
"Initial commit"
Showing
Hunyuan-OCR-master/utils.py
0 → 100644
File added
License.txt
0 → 100644
README.md
0 → 100644
README_ori.md
0 → 100644
README_zh.md
0 → 100644
assets/guwan1.png
0 → 100644
{kind=link}

454 KB
assets/hunyuan_logo.png
0 → 100644
{kind=link}
84.9 KB
assets/hyocr-head-img.png
0 → 100644
{kind=link}
634 KB
assets/hyocr-pipeline-v1.png
0 → 100644
{kind=link}

2.68 MB
assets/ie_parallel.jpg
0 → 100644
{kind=link}

122 KB
assets/parsing_chart1.png
0 → 100644
{kind=link}
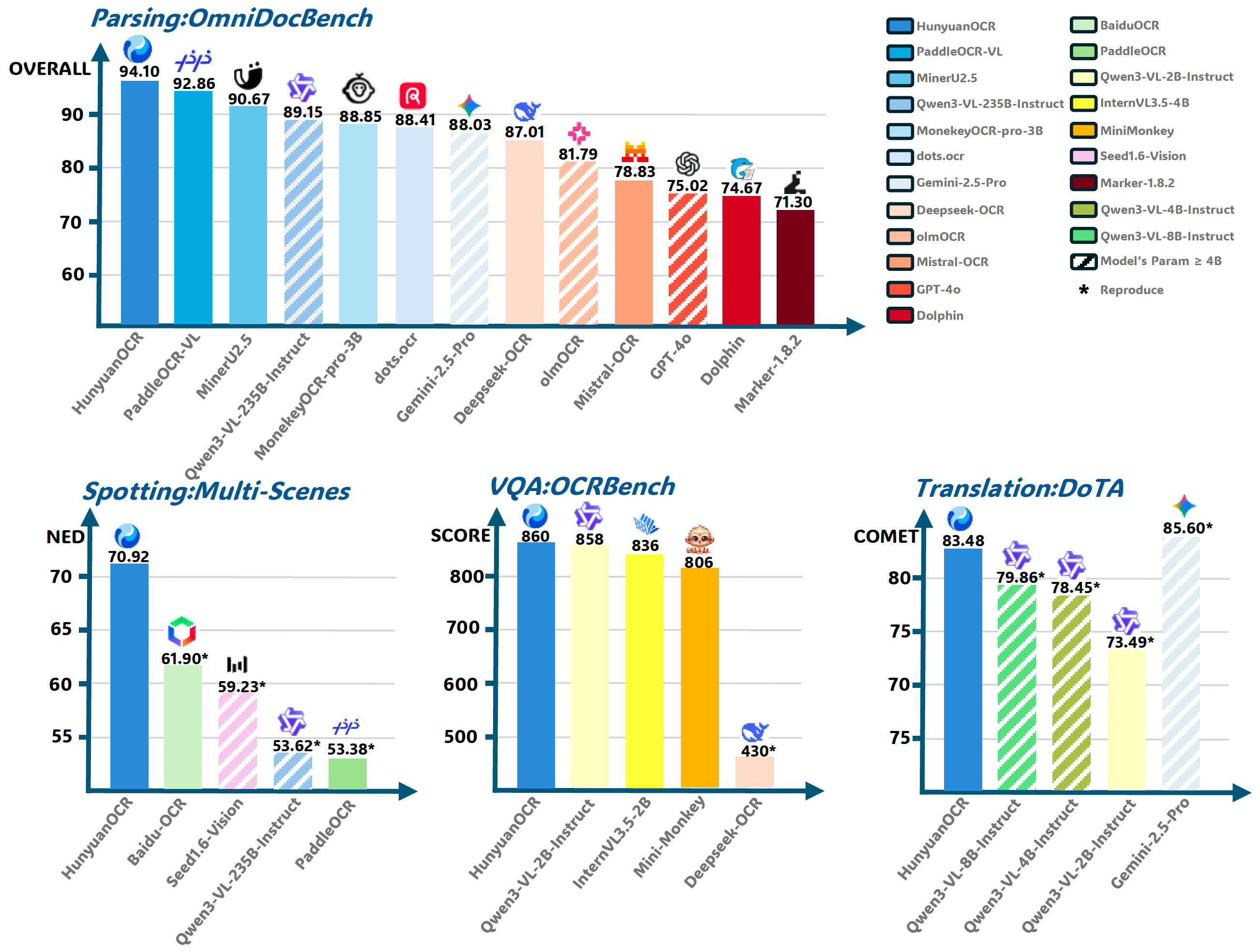
576 KB
assets/parsing_rgsj.png
0 → 100644
{kind=link}

1020 KB
assets/parsing_rgsjz_2.png
0 → 100644
{kind=link}

126 KB
assets/qikai1.png
0 → 100644
{kind=link}

520 KB
{kind=link}

106 KB
assets/result.png
0 → 100644
{kind=link}

31.7 KB