kind=link}
53.8 KB
internvl_inference.py
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| transformers>=4.37.2 | |||
| decord | |||
| timm |