
first commit
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
VERSION
0 → 100644
cog.yaml
0 → 100644
doc/Visual_Results.png
0 → 100644
{kind=link}

8.98 MB
doc/method.png
0 → 100644
{kind=link}
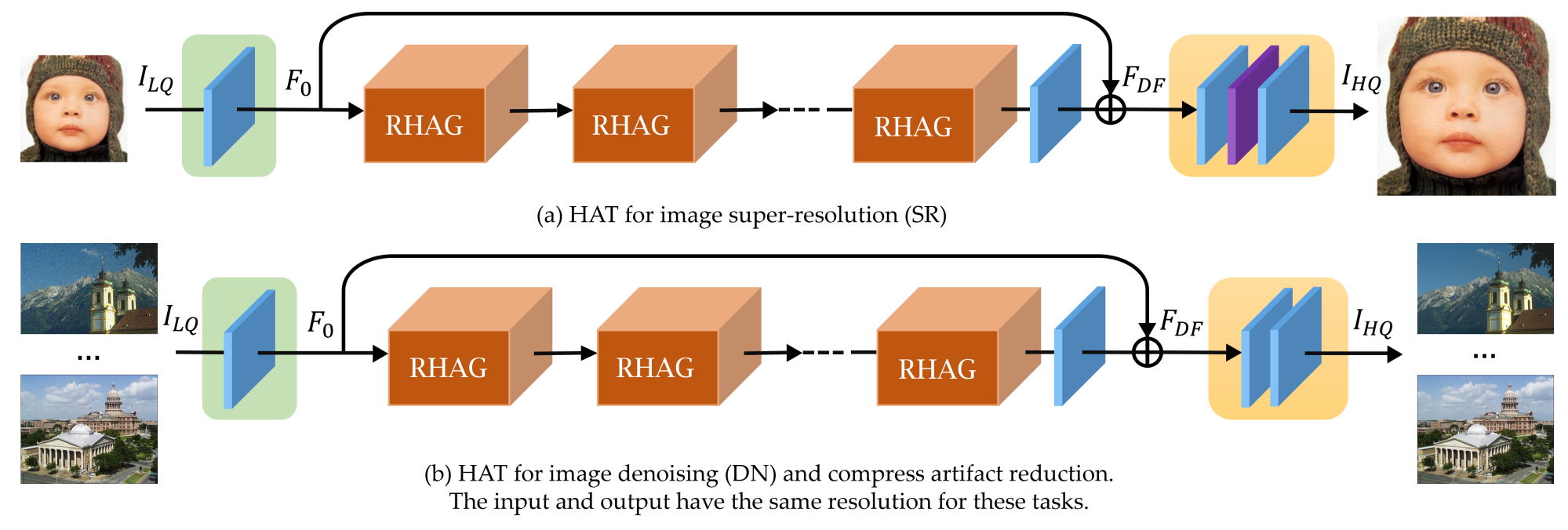
496 KB
doc/model.png
0 → 100644
{kind=link}
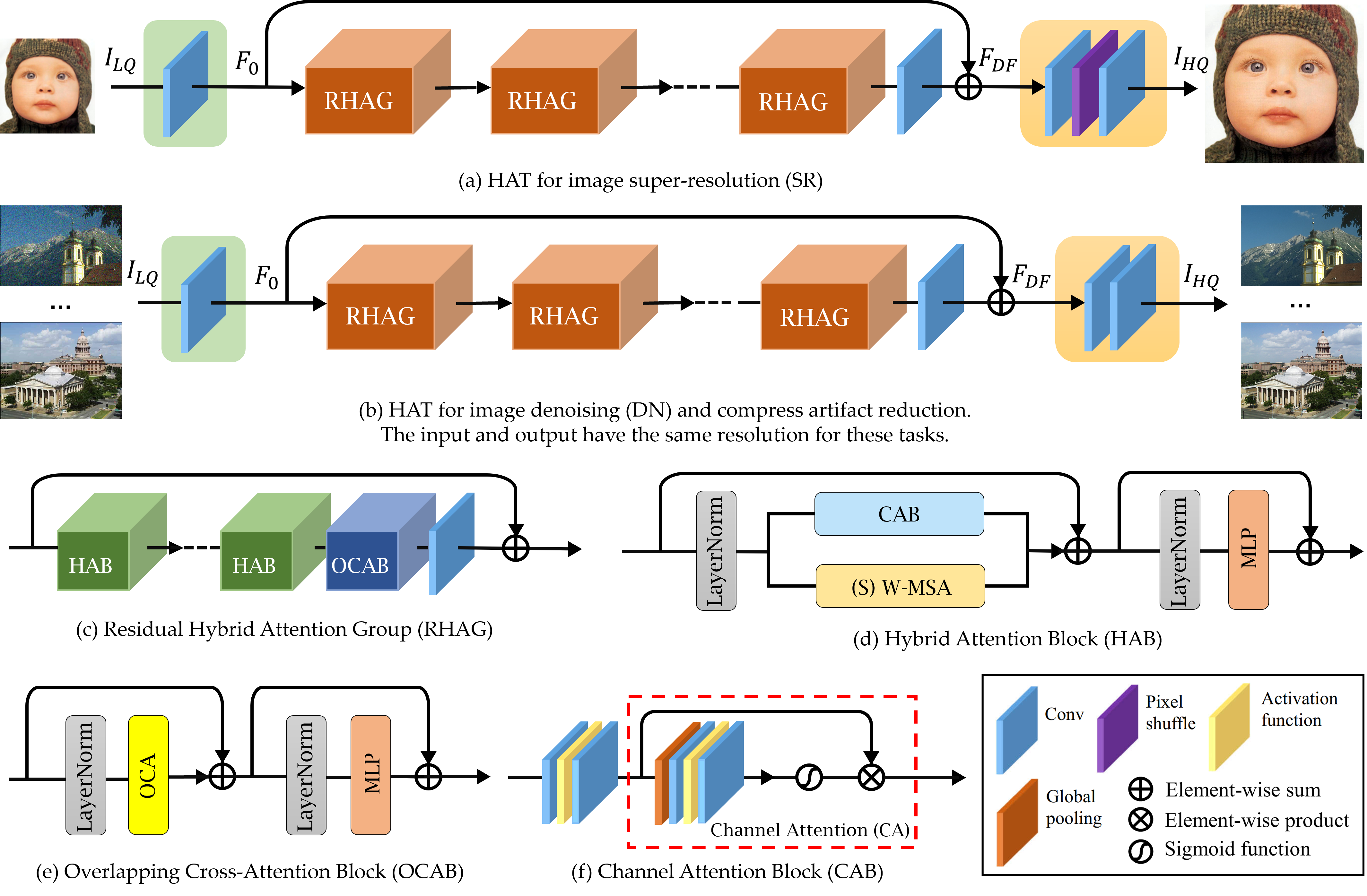
1.94 MB
docker/Dockerfile
0 → 100644
extract_subimages.py
0 → 100644
figures/Comparison.png
0 → 100644
{kind=link}
This image diff could not be displayed because it is too large. You can view the blob instead.
