"src/vscode:/vscode.git/clone" did not exist on "74a8deb19f1aa2b2463f5e80e7e46edad343d686"

update
Showing
.gitignore
0 → 100644
.pre-commit-config.yaml
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_zh.md
0 → 100644
asserts/example.png
0 → 100644
{kind=link}
92.9 KB
asserts/image.png
0 → 100644
{kind=link}
158 KB
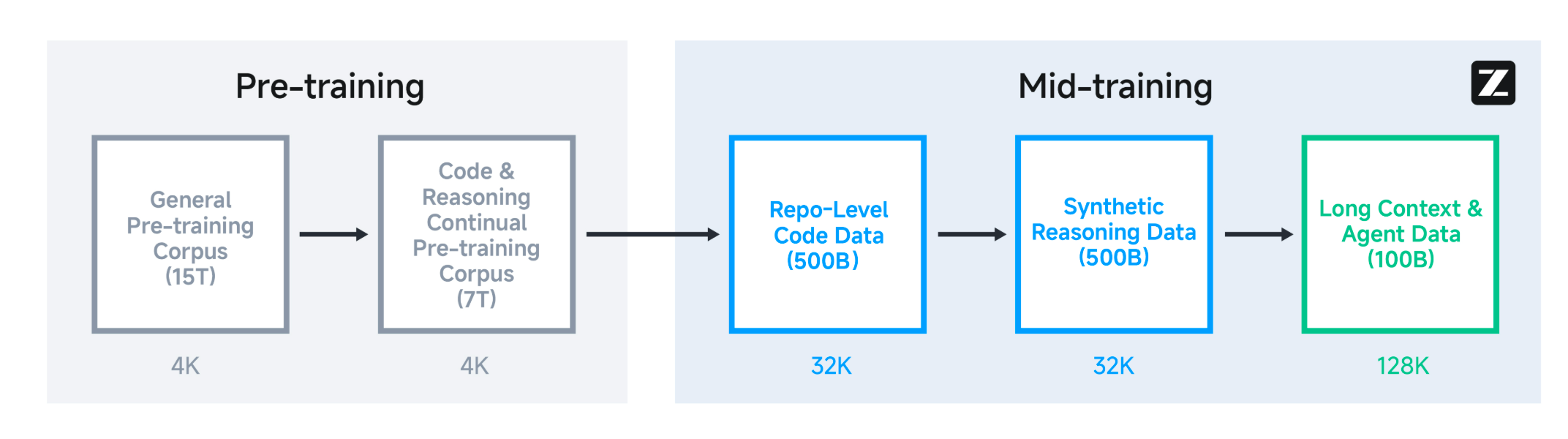
asserts/model.png
0 → 100644
{kind=link}
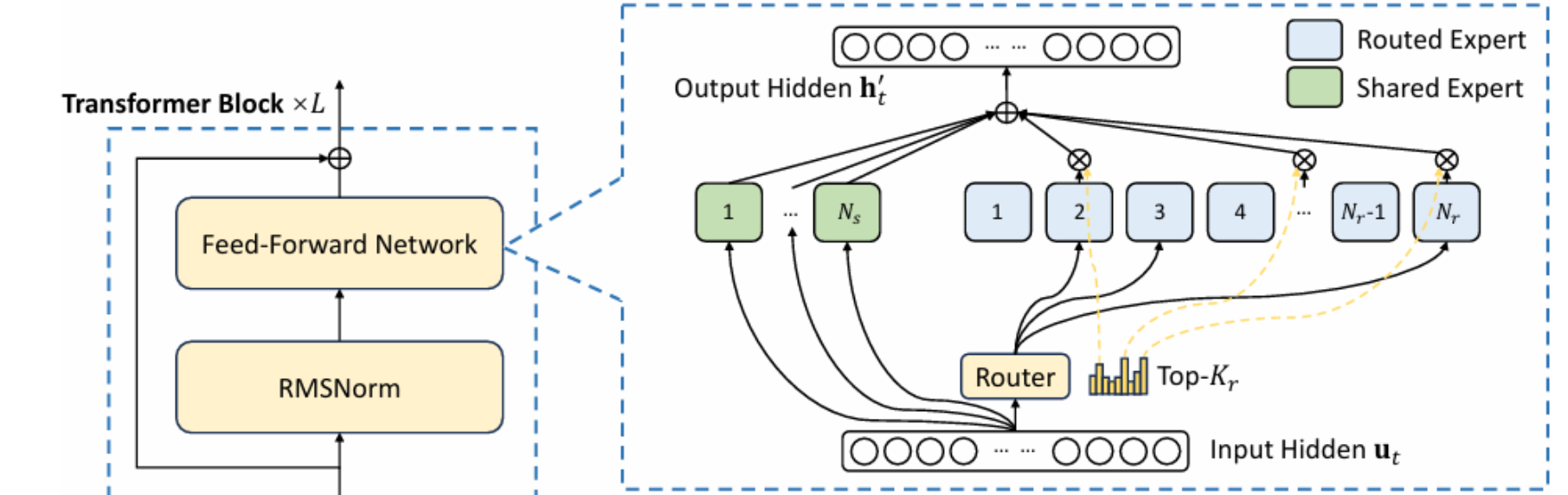
260 KB
asserts/results.png
0 → 100644
{kind=link}
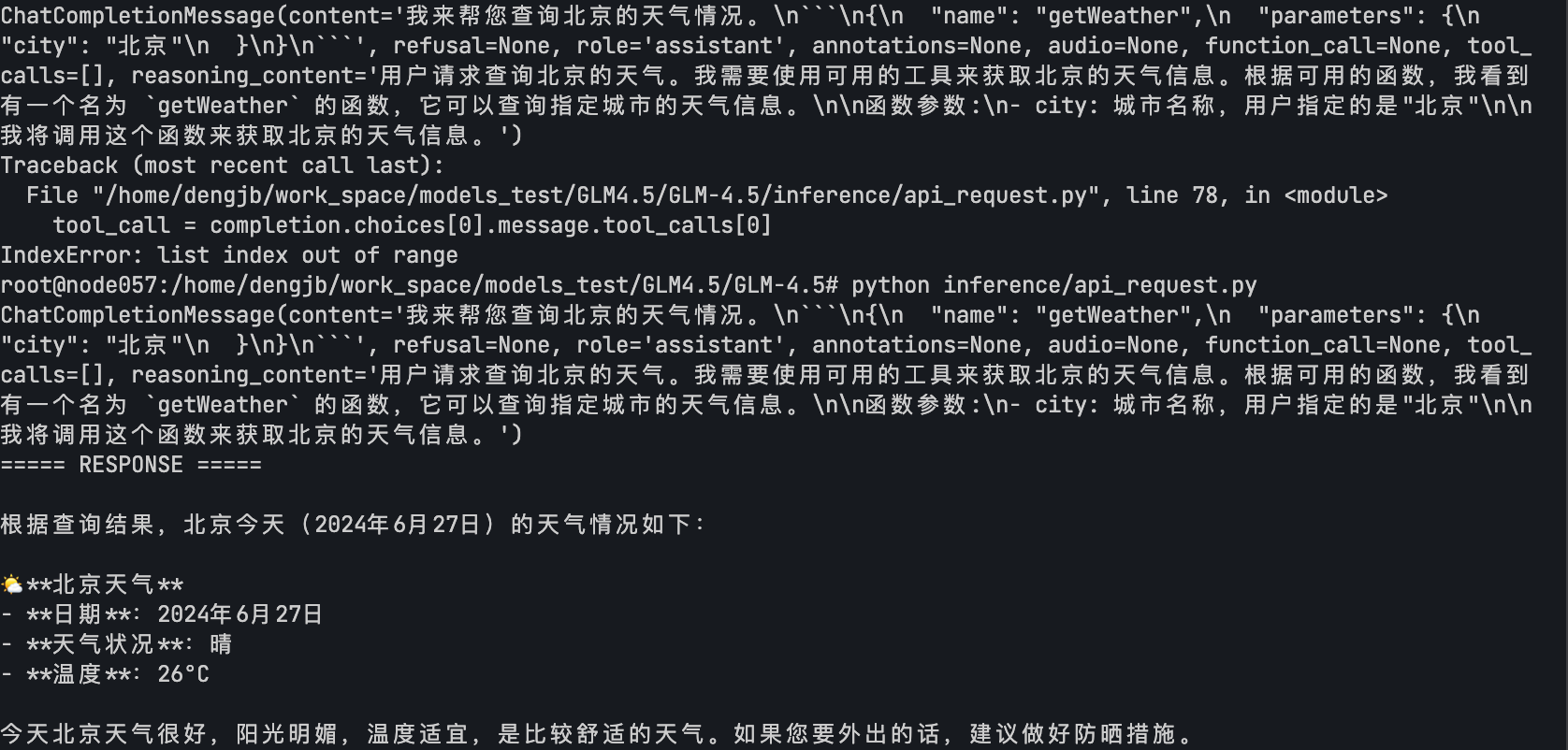
262 KB
claude_code/README.md
0 → 100644
