Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
GLM-130B_fastertransformer
Commits
7b7c64c5
Commit
7b7c64c5
authored
Oct 11, 2023
by
zhouxiang
Browse files
更新格式
parent
e15b5446
Changes
4
Hide whitespace changes
Inline
Side-by-side
Showing
4 changed files
with
56 additions
and
9 deletions
+56
-9
README.md
README.md
+52
-7
doc/GLM.png
doc/GLM.png
+0
-0
doc/transformers.jpg
doc/transformers.jpg
+0
-0
model.properties
model.properties
+4
-2
No files found.
README.md
View file @
7b7c64c5
# GLM130B_FT
## 模型介绍
GLM-130B是一个开放的双语(中英)双向密集模型,具有130亿个参数,使用
[
通用语言模型(GLM)
](
https://aclanthology.org/2022.acl-long.26
)
算法进行预训练。
## 论文
本项目主要针对GLM-130B模型在8卡32G显存的DCU平台利用fastertransformer进行快速推理。
`GLM: General Language Model Pretraining with Autoregressive Blank Infilling`
-
[
https://arxiv.org/abs/2103.10360
](
https://arxiv.org/abs/2103.10360
)
## 模型结构
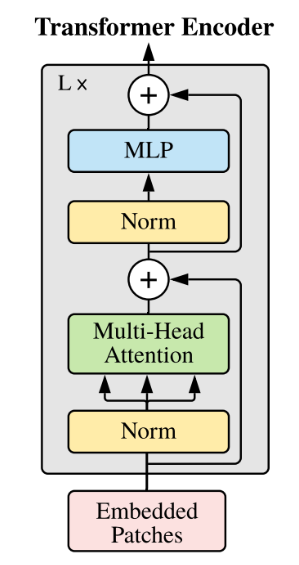
GLM是一个基于transformer的语言模型,利用自回归空白填充作为其训练目标。
GLM-130B是一个开放的双语(中英)双向密集模型,具有130亿个参数,使用
[
通用语言模型(GLM)
](
https://aclanthology.org/2022.acl-long.26
)
算法进行预训练。GLM是一种基于Transformer的语言模型,以自回归空白填充为训练目标。
<div
align=
"center"
>
<img
src=
"doc/transformers.jpg"
width=
"300"
height=
"400"
>
</div>
## 模型推理
以下是GLM130B的主要网络参数配置:
### 下载镜像
| 模型名称 | 隐含层维度 | 层数 | 头数 | 词表大小 | 位置编码 | 最大序列长度 |
| -------- | ---------- | ---- | ---- | -------- | -------- | ------------ |
| GLM130B | 12288 | 70 | 96 | 150528 | RoPE | 2048 |
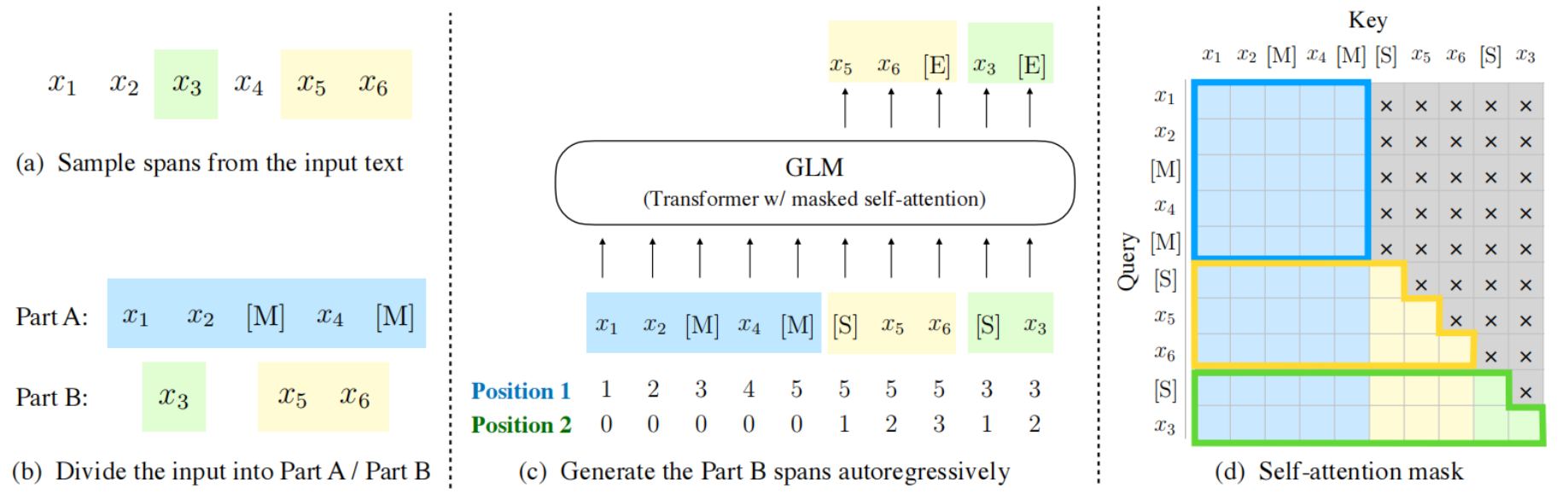
## 算法原理
GLM是一种基于Transformer的语言模型,以自回归空白填充为训练目标, 同时具备自回归和自编码能力。
<div
align=
"center"
>
<img
src=
"doc/GLM.png"
width=
"550"
height=
"200"
>
</div>
本项目主要针对GLM-130B模型在8卡32G显存的DCU平台利用fastertransformer进行快速推理。
