
add grop ande change to 24.04
Showing
.gitignore
0 → 100644
CODE_OF_CONDUCT.md
0 → 100644
Contributors.md
0 → 100644
LICENSE.txt
0 → 100644
README.md
0 → 100644
README_ori.md
0 → 100644
checkpoint.py
0 → 100644
checkpoints/README.md
0 → 100644
debug.log
0 → 100644
doc/MoE.png
0 → 100644
{kind=link}
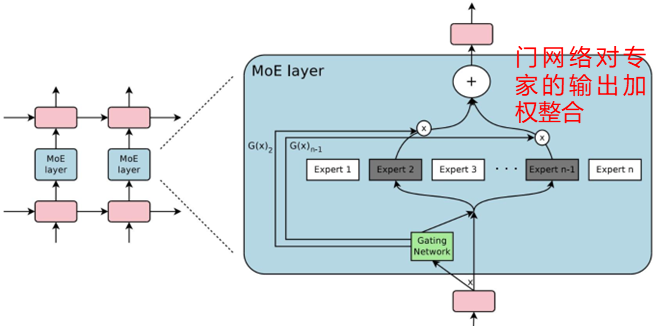
69.1 KB
doc/end.png
0 → 100644
{kind=link}
11.2 KB
doc/vram.png
0 → 100644
{kind=link}
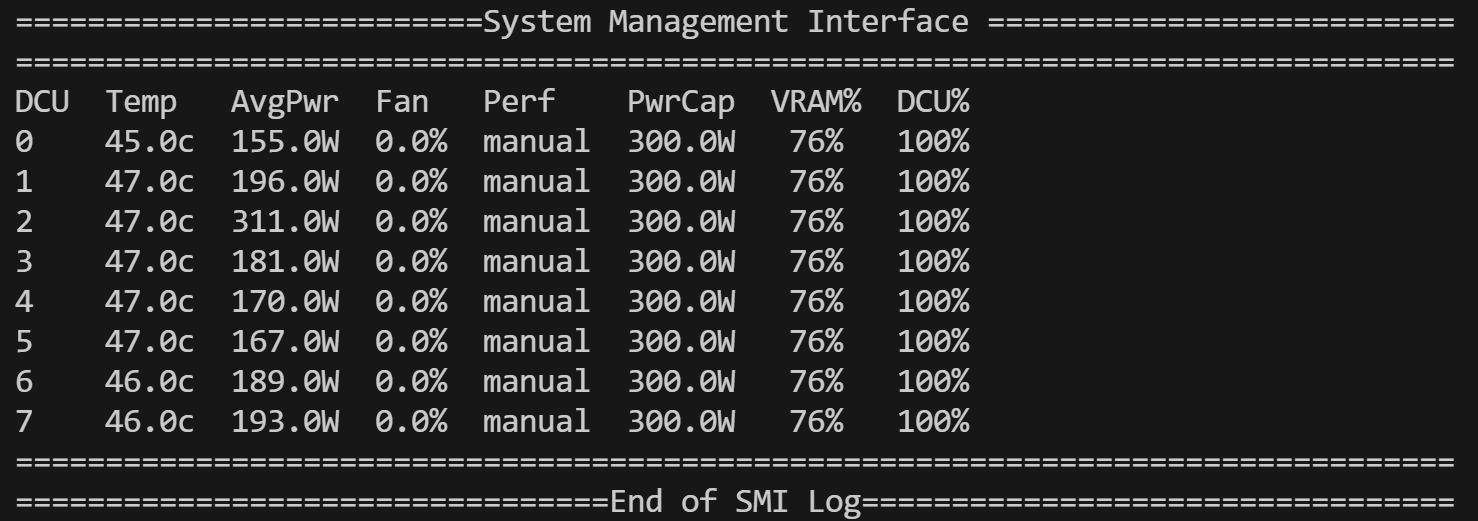
63.9 KB
docker/Dockerfile
0 → 100644
log.txt
0 → 100644
model.properties
0 → 100644
model.py
0 → 100644
pyproject.toml
0 → 100644
requirements.txt
0 → 100644
| dm_haiku==0.0.12 | |||
| sentencepiece==0.2.0 |
run.py
0 → 100644
runners.py
0 → 100644