claude_code/README_zh.md
0 → 100644
figures/amd_iommu.png
0 → 100644
{kind=link}
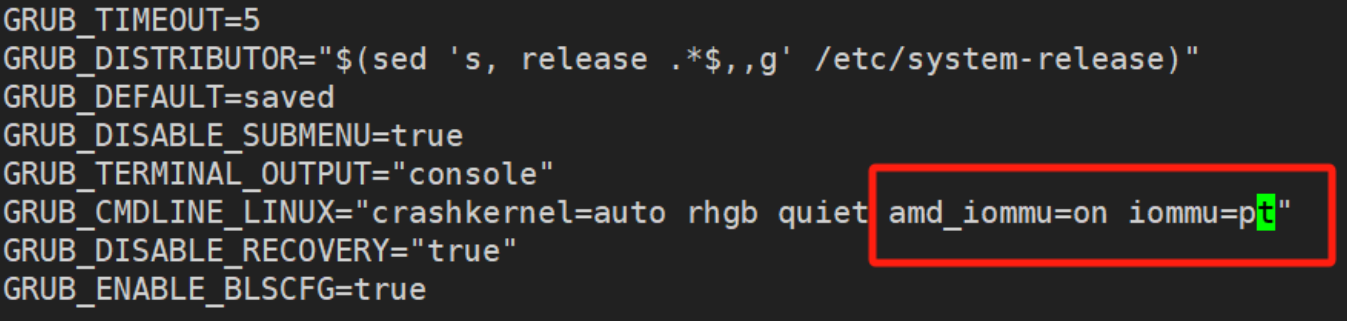
127 KB
figures/bee.jpg
0 → 100644
{kind=link}

5.12 MB
figures/id_rsa.png
0 → 100644
{kind=link}

82.7 KB
figures/ip.png
0 → 100644
{kind=link}