## 环境配置
### 环境准备
在光源可拉取推理的docker镜像,拉取方式如下:
...
...
@@ -19,6 +44,16 @@ GLM是一个基于transformer的语言模型,利用自回归空白填充作为
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:glm-ft-v1.0
```
### 容器启动
模型推理容器启动命令参考如下,用户根据需要修改:
```
# <container_name> 自定义容器名
# <project_path> 当前工程所在路径
docker run -it --name=<container_name> -v <project_path>:/work -w /work --device=/dev/kfd --device=/dev/dri --security-opt seccomp=unconfined --cap-add=SYS_PTRACE --shm-size=16G --group-add 39 image.sourcefind.cn:5000/dcu/admin/base/custom:glm-ft-v1.0 /bin/bash
```
### 编译方法
```
...
...
@@ -33,7 +68,9 @@ nvcc CMakeFiles/test_logprob_kernels.dir/test_logprob_kernels.cu.o -o ../../bin/
```
### 模型下载
## 推理
### 原版模型下载与转换
从
[
这里
](
https://docs.google.com/forms/d/e/1FAIpQLSehr5Dh_i3TwACmFFi8QEgIVNYGmSPwV0GueIcsUev0NEfUug/viewform?usp=sf_link
)
下载GLM-130B的模型,确保所有60个块都已完全下载,然后使用以下命令将它们合并到单个存档文件中并解压缩它:
...
...
@@ -71,7 +108,15 @@ mpirun -n 8 --allow-run-as-root ./bin/glm_example
python ../examples/pytorch/glm/glm_tokenize.py
```
## 应用场景
### 算法类别
`自然语言处理`
### 热点应用行业
`nlp,智能聊天助手,科研`
## 源码仓库及问题反馈
...
...
doc/GLM.png
0 → 100644
View file @
7b7c64c5
261 KB
doc/transformers.jpg
0 → 100644
View file @
7b7c64c5
32.7 KB
model.properties
View file @
7b7c64c5
# 模型唯一标识
modelCode
=
348
# 模型名称
modelName
=
GLM130B_FT
# 模型描述
modelDescription
=
GLM-130B是一个开放的双语(中英)双向密集模型,具有130亿个参数,使用
[
通用语言模型(GLM)算法进行预训练。
modelDescription
=
GLM-130B是一个开放的双语(中英)双向密集模型,具有130亿个参数,使用通用语言模型(GLM)算法进行预训练。
# 应用场景
appScenario
=
大模型基座
appScenario
=
推理,NLP,大模型基座,智能聊天助手
# 框架类型
frameType
=
fastertransformer
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}