
Update Dockerfile, README.md, data/alpaca_2000.parquet, doc/2403.17297v1.pdf,...
Update Dockerfile, README.md, data/alpaca_2000.parquet, doc/2403.17297v1.pdf, doc/eval1.png, doc/eval2.png, doc/res.png, doc/struct.png, inference/start.py, icon.png files
Showing
Dockerfile
0 → 100644
README.md
0 → 100644
data/alpaca_2000.parquet
0 → 100644
File added
doc/2403.17297v1.pdf
0 → 100644
File added
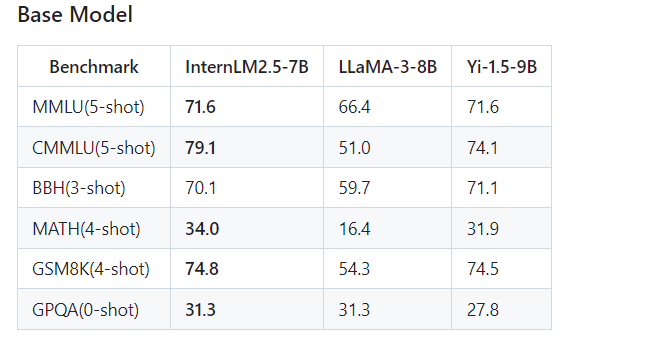
doc/eval1.png
0 → 100644
{kind=link}
24.3 KB
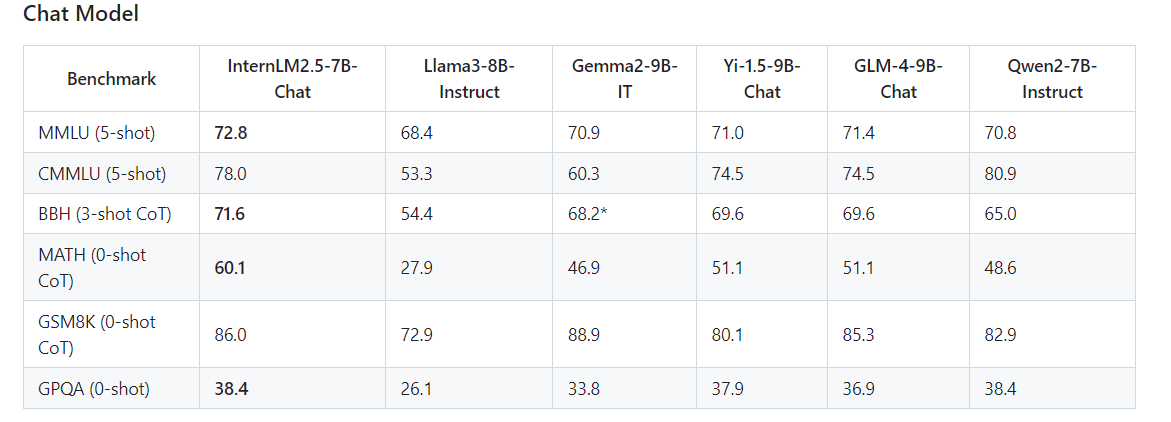
doc/eval2.png
0 → 100644
{kind=link}
39.9 KB
doc/res.png
0 → 100644
{kind=link}

105 KB
doc/struct.png
0 → 100644
{kind=link}

101 KB
icon.png
0 → 100644
{kind=link}
53.8 KB
inference/start.py
0 → 100644