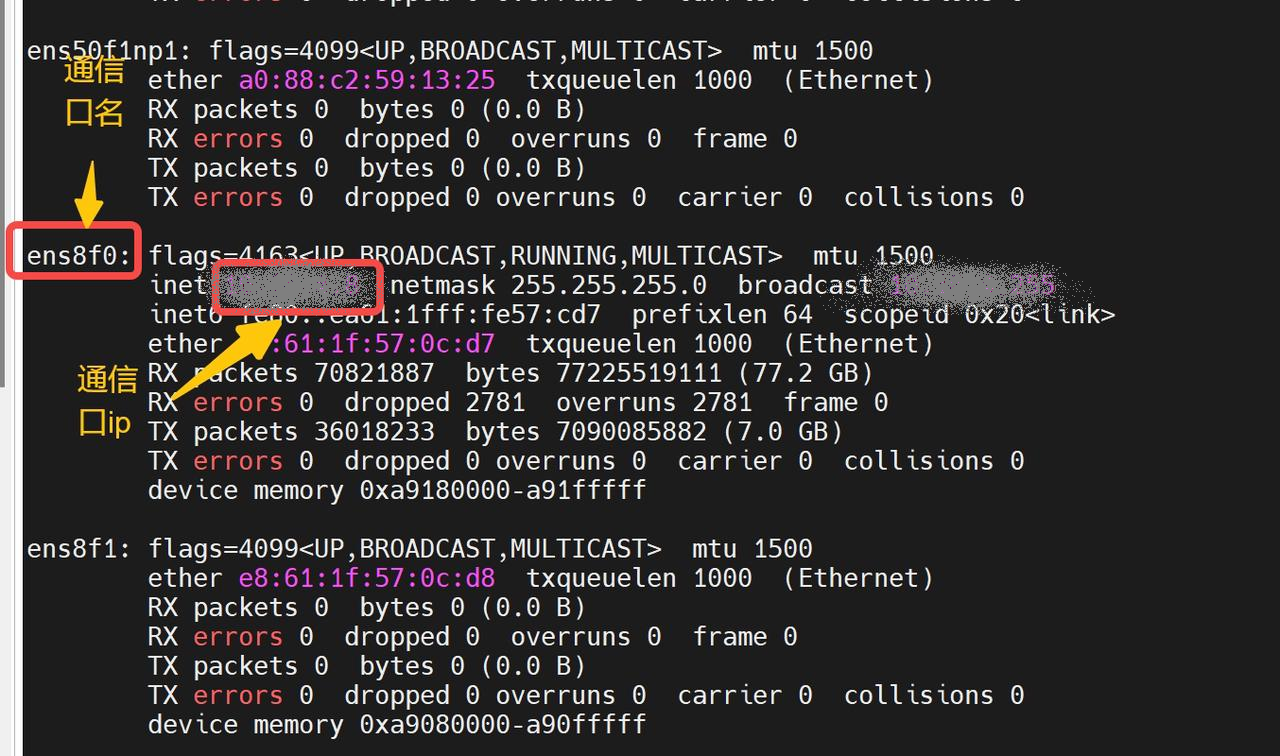
1.06 MB
figures/ip_bw.png
0 → 100644
{kind=link}
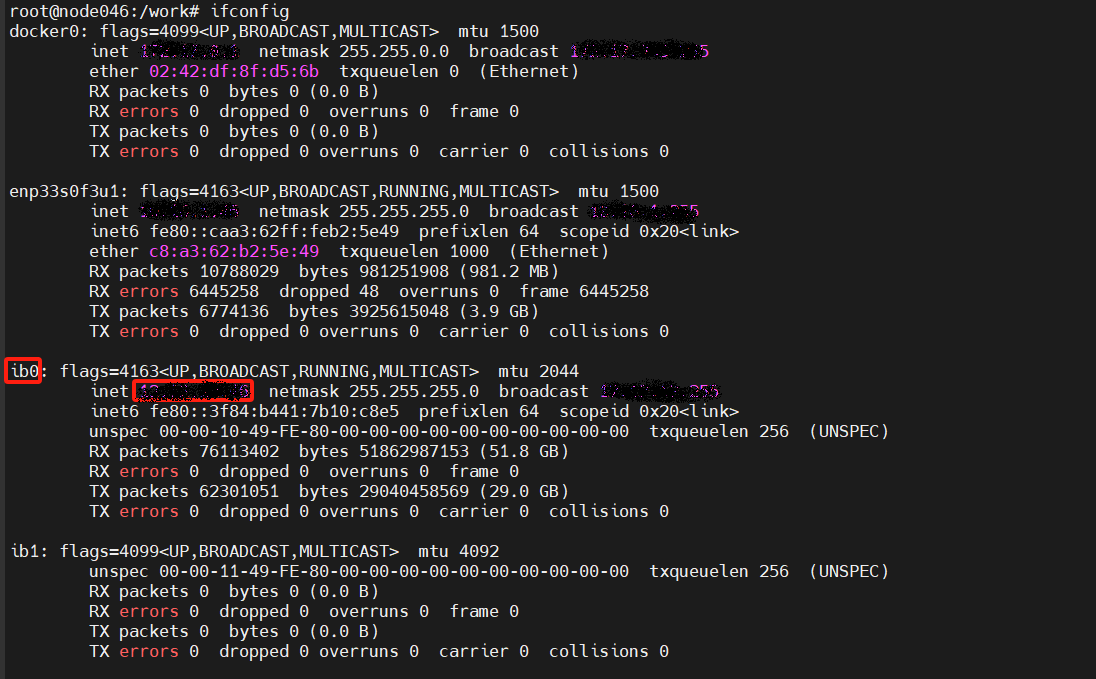
97.1 KB
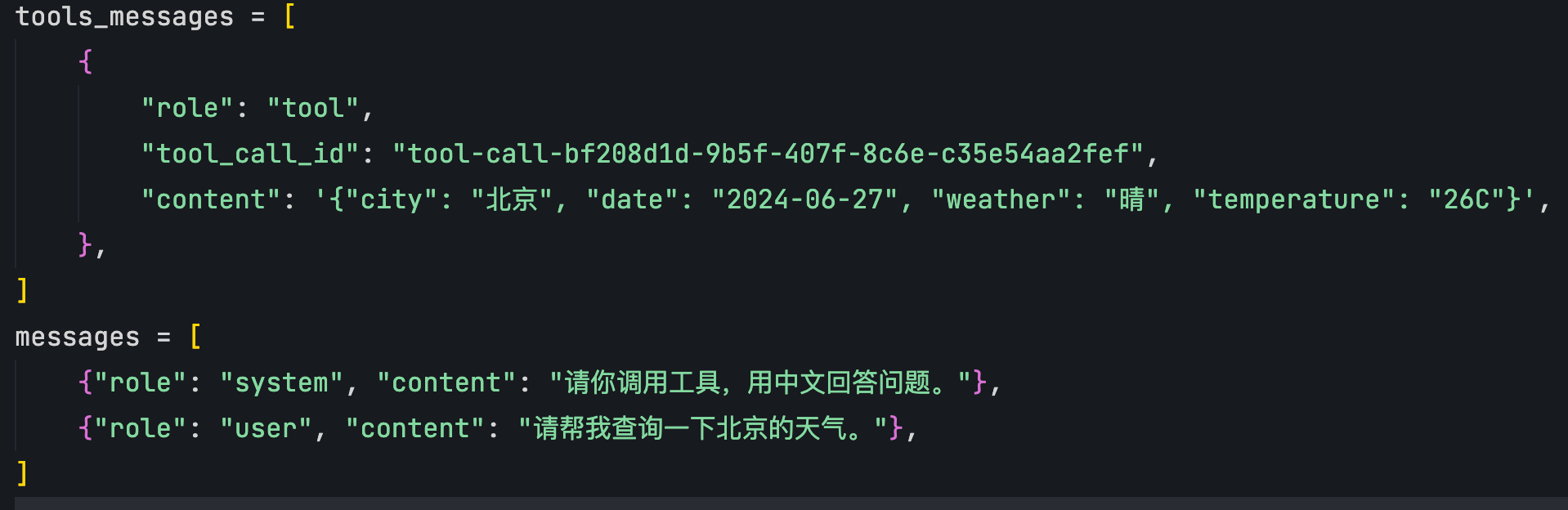
inference/api_request.py
0 → 100644
inference/trans_infer_cli.py
0 → 100644
requirements.txt
0 → 100644
| transformers>=4.54.0 | |||
| pre-commit>=4.2.0 | |||
| accelerate>=1.9.0 | |||
| sglang>=0.4.10.post1 | |||
| git+https://github.com/vllm-project/vllm.git | |||
| # using with pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly to use streaming tool call support | |||
| \ No newline at end of file |