
update codes
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_ori.md
0 → 100644
asserts/MLP.png
0 → 100644
{kind=link}

692 KB
asserts/light_mixture.png
0 → 100644
{kind=link}
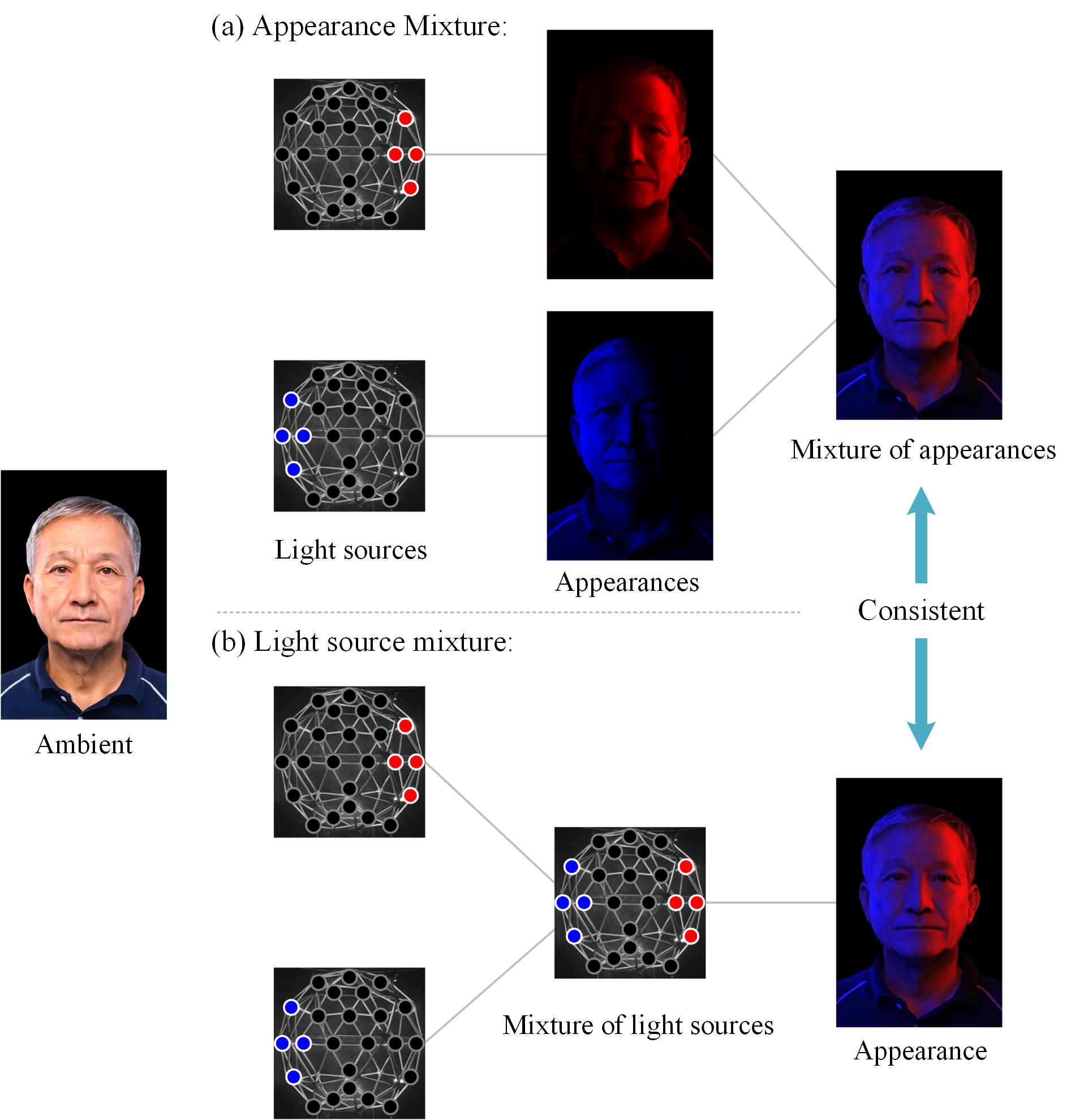
1.5 MB
asserts/result.png
0 → 100644
{kind=link}
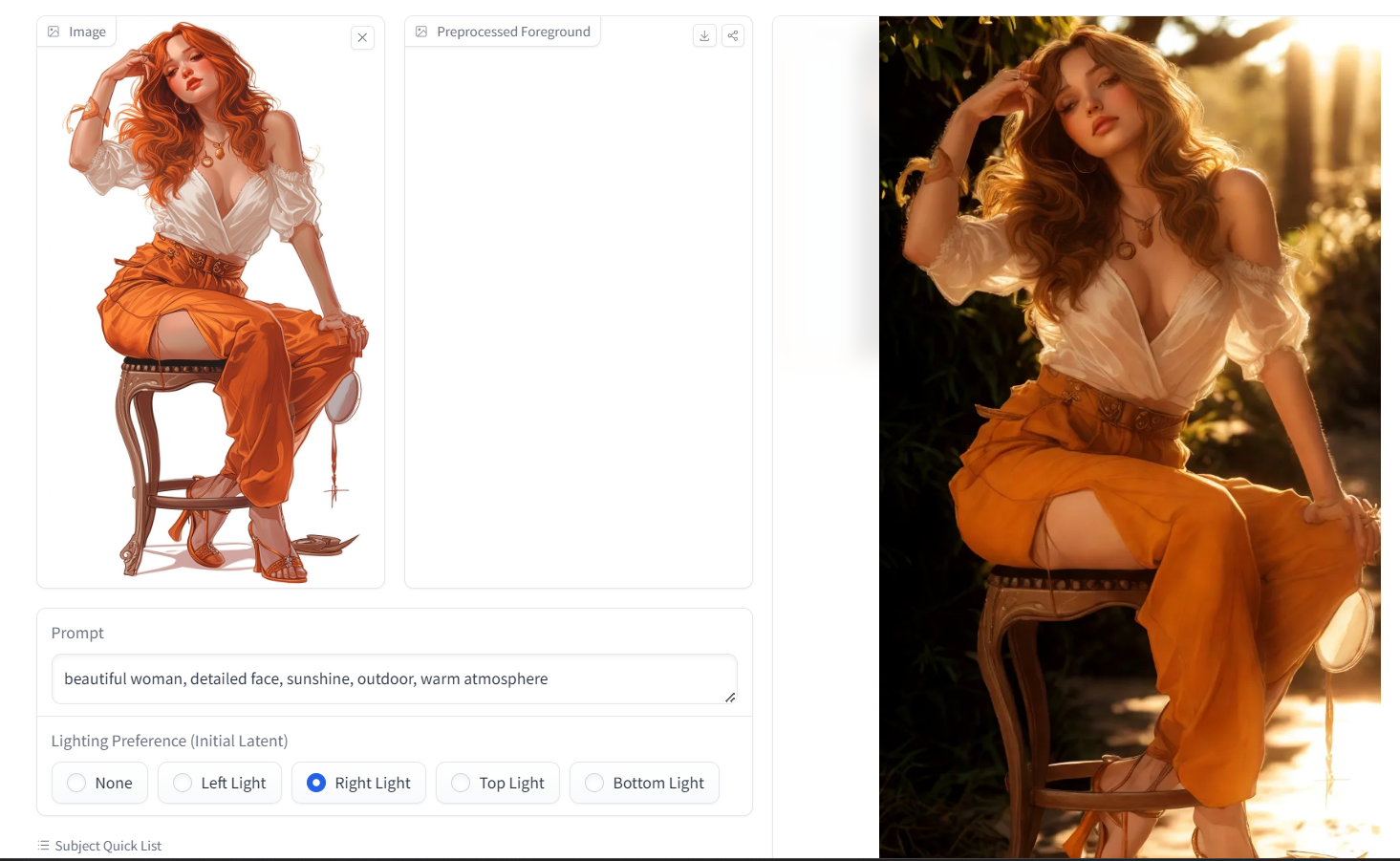
1.26 MB
briarmbg.py
0 → 100644
db_examples.py
0 → 100644
gradio_demo.py
0 → 100644
gradio_demo_bg.py
0 → 100644
imgs/alter/i1.jpeg
0 → 100644
{kind=link}

134 KB
imgs/alter/i2.png
0 → 100644
{kind=link}

2.35 MB
imgs/alter/i3.png
0 → 100644
{kind=link}

1.29 MB
imgs/alter/i4.png
0 → 100644
{kind=link}

1.46 MB
imgs/alter/i5.png
0 → 100644
{kind=link}

3.75 MB
imgs/alter/i6.webp
0 → 100644
{kind=link}

400 KB
imgs/alter/o1.png
0 → 100644
{kind=link}

1.27 MB
imgs/alter/o2.png
0 → 100644
{kind=link}

1.22 MB
imgs/alter/o3.png
0 → 100644
{kind=link}

1.15 MB