{kind=link}
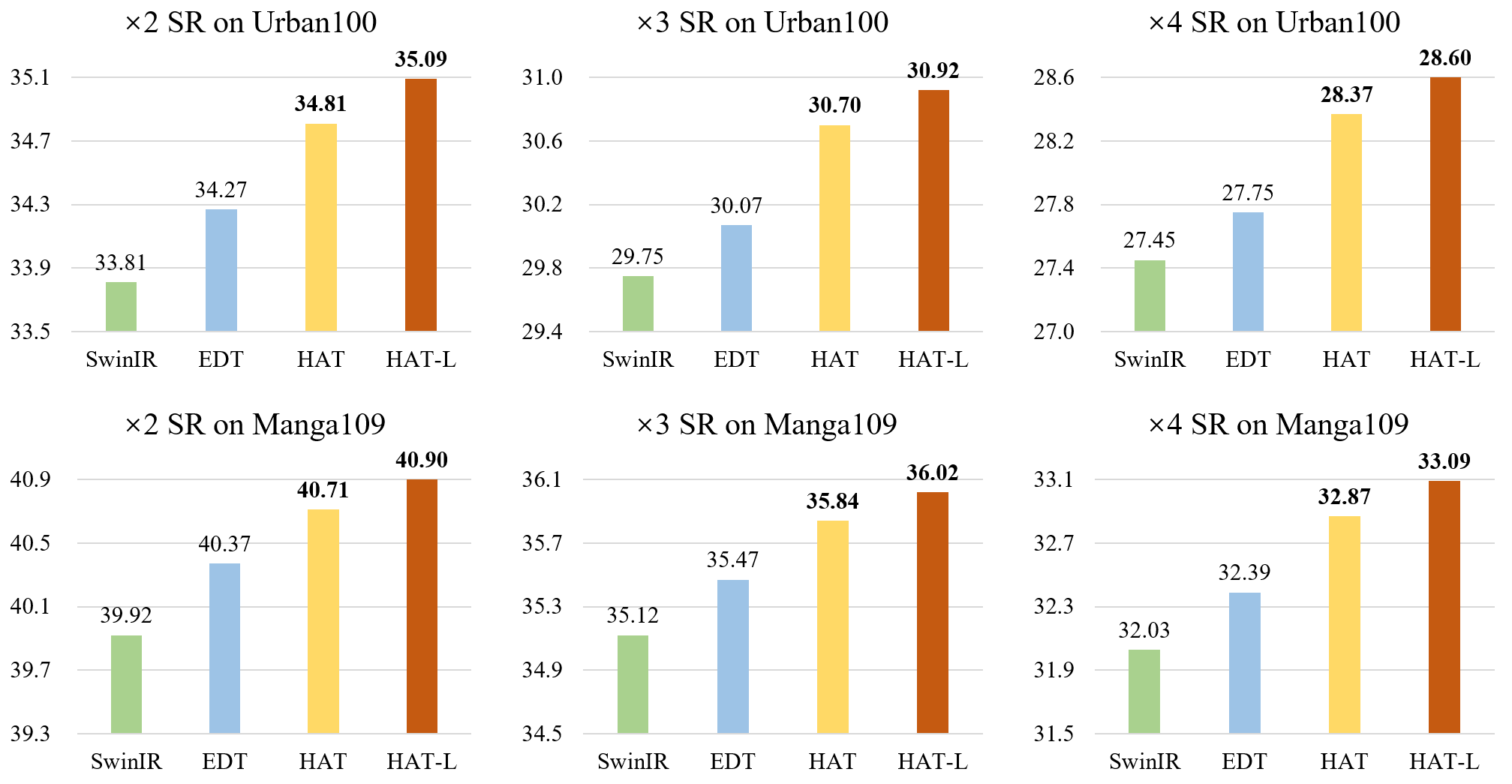
63.2 KB
figures/Visual_Results.png
0 → 100644
{kind=link}

8.98 MB
generate_meta_info.py
0 → 100644
hat/__init__.py
0 → 100644
hat/archs/__init__.py
0 → 100644
hat/archs/hat_arch.py
0 → 100644
This diff is collapsed.
hat/archs/srvgg_arch.py
0 → 100644
hat/data/__init__.py
0 → 100644