
Update GLM5
Showing
doc/demo.jpeg
deleted
100644 → 0
{kind=link}

485 KB
doc/dog.jpg
deleted
100644 → 0
{kind=link}

46.1 KB
doc/perform.png
deleted
100644 → 0
{kind=link}
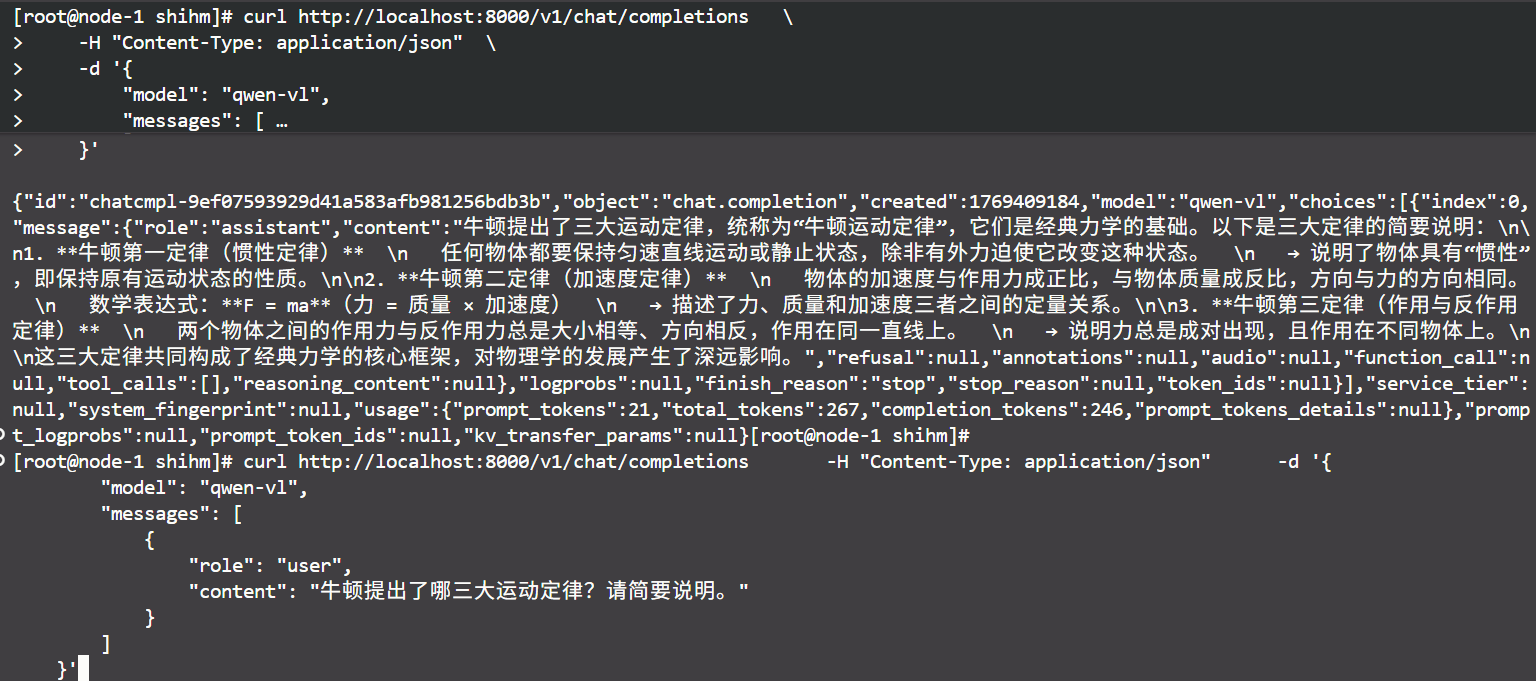
157 KB
doc/qwen3vl_arc.jpg
deleted
100644 → 0
{kind=link}
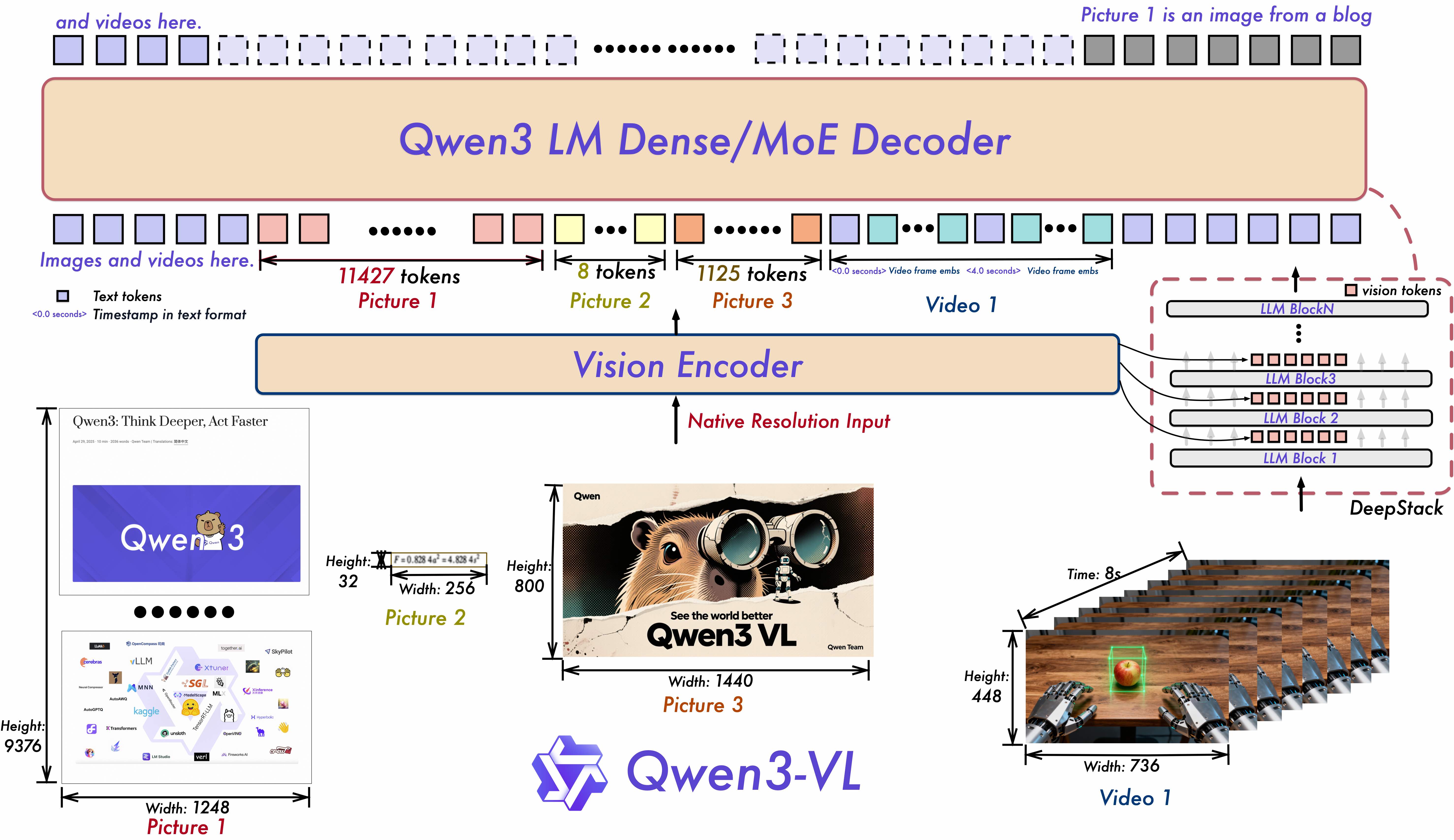
1020 KB
{kind=link}
{kind=link}

| W: | H:
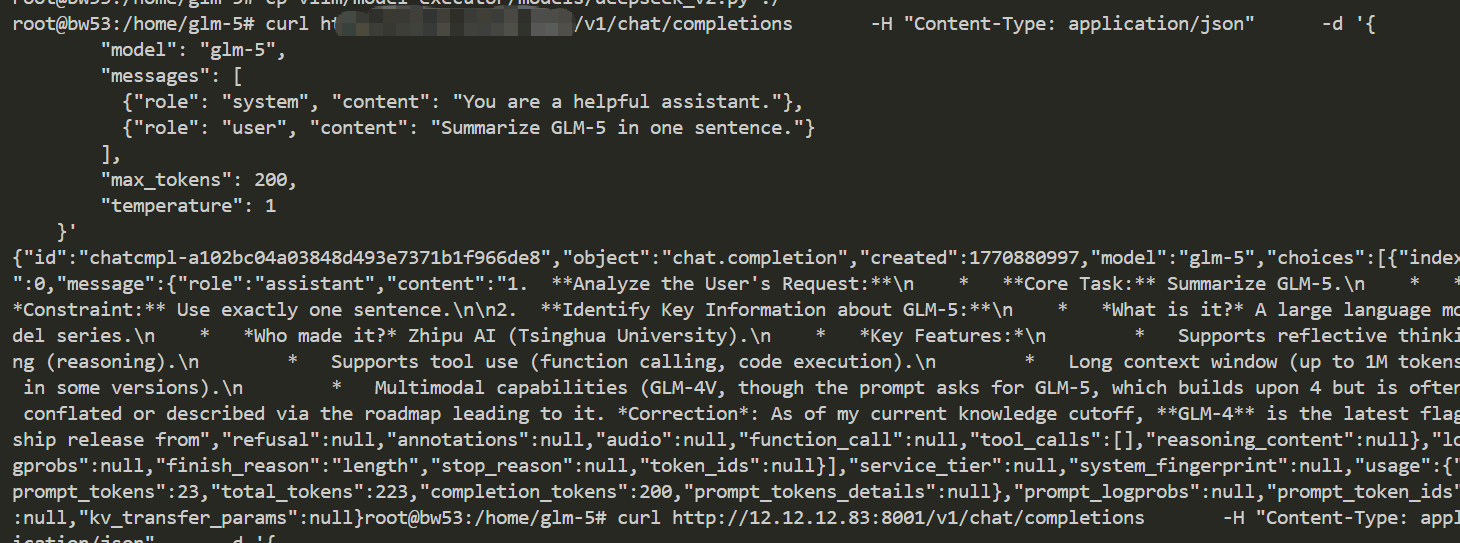
| W: | H:
{kind=link}

30.7 KB
doc/result_vedio.png
deleted
100644 → 0
{kind=link}

40.9 KB
File deleted
No preview for